 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Domain-Specific ASR with LLM-Generated Contextual Descriptions
Paper and Code
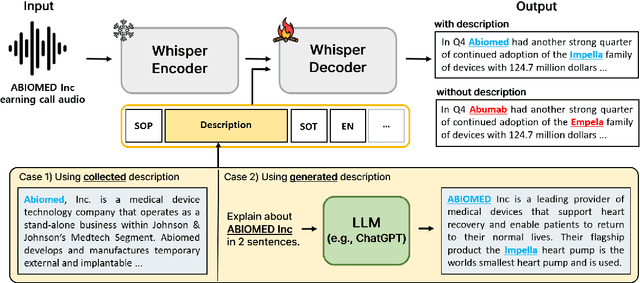
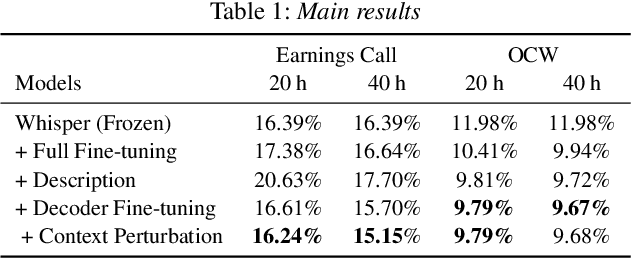


End-to-end automatic speech recognition (E2E ASR) systems have significantly improved speech recognition through training on extensive datasets. Despite these advancements, they still struggle to accurately recognize domain specific words, such as proper nouns and technical terminologies. To address this problem, we propose a method to utilize the state-of-the-art Whisper without modifying its architecture, preserving its generalization performance while enabling it to leverage descriptions effectively. Moreover, we propose two additional training techniques to improve the domain specific ASR: decoder fine-tuning, and context perturbation. We also propose a method to use a Large Language Model (LLM) to generate descriptions with simple metadata, when descriptions are unavailable. Our experiments demonstrate that proposed methods notably enhance domain-specific ASR accuracy on real-life datasets, with LLM-generated descriptions outperforming human-crafted ones in effectiveness.