 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovert Routing with DSSS Signaling Against Cycle Detectors
Feb 19, 2026This paper investigates covert multi-hop communication in wireless networks where an adversary employs a cyclostationary (cycle) detector to reveal hidden transmissions. The covert route employs direct sequence spread spectrum (DSSS) signaling to ensure either maximum end-to-end covertness maximization or minimum latency minimization-under quality-of-service (QoS) and link budget constraints. Optimal bandwidth, transmit power, and spreading gain for each hop jointly satisfy reliability and either rate or covertness requirements. We show the equivalence between the covertness and the detection SNR gain-based widest-path formulations, and, hence, enabling efficient route computation. Numerical simulations in a realistic 3D environment illustrate that (i) end-to-end latency increases exponentially with the covertness requirement, (ii) the end-to-end latency increase is super-linear with the packet size M, and (iii) cycle and energy detectors impose different latency behavior as a function of the message length and the covertness requirement. The proposed framework provides important insights into resource allocation and routing design for covert networks against advanced detection adversaries.
Memorization or Reasoning? Exploring the Idiom Understanding of LLMs
May 22, 2025
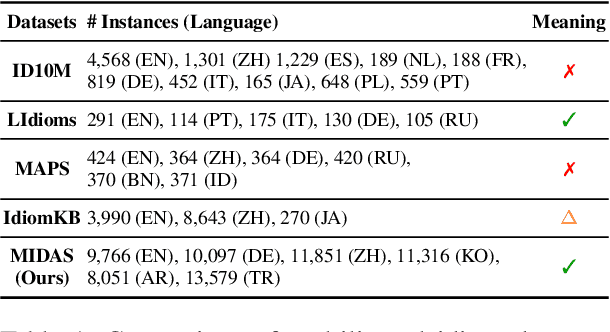


Idioms have long posed a challenge due to their unique linguistic properties, which set them apart from other common expressions. While recent studies have leveraged large language models (LLMs) to handle idioms across various tasks, e.g., idiom-containing sentence generation and idiomatic machine translation, little is known about the underlying mechanisms of idiom processing in LLMs, particularly in multilingual settings. To this end, we introduce MIDAS, a new large-scale dataset of idioms in six languages, each paired with its corresponding meaning. Leveraging this resource, we conduct a comprehensive evaluation of LLMs' idiom processing ability, identifying key factors that influence their performance. Our findings suggest that LLMs rely not only on memorization, but also adopt a hybrid approach that integrates contextual cues and reasoning, especially when processing compositional idioms. This implies that idiom understanding in LLMs emerges from an interplay between internal knowledge retrieval and reasoning-based inference.
CookingSense: A Culinary Knowledgebase with Multidisciplinary Assertions
May 01, 2024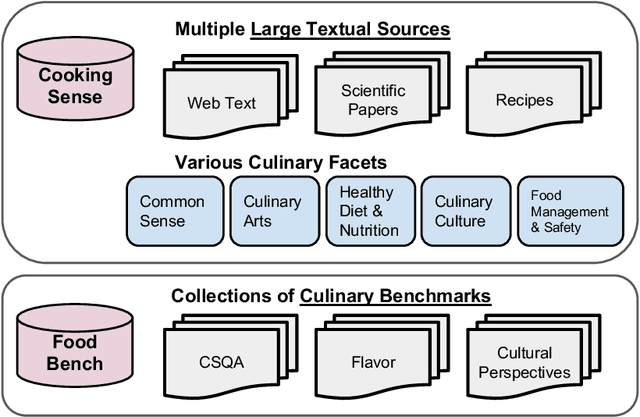

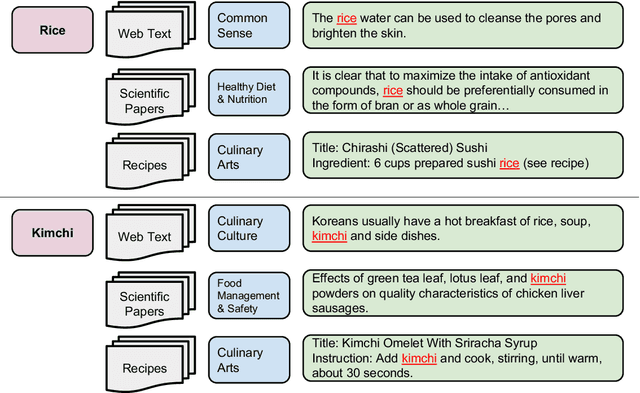
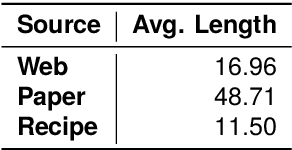
This paper introduces CookingSense, a descriptive collection of knowledge assertions in the culinary domain extracted from various sources, including web data, scientific papers, and recipes, from which knowledge covering a broad range of aspects is acquired. CookingSense is constructed through a series of dictionary-based filtering and language model-based semantic filtering techniques, which results in a rich knowledgebase of multidisciplinary food-related assertions. Additionally, we present FoodBench, a novel benchmark to evaluate culinary decision support systems. From evaluations with FoodBench, we empirically prove that CookingSense improves the performance of retrieval augmented language models. We also validate the quality and variety of assertions in CookingSense through qualitative analysis.
Analysis of Multi-Source Language Training in Cross-Lingual Transfer
Feb 21, 2024



The successful adaptation of multilingual language models (LMs) to a specific language-task pair critically depends on the availability of data tailored for that condition. While cross-lingual transfer (XLT) methods have contributed to addressing this data scarcity problem, there still exists ongoing debate about the mechanisms behind their effectiveness. In this work, we focus on one of promising assumptions about inner workings of XLT, that it encourages multilingual LMs to place greater emphasis on language-agnostic or task-specific features. We test this hypothesis by examining how the patterns of XLT change with a varying number of source languages involved in the process. Our experimental findings show that the use of multiple source languages in XLT-a technique we term Multi-Source Language Training (MSLT)-leads to increased mingling of embedding spaces for different languages, supporting the claim that XLT benefits from making use of language-independent information. On the other hand, we discover that using an arbitrary combination of source languages does not always guarantee better performance. We suggest simple heuristics for identifying effective language combinations for MSLT and empirically prove its effectiveness.
RecipeMind: Guiding Ingredient Choices from Food Pairing to Recipe Completion using Cascaded Set Transformer
Oct 14, 2022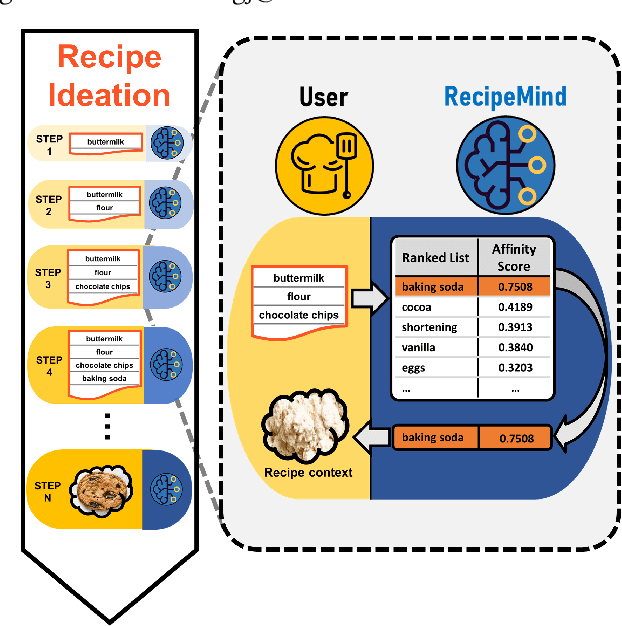
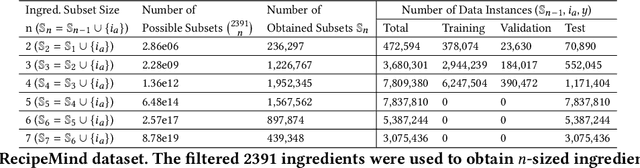
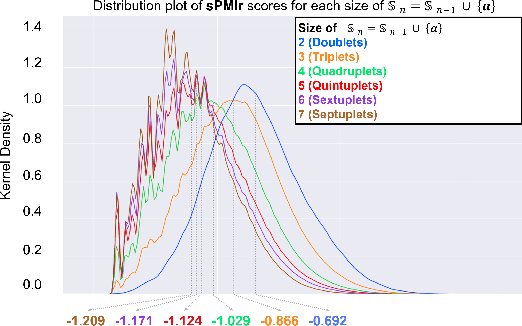
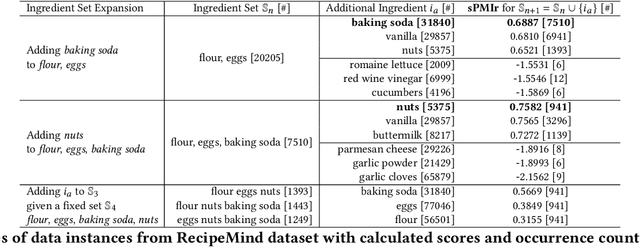
We propose a computational approach for recipe ideation, a downstream task that helps users select and gather ingredients for creating dishes. To perform this task, we developed RecipeMind, a food affinity score prediction model that quantifies the suitability of adding an ingredient to set of other ingredients. We constructed a large-scale dataset containing ingredient co-occurrence based scores to train and evaluate RecipeMind on food affinity score prediction. Deployed in recipe ideation, RecipeMind helps the user expand an initial set of ingredients by suggesting additional ingredients. Experiments and qualitative analysis show RecipeMind's potential in fulfilling its assistive role in cuisine domain.
Are Pre-trained Language Models Aware of Phrases? Simple but Strong Baselines for Grammar Induction
Jan 30, 2020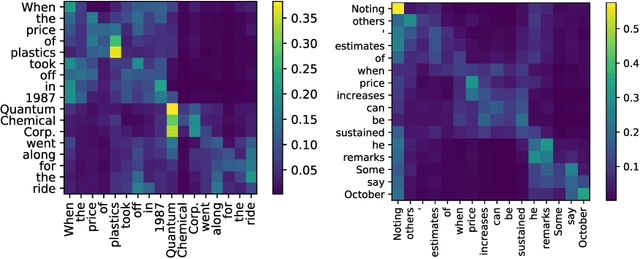
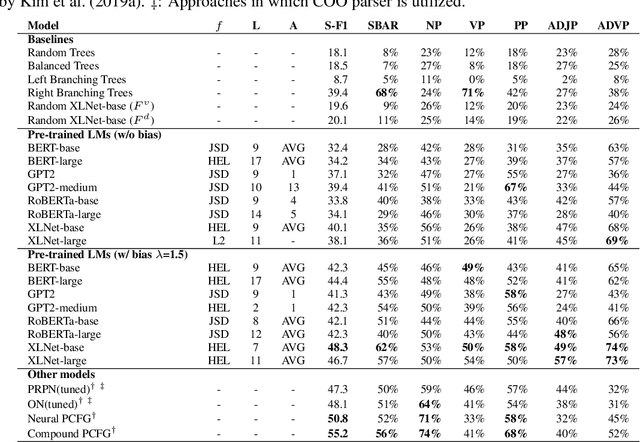
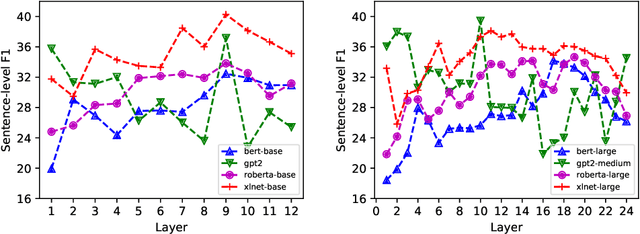
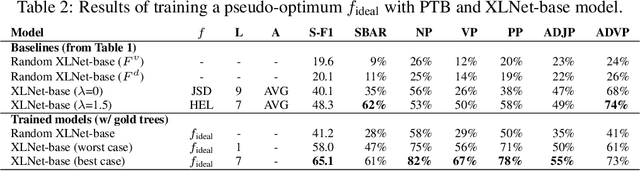
With the recent success and popularity of pre-trained language models (LMs) in natural language processing, there has been a rise in efforts to understand their inner workings. In line with such interest, we propose a novel method that assists us in investigating the extent to which pre-trained LMs capture the syntactic notion of constituency. Our method provides an effective way of extracting constituency trees from the pre-trained LMs without training. In addition, we report intriguing findings in the induced trees, including the fact that pre-trained LMs outperform other approaches in correctly demarcating adverb phrases in sentences.
A Cross-Sentence Latent Variable Model for Semi-Supervised Text Sequence Matching
Jun 04, 2019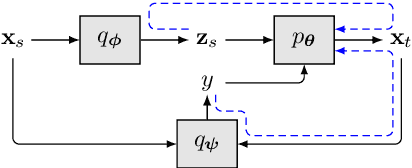
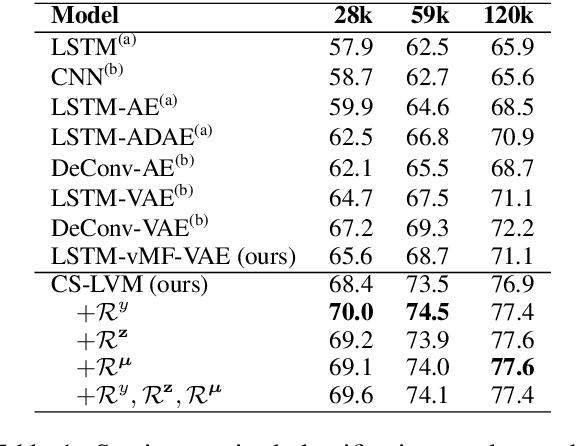
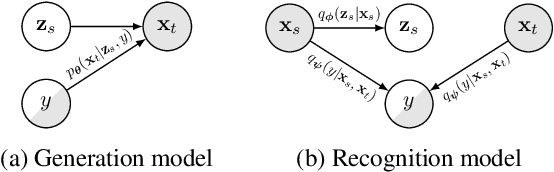
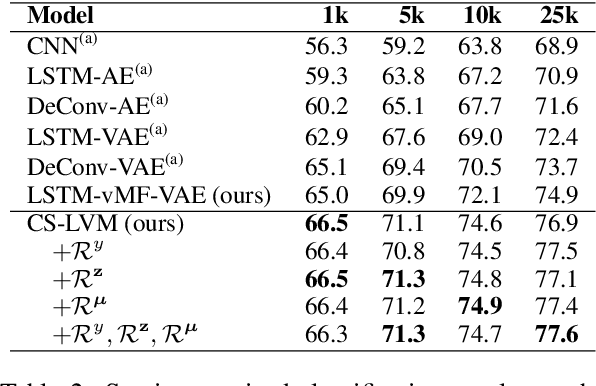
We present a latent variable model for predicting the relationship between a pair of text sequences. Unlike previous auto-encoding--based approaches that consider each sequence separately, our proposed framework utilizes both sequences within a single model by generating a sequence that has a given relationship with a source sequence. We further extend the cross-sentence generating framework to facilitate semi-supervised training. We also define novel semantic constraints that lead the decoder network to generate semantically plausible and diverse sequences. We demonstrate the effectiveness of the proposed model from quantitative and qualitative experiments, while achieving state-of-the-art results on semi-supervised natural language inference and paraphrase identification.
SNU_IDS at SemEval-2019 Task 3: Addressing Training-Test Class Distribution Mismatch in Conversational Classification
Apr 01, 2019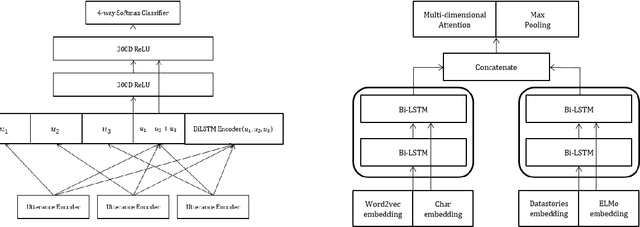
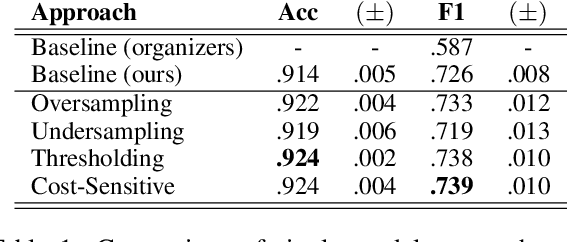
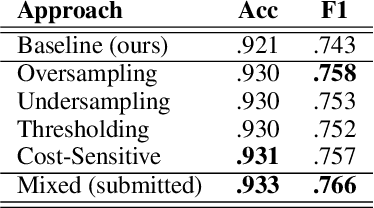
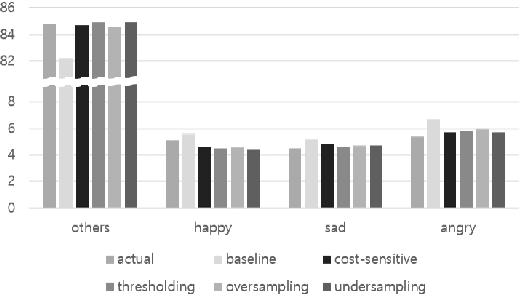
We present several techniques to tackle the mismatch in class distributions between training and test data in the Contextual Emotion Detection task of SemEval 2019, by extending the existing methods for class imbalance problem. Reducing the distance between the distribution of prediction and ground truth, they consistently show positive effects on the performance. Also we propose a novel neural architecture which utilizes representation of overall context as well as of each utterance. The combination of the methods and the models achieved micro F1 score of about 0.766 on the final evaluation.
Dynamic Compositionality in Recursive Neural Networks with Structure-aware Tag Representations
Sep 07, 2018
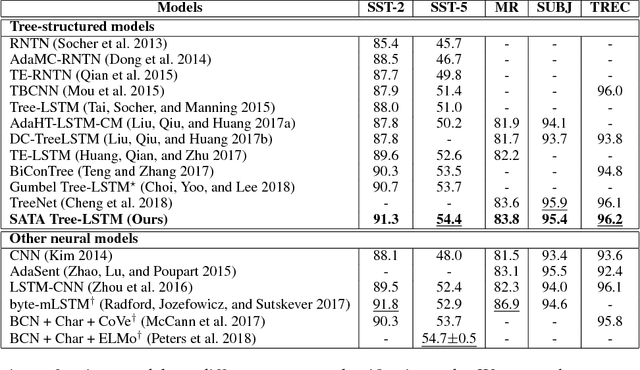
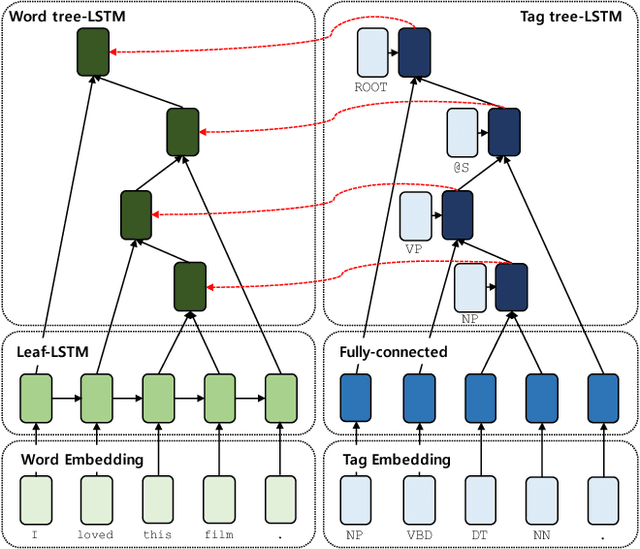
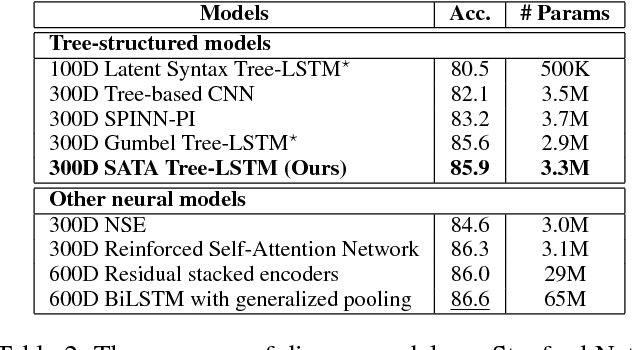
Most existing recursive neural network (RvNN) architectures utilize only the structure of parse trees, ignoring syntactic tags which are provided as by-products of parsing. We present a novel RvNN architecture that can provide dynamic compositionality by considering comprehensive syntactic information derived from both the structure and linguistic tags. Specifically, we introduce a structure-aware tag representation constructed by a separate tag-level tree-LSTM. With this, we can control the composition function of the existing word-level tree-LSTM by augmenting the representation as a supplementary input to the gate functions of the tree-LSTM. We show that models built upon the proposed architecture obtain superior performance on several sentence-level tasks such as sentiment analysis and natural language inference when compared against previous tree-structured models and other sophisticated neural models. In particular, our models achieve new state-of-the-art results on Stanford Sentiment Treebank, Movie Review, and Text Retrieval Conference datasets.
Cell-aware Stacked LSTMs for Modeling Sentences
Sep 07, 2018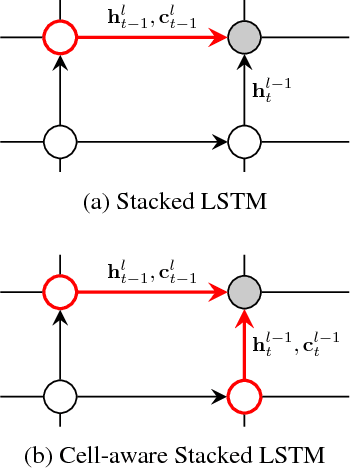


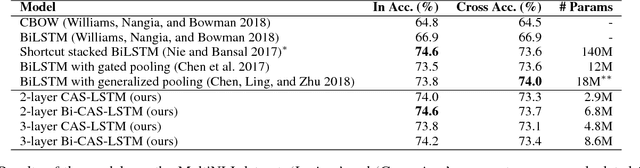
We propose a method of stacking multiple long short-term memory (LSTM) layers for modeling sentences. In contrast to the conventional stacked LSTMs where only hidden states are fed as input to the next layer, our architecture accepts both hidden and memory cell states of the preceding layer and fuses information from the left and the lower context using the soft gating mechanism of LSTMs. Thus the proposed stacked LSTM architecture modulates the amount of information to be delivered not only in horizontal recurrence but also in vertical connections, from which useful features extracted from lower layers are effectively conveyed to upper layers. We dub this architecture Cell-aware Stacked LSTM (CAS-LSTM) and show from experiments that our models achieve state-of-the-art results on benchmark datasets for natural language inference, paraphrase detection, and sentiment classification.