 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Data Ordering: Enhancing Large Language Model Performance through Curriculum Learning
Paper and Code
May 13, 2024
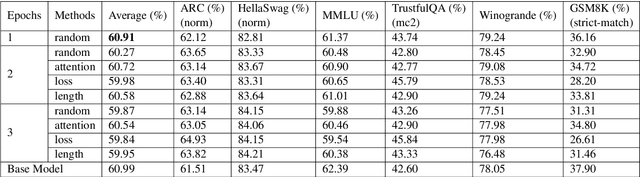

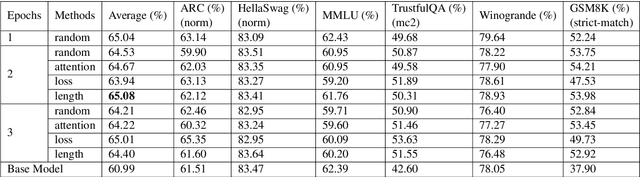
The rapid advancement of Large Language Models (LLMs) has improved text understanding and generation but poses challenges in computational resources. This study proposes a curriculum learning-inspired, data-centric training strategy that begins with simpler tasks and progresses to more complex ones, using criteria such as prompt length, attention scores, and loss values to structure the training data. Experiments with Mistral-7B (Jiang et al., 2023) and Gemma-7B (Team et al., 2024) models demonstrate that curriculum learning slightly improves performance compared to traditional random data shuffling. Notably, we observed that sorting data based on our proposed attention criteria generally led to better performance. This approach offers a sustainable method to enhance LLM performance without increasing model size or dataset volume, addressing scalability challenges in LLM training.