 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB-RIGHT: Benchmark Re-evaluation for Integrity in Generalized Human-Object Interaction Testing
Jan 28, 2025Human-object interaction (HOI) is an essential problem in artificial intelligence (AI) which aims to understand the visual world that involves complex relationships between humans and objects. However, current benchmarks such as HICO-DET face the following limitations: (1) severe class imbalance and (2) varying number of train and test sets for certain classes. These issues can potentially lead to either inflation or deflation of model performance during evaluation, ultimately undermining the reliability of evaluation scores. In this paper, we propose a systematic approach to develop a new class-balanced dataset, Benchmark Re-evaluation for Integrity in Generalized Human-object Interaction Testing (B-RIGHT), that addresses these imbalanced problems. B-RIGHT achieves class balance by leveraging balancing algorithm and automated generation-and-filtering processes, ensuring an equal number of instances for each HOI class. Furthermore, we design a balanced zero-shot test set to systematically evaluate models on unseen scenario. Re-evaluating existing models using B-RIGHT reveals substantial the reduction of score variance and changes in performance rankings compared to conventional HICO-DET. Our experiments demonstrate that evaluation under balanced conditions ensure more reliable and fair model comparisons.
Nickel and Diming Your GAN: A Dual-Method Approach to Enhancing GAN Efficiency via Knowledge Distillation
May 19, 2024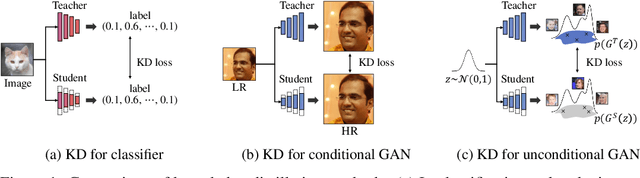

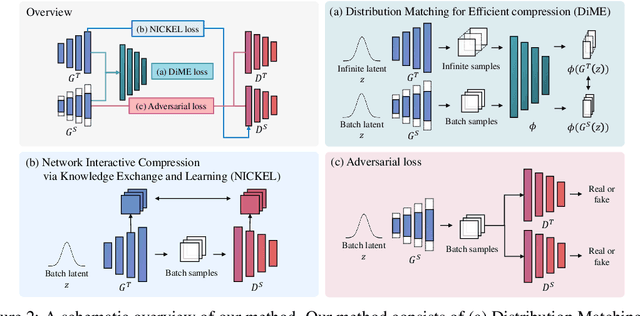
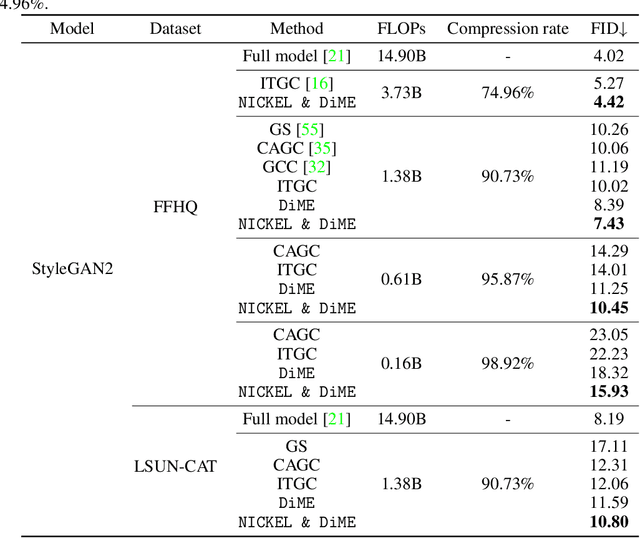
In this paper, we address the challenge of compressing generative adversarial networks (GANs) for deployment in resource-constrained environments by proposing two novel methodologies: Distribution Matching for Efficient compression (DiME) and Network Interactive Compression via Knowledge Exchange and Learning (NICKEL). DiME employs foundation models as embedding kernels for efficient distribution matching, leveraging maximum mean discrepancy to facilitate effective knowledge distillation. Simultaneously, NICKEL employs an interactive compression method that enhances the communication between the student generator and discriminator, achieving a balanced and stable compression process. Our comprehensive evaluation on the StyleGAN2 architecture with the FFHQ dataset shows the effectiveness of our approach, with NICKEL & DiME achieving FID scores of 10.45 and 15.93 at compression rates of 95.73% and 98.92%, respectively. Remarkably, our methods sustain generative quality even at an extreme compression rate of 99.69%, surpassing the previous state-of-the-art performance by a large margin. These findings not only demonstrate our methodologies' capacity to significantly lower GANs' computational demands but also pave the way for deploying high-quality GAN models in settings with limited resources. Our code will be released soon.
TopP&R: Robust Support Estimation Approach for Evaluating Fidelity and Diversity in Generative Models
Jun 21, 2023



We propose a robust and reliable evaluation metric for generative models by introducing topological and statistical treatments for rigorous support estimation. Existing metrics, such as Inception Score (IS), Frechet Inception Distance (FID), and the variants of Precision and Recall (P&R), heavily rely on supports that are estimated from sample features. However, the reliability of their estimation has not been seriously discussed (and overlooked) even though the quality of the evaluation entirely depends on it. In this paper, we propose Topological Precision and Recall (TopP&R, pronounced 'topper'), which provides a systematic approach to estimating supports, retaining only topologically and statistically important features with a certain level of confidence. This not only makes TopP&R strong for noisy features, but also provides statistical consistency. Our theoretical and experimental results show that TopP&R is robust to outliers and non-independent and identically distributed (Non-IID) perturbations, while accurately capturing the true trend of change in samples. To the best of our knowledge, this is the first evaluation metric focused on the robust estimation of the support and provides its statistical consistency under noise.
Can We Find Strong Lottery Tickets in Generative Models?
Dec 16, 2022Yes. In this paper, we investigate strong lottery tickets in generative models, the subnetworks that achieve good generative performance without any weight update. Neural network pruning is considered the main cornerstone of model compression for reducing the costs of computation and memory. Unfortunately, pruning a generative model has not been extensively explored, and all existing pruning algorithms suffer from excessive weight-training costs, performance degradation, limited generalizability, or complicated training. To address these problems, we propose to find a strong lottery ticket via moment-matching scores. Our experimental results show that the discovered subnetwork can perform similarly or better than the trained dense model even when only 10% of the weights remain. To the best of our knowledge, we are the first to show the existence of strong lottery tickets in generative models and provide an algorithm to find it stably. Our code and supplementary materials are publicly available.