 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Learning with Noisy Proxy Covariates: Generalization Bounds and Distribution Regression
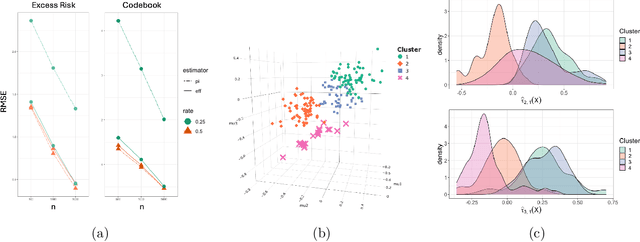
May 30, 2026In many modern machine learning pipelines, abundant pretrained representations serve as noisy proxy covariates, while task-specific labels remain scarce. We study semi-supervised regression in this setting, and propose a simple two stage estimator that learns kernel eigenfeatures from all proxy covariates and fits a ridge predictor on labeled data. We derive finite sample bounds showing that fast labeled sample rates are recovered when proxy perturbation is controlled and unlabeled proxy covariates are sufficiently abundant. We also show that distribution regression is a direct special case, with analogous guarantees when the finite bag size is large enough. Experiments show consistent gains over supervised and semi-supervised baselines, especially in low label regimes.
Chunk Knowledge Generation Model for Enhanced Information Retrieval: A Multi-task Learning Approach
Sep 19, 2025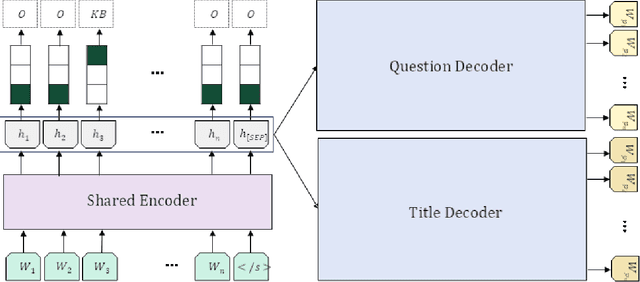



Traditional query expansion techniques for addressing vocabulary mismatch problems in information retrieval are context-sensitive and may lead to performance degradation. As an alternative, document expansion research has gained attention, but existing methods such as Doc2Query have limitations including excessive preprocessing costs, increased index size, and reliability issues with generated content. To mitigate these problems and seek more structured and efficient alternatives, this study proposes a method that divides documents into chunk units and generates textual data for each chunk to simultaneously improve retrieval efficiency and accuracy. The proposed "Chunk Knowledge Generation Model" adopts a T5-based multi-task learning structure that simultaneously generates titles and candidate questions from each document chunk while extracting keywords from user queries. This approach maximizes computational efficiency by generating and extracting three types of semantic information in parallel through a single encoding and two decoding processes. The generated data is utilized as additional information in the retrieval system. GPT-based evaluation on 305 query-document pairs showed that retrieval using the proposed model achieved 95.41% accuracy at Top@10, demonstrating superior performance compared to document chunk-level retrieval. This study contributes by proposing an approach that simultaneously generates titles and candidate questions from document chunks for application in retrieval pipelines, and provides empirical evidence applicable to large-scale information retrieval systems by demonstrating improved retrieval accuracy through qualitative evaluation.
Memorization or Reasoning? Exploring the Idiom Understanding of LLMs
May 22, 2025
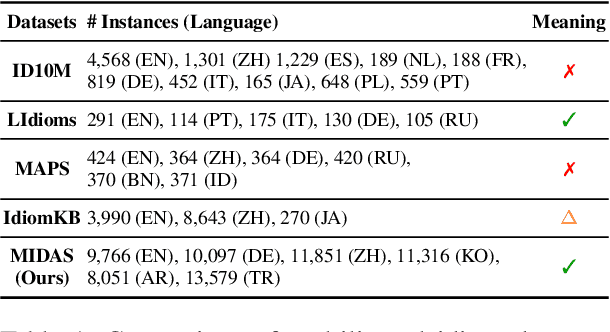


Idioms have long posed a challenge due to their unique linguistic properties, which set them apart from other common expressions. While recent studies have leveraged large language models (LLMs) to handle idioms across various tasks, e.g., idiom-containing sentence generation and idiomatic machine translation, little is known about the underlying mechanisms of idiom processing in LLMs, particularly in multilingual settings. To this end, we introduce MIDAS, a new large-scale dataset of idioms in six languages, each paired with its corresponding meaning. Leveraging this resource, we conduct a comprehensive evaluation of LLMs' idiom processing ability, identifying key factors that influence their performance. Our findings suggest that LLMs rely not only on memorization, but also adopt a hybrid approach that integrates contextual cues and reasoning, especially when processing compositional idioms. This implies that idiom understanding in LLMs emerges from an interplay between internal knowledge retrieval and reasoning-based inference.
PINT: Physics-Informed Neural Time Series Models with Applications to Long-term Inference on WeatherBench 2m-Temperature Data
Feb 06, 2025



This paper introduces PINT (Physics-Informed Neural Time Series Models), a framework that integrates physical constraints into neural time series models to improve their ability to capture complex dynamics. We apply PINT to the ERA5 WeatherBench dataset, focusing on long-term forecasting of 2m-temperature data. PINT incorporates the Simple Harmonic Oscillator Equation as a physics-informed prior, embedding its periodic dynamics into RNN, LSTM, and GRU architectures. This equation's analytical solutions (sine and cosine functions) facilitate rigorous evaluation of the benefits of incorporating physics-informed constraints. By benchmarking against a linear regression baseline derived from its exact solutions, we quantify the impact of embedding physical principles in data-driven models. Unlike traditional time series models that rely on future observations, PINT is designed for practical forecasting. Using only the first 90 days of observed data, it iteratively predicts the next two years, addressing challenges posed by limited real-time updates. Experiments on the WeatherBench dataset demonstrate PINT's ability to generalize, capture periodic trends, and align with physical principles. This study highlights the potential of physics-informed neural models in bridging machine learning and interpretable climate applications. Our models and datasets are publicly available on GitHub: https://github.com/KV-Park.
Hierarchical and Density-based Causal Clustering
Nov 02, 2024



Understanding treatment effect heterogeneity is vital for scientific and policy research. However, identifying and evaluating heterogeneous treatment effects pose significant challenges due to the typically unknown subgroup structure. Recently, a novel approach, causal k-means clustering, has emerged to assess heterogeneity of treatment effect by applying the k-means algorithm to unknown counterfactual regression functions. In this paper, we expand upon this framework by integrating hierarchical and density-based clustering algorithms. We propose plug-in estimators that are simple and readily implementable using off-the-shelf algorithms. Unlike k-means clustering, which requires the margin condition, our proposed estimators do not rely on strong structural assumptions on the outcome process. We go on to study their rate of convergence, and show that under the minimal regularity conditions, the additional cost of causal clustering is essentially the estimation error of the outcome regression functions. Our findings significantly extend the capabilities of the causal clustering framework, thereby contributing to the progression of methodologies for identifying homogeneous subgroups in treatment response, consequently facilitating more nuanced and targeted interventions. The proposed methods also open up new avenues for clustering with generic pseudo-outcomes. We explore finite sample properties via simulation, and illustrate the proposed methods in voting and employment projection datasets.
Strategic Data Ordering: Enhancing Large Language Model Performance through Curriculum Learning
May 13, 2024
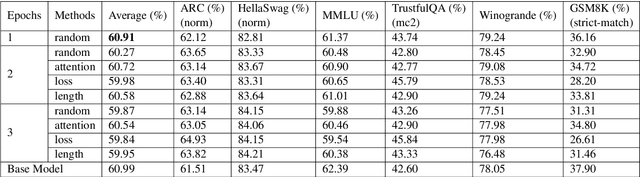

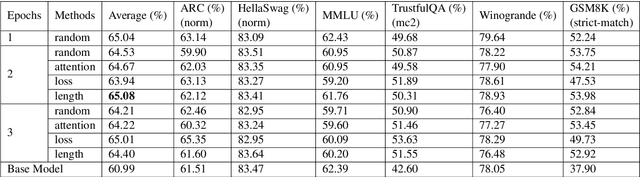
The rapid advancement of Large Language Models (LLMs) has improved text understanding and generation but poses challenges in computational resources. This study proposes a curriculum learning-inspired, data-centric training strategy that begins with simpler tasks and progresses to more complex ones, using criteria such as prompt length, attention scores, and loss values to structure the training data. Experiments with Mistral-7B (Jiang et al., 2023) and Gemma-7B (Team et al., 2024) models demonstrate that curriculum learning slightly improves performance compared to traditional random data shuffling. Notably, we observed that sorting data based on our proposed attention criteria generally led to better performance. This approach offers a sustainable method to enhance LLM performance without increasing model size or dataset volume, addressing scalability challenges in LLM training.
One vs. Many: Comprehending Accurate Information from Multiple Erroneous and Inconsistent AI Generations
May 09, 2024
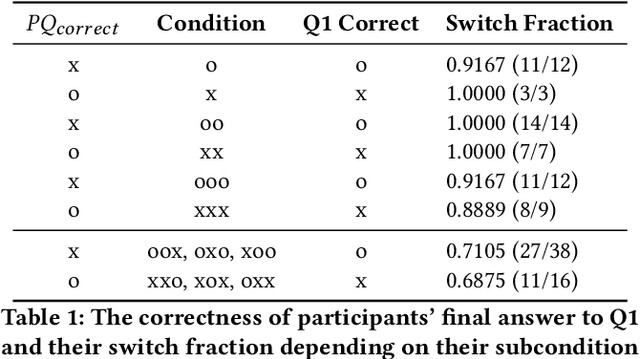
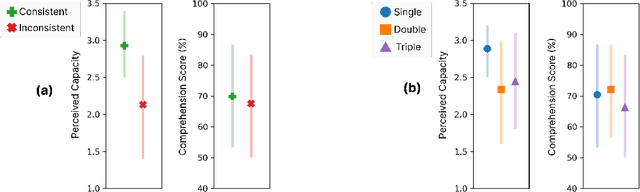
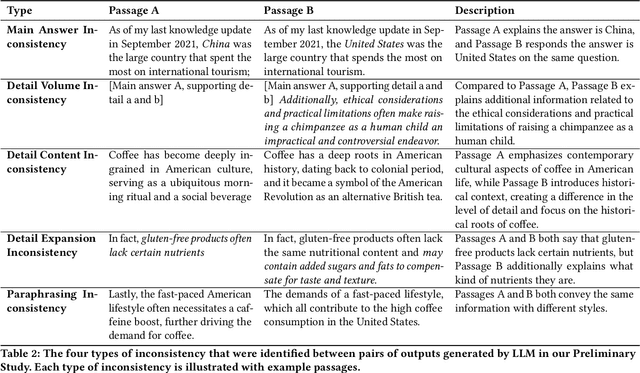
As Large Language Models (LLMs) are nondeterministic, the same input can generate different outputs, some of which may be incorrect or hallucinated. If run again, the LLM may correct itself and produce the correct answer. Unfortunately, most LLM-powered systems resort to single results which, correct or not, users accept. Having the LLM produce multiple outputs may help identify disagreements or alternatives. However, it is not obvious how the user will interpret conflicts or inconsistencies. To this end, we investigate how users perceive the AI model and comprehend the generated information when they receive multiple, potentially inconsistent, outputs. Through a preliminary study, we identified five types of output inconsistencies. Based on these categories, we conducted a study (N=252) in which participants were given one or more LLM-generated passages to an information-seeking question. We found that inconsistency within multiple LLM-generated outputs lowered the participants' perceived AI capacity, while also increasing their comprehension of the given information. Specifically, we observed that this positive effect of inconsistencies was most significant for participants who read two passages, compared to those who read three. Based on these findings, we present design implications that, instead of regarding LLM output inconsistencies as a drawback, we can reveal the potential inconsistencies to transparently indicate the limitations of these models and promote critical LLM usage.
Causal K-Means Clustering
May 05, 2024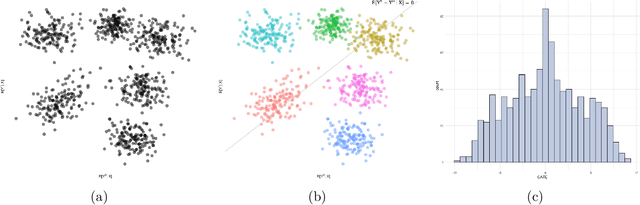
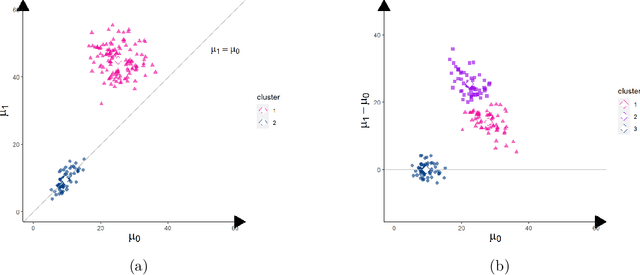
Causal effects are often characterized with population summaries. These might provide an incomplete picture when there are heterogeneous treatment effects across subgroups. Since the subgroup structure is typically unknown, it is more challenging to identify and evaluate subgroup effects than population effects. We propose a new solution to this problem: Causal k-Means Clustering, which harnesses the widely-used k-means clustering algorithm to uncover the unknown subgroup structure. Our problem differs significantly from the conventional clustering setup since the variables to be clustered are unknown counterfactual functions. We present a plug-in estimator which is simple and readily implementable using off-the-shelf algorithms, and study its rate of convergence. We also develop a new bias-corrected estimator based on nonparametric efficiency theory and double machine learning, and show that this estimator achieves fast root-n rates and asymptotic normality in large nonparametric models. Our proposed methods are especially useful for modern outcome-wide studies with multiple treatment levels. Further, our framework is extensible to clustering with generic pseudo-outcomes, such as partially observed outcomes or otherwise unknown functions. Finally, we explore finite sample properties via simulation, and illustrate the proposed methods in a study of treatment programs for adolescent substance abuse.
Semi-Supervised Domain Adaptation for Wildfire Detection
Apr 02, 2024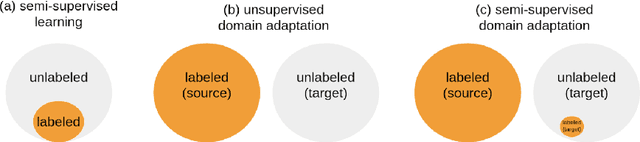


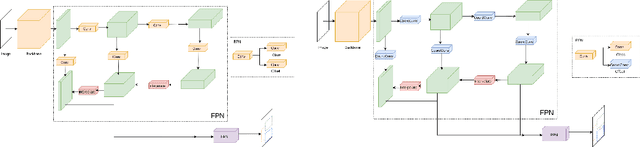
Recently, both the frequency and intensity of wildfires have increased worldwide, primarily due to climate change. In this paper, we propose a novel protocol for wildfire detection, leveraging semi-supervised Domain Adaptation for object detection, accompanied by a corresponding dataset designed for use by both academics and industries. Our dataset encompasses 30 times more diverse labeled scenes for the current largest benchmark wildfire dataset, HPWREN, and introduces a new labeling policy for wildfire detection. Inspired by CoordConv, we propose a robust baseline, Location-Aware Object Detection for Semi-Supervised Domain Adaptation (LADA), utilizing a teacher-student based framework capable of extracting translational variance features characteristic of wildfires. With only using 1% target domain labeled data, our framework significantly outperforms our source-only baseline by a notable margin of 3.8% in mean Average Precision on the HPWREN wildfire dataset. Our dataset is available at https://github.com/BloomBerry/LADA.
Topological Learning for Motion Data via Mixed Coordinates
Oct 30, 2023



Topology can extract the structural information in a dataset efficiently. In this paper, we attempt to incorporate topological information into a multiple output Gaussian process model for transfer learning purposes. To achieve this goal, we extend the framework of circular coordinates into a novel framework of mixed valued coordinates to take linear trends in the time series into consideration. One of the major challenges to learn from multiple time series effectively via a multiple output Gaussian process model is constructing a functional kernel. We propose to use topologically induced clustering to construct a cluster based kernel in a multiple output Gaussian process model. This kernel not only incorporates the topological structural information, but also allows us to put forward a unified framework using topological information in time and motion series.
* 7 pages, 4 figures