 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical and Density-based Causal Clustering
Nov 02, 2024



Understanding treatment effect heterogeneity is vital for scientific and policy research. However, identifying and evaluating heterogeneous treatment effects pose significant challenges due to the typically unknown subgroup structure. Recently, a novel approach, causal k-means clustering, has emerged to assess heterogeneity of treatment effect by applying the k-means algorithm to unknown counterfactual regression functions. In this paper, we expand upon this framework by integrating hierarchical and density-based clustering algorithms. We propose plug-in estimators that are simple and readily implementable using off-the-shelf algorithms. Unlike k-means clustering, which requires the margin condition, our proposed estimators do not rely on strong structural assumptions on the outcome process. We go on to study their rate of convergence, and show that under the minimal regularity conditions, the additional cost of causal clustering is essentially the estimation error of the outcome regression functions. Our findings significantly extend the capabilities of the causal clustering framework, thereby contributing to the progression of methodologies for identifying homogeneous subgroups in treatment response, consequently facilitating more nuanced and targeted interventions. The proposed methods also open up new avenues for clustering with generic pseudo-outcomes. We explore finite sample properties via simulation, and illustrate the proposed methods in voting and employment projection datasets.
Iterative Markov Chain Monte Carlo Computation of Reference Priors and Minimax Risk
Jan 10, 2013

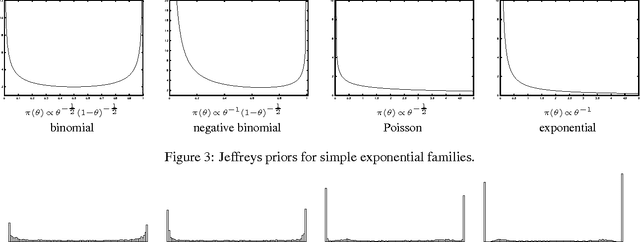

We present an iterative Markov chainMonte Carlo algorithm for computingreference priors and minimax risk forgeneral parametric families. Ourapproach uses MCMC techniques based onthe Blahut-Arimoto algorithm forcomputing channel capacity ininformation theory. We give astatistical analysis of the algorithm,bounding the number of samples requiredfor the stochastic algorithm to closelyapproximate the deterministic algorithmin each iteration. Simulations arepresented for several examples fromexponential families. Although we focuson applications to reference priors andminimax risk, the methods and analysiswe develop are applicable to a muchbroader class of optimization problemsand iterative algorithms.