 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaPairAudioBench: Paralinguistic Pairwise Audio Benchmark for LALM-as-a-Judge
Jun 23, 2026Large Audio-Language Models (LALMs) have been widely used as judge models for the automatic evaluation of generated speech. However, prior approaches predominantly focus on holistic naturalness, leaving fine-grained paralinguistic distinctions underexplored. We introduce ParaPairAudioBench, a pairwise benchmark of 5,175 audio pairs across five paralinguistic dimensions: Style, Rate, Emphasis, Age, and Gender. Our experiments show that current LALM judges still lag behind human judgments by 32%p on average and exhibit severe calibration failures, particularly in Tie cases where the correct decision is to abstain. To further analyze lexical versus acoustic reliance, the benchmark includes both same-transcript and cross-transcript conditions. ParaPairAudioBench enables multi-dimensional, calibration-aware assessment of the reliability of LALM-as-a-Judge for paralinguistic speech evaluation.
LegalMidm: Use-Case-Driven Legal Domain Specialization for Korean Large Language Model
Apr 28, 2026In recent years, the rapid proliferation of open-source large language models (LLMs) has spurred efforts to turn general-purpose models into domain specialists. However, many domain-specialized LLMs are developed using datasets and training protocols that are not aligned with the nuanced requirements of real-world applications. In the legal domain, where precision and reliability are essential, this lack of consideration limits practical utility. In this study, we propose a systematic training framework grounded in the practical needs of the legal domain, with a focus on Korean law. We introduce LegalMidm, a Korean legal-domain LLM, and present a methodology for constructing high-quality, use-case-driven legal datasets and optimized training pipelines. Our approach emphasizes collaboration with legal professionals and rigorous data curation to ensure relevance and factual accuracy, and demonstrates effectiveness in key legal tasks.
Cross-View Completion Models are Zero-shot Correspondence Estimators
Dec 12, 2024In this work, we explore new perspectives on cross-view completion learning by drawing an analogy to self-supervised correspondence learning. Through our analysis, we demonstrate that the cross-attention map within cross-view completion models captures correspondence more effectively than other correlations derived from encoder or decoder features. We verify the effectiveness of the cross-attention map by evaluating on both zero-shot matching and learning-based geometric matching and multi-frame depth estimation. Project page is available at https://cvlab-kaist.github.io/ZeroCo/.
Analysis of Multi-Source Language Training in Cross-Lingual Transfer
Feb 21, 2024



The successful adaptation of multilingual language models (LMs) to a specific language-task pair critically depends on the availability of data tailored for that condition. While cross-lingual transfer (XLT) methods have contributed to addressing this data scarcity problem, there still exists ongoing debate about the mechanisms behind their effectiveness. In this work, we focus on one of promising assumptions about inner workings of XLT, that it encourages multilingual LMs to place greater emphasis on language-agnostic or task-specific features. We test this hypothesis by examining how the patterns of XLT change with a varying number of source languages involved in the process. Our experimental findings show that the use of multiple source languages in XLT-a technique we term Multi-Source Language Training (MSLT)-leads to increased mingling of embedding spaces for different languages, supporting the claim that XLT benefits from making use of language-independent information. On the other hand, we discover that using an arbitrary combination of source languages does not always guarantee better performance. We suggest simple heuristics for identifying effective language combinations for MSLT and empirically prove its effectiveness.
X-SNS: Cross-Lingual Transfer Prediction through Sub-Network Similarity
Oct 26, 2023



Cross-lingual transfer (XLT) is an emergent ability of multilingual language models that preserves their performance on a task to a significant extent when evaluated in languages that were not included in the fine-tuning process. While English, due to its widespread usage, is typically regarded as the primary language for model adaption in various tasks, recent studies have revealed that the efficacy of XLT can be amplified by selecting the most appropriate source languages based on specific conditions. In this work, we propose the utilization of sub-network similarity between two languages as a proxy for predicting the compatibility of the languages in the context of XLT. Our approach is model-oriented, better reflecting the inner workings of foundation models. In addition, it requires only a moderate amount of raw text from candidate languages, distinguishing it from the majority of previous methods that rely on external resources. In experiments, we demonstrate that our method is more effective than baselines across diverse tasks. Specifically, it shows proficiency in ranking candidates for zero-shot XLT, achieving an improvement of 4.6% on average in terms of NDCG@3. We also provide extensive analyses that confirm the utility of sub-networks for XLT prediction.
Spine-like Joint Link Mechanism to Design Wearable Assistive Devices with Comfort and Support
Nov 27, 2021
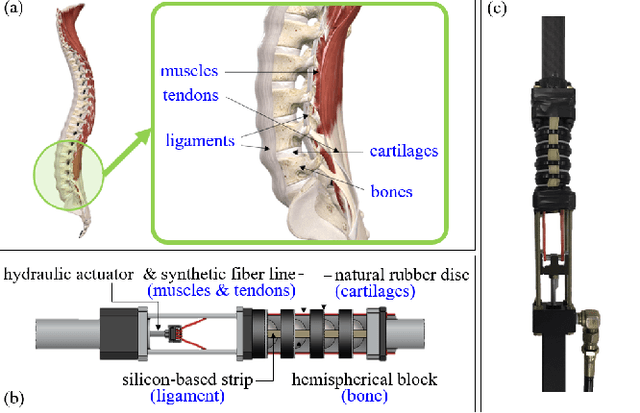
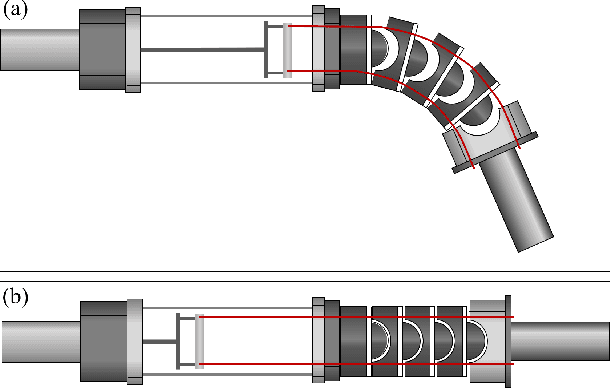

When we develop wearable assistive devices comfort and support are two main issues needed to be considered. In conventional design approaches, the degree of freedom of wearer's joint movement tends to be oversimplified. Accordingly, the wearer's motion becomes restrained and bone/ligament injuries might occur in case of unexpected fall. To mitigate those issues, this letter proposes a novel joint link mechanism inspired by a human spine structure as well as functionalities. The key feature of the proposed spine-like joint link mechanism is that hemispherical blocks are concatenated via flexible synthetic fiber lines so that their concatenation stiffness can be adjusted according to a tensile force. This feature has a great potentiality for designing a wearable assistive devices that can support aged people's sit-to-stand action or augment a spinal motion by regulating the concatenation stiffness. In addition, the concatenated hemispherical blocks enables the wearer to move his/her joint with the full degree of freedom, which in turn, increases wearer's mobility and prevents joint misalignment. The experimental results with a testbed and a pilot wearer substantiated that the spine-like joint link mechanism can serve as a key component to design the wearable assistive devices for better mobility and safety.