 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHOM: Generating Physically Plausible Hand-Object Meshes From Text
Apr 03, 2026The generation of 3D hand-object interactions (HOIs) from text is crucial for dexterous robotic grasping and VR/AR content generation, requiring both high visual fidelity and physical plausibility. Nevertheless, the ill-posed problem of mesh extraction from text-generated Gaussians, and physics-based optimization on the erroneous meshes pose challenges. To address these issues, we introduce THOM, a training-free framework that generates photorealistic, physically plausible 3D HOI meshes without the need for a template object mesh. THOM employs a two-stage pipeline, initially generating the hand and object Gaussians, followed by physics-based HOI optimization. Our new mesh extraction method and vertex-to-Gaussian mapping explicitly assign Gaussian elements to mesh vertices, allowing topology-aware regularization. Furthermore, we improve the physical plausibility of interactions by VLM-guided translation refinement and contact-aware optimization. Comprehensive experiments demonstrate that THOM consistently surpasses state-of-the-art methods in terms of text alignment, visual realism, and interaction plausibility.
HandVQA: Diagnosing and Improving Fine-Grained Spatial Reasoning about Hands in Vision-Language Models
Mar 27, 2026Understanding the fine-grained articulation of human hands is critical in high-stakes settings such as robot-assisted surgery, chip manufacturing, and AR/VR-based human-AI interaction. Despite achieving near-human performance on general vision-language benchmarks, current vision-language models (VLMs) struggle with fine-grained spatial reasoning, especially in interpreting complex and articulated hand poses. We introduce HandVQA, a large-scale diagnostic benchmark designed to evaluate VLMs' understanding of detailed hand anatomy through visual question answering. Built upon high-quality 3D hand datasets (FreiHAND, InterHand2.6M, FPHA), our benchmark includes over 1.6M controlled multiple-choice questions that probe spatial relationships between hand joints, such as angles, distances, and relative positions. We evaluate several state-of-the-art VLMs (LLaVA, DeepSeek and Qwen-VL) in both base and fine-tuned settings, using lightweight fine-tuning via LoRA. Our findings reveal systematic limitations in current models, including hallucinated finger parts, incorrect geometric interpretations, and poor generalization. HandVQA not only exposes these critical reasoning gaps but provides a validated path to improvement. We demonstrate that the 3D-grounded spatial knowledge learned from our benchmark transfers in a zero-shot setting, significantly improving accuracy of model on novel downstream tasks like hand gesture recognition (+10.33%) and hand-object interaction (+2.63%).
Local K-Similarity Constraint for Federated Learning with Label Noise
Nov 09, 2025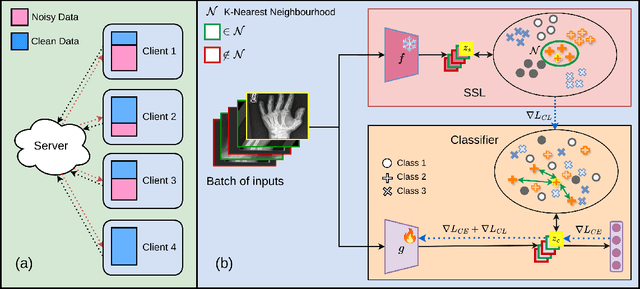

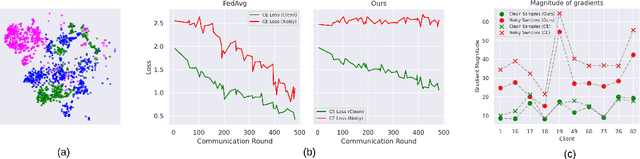
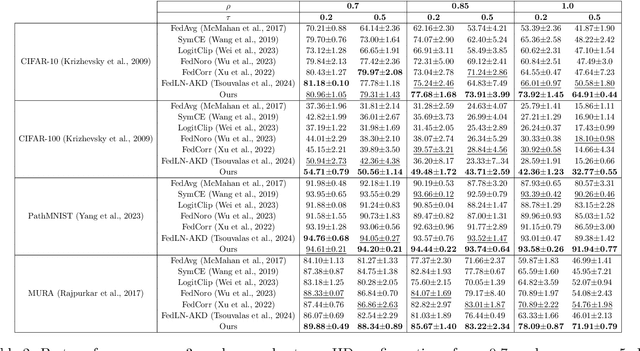
Federated learning on clients with noisy labels is a challenging problem, as such clients can infiltrate the global model, impacting the overall generalizability of the system. Existing methods proposed to handle noisy clients assume that a sufficient number of clients with clean labels are available, which can be leveraged to learn a robust global model while dampening the impact of noisy clients. This assumption fails when a high number of heterogeneous clients contain noisy labels, making the existing approaches ineffective. In such scenarios, it is important to locally regularize the clients before communication with the global model, to ensure the global model isn't corrupted by noisy clients. While pre-trained self-supervised models can be effective for local regularization, existing centralized approaches relying on pretrained initialization are impractical in a federated setting due to the potentially large size of these models, which increases communication costs. In that line, we propose a regularization objective for client models that decouples the pre-trained and classification models by enforcing similarity between close data points within the client. We leverage the representation space of a self-supervised pretrained model to evaluate the closeness among examples. This regularization, when applied with the standard objective function for the downstream task in standard noisy federated settings, significantly improves performance, outperforming existing state-of-the-art federated methods in multiple computer vision and medical image classification benchmarks. Unlike other techniques that rely on self-supervised pretrained initialization, our method does not require the pretrained model and classifier backbone to share the same architecture, making it architecture-agnostic.
Revisiting Reliability in the Reasoning-based Pose Estimation Benchmark
Jul 17, 2025The reasoning-based pose estimation (RPE) benchmark has emerged as a widely adopted evaluation standard for pose-aware multimodal large language models (MLLMs). Despite its significance, we identified critical reproducibility and benchmark-quality issues that hinder fair and consistent quantitative evaluations. Most notably, the benchmark utilizes different image indices from those of the original 3DPW dataset, forcing researchers into tedious and error-prone manual matching processes to obtain accurate ground-truth (GT) annotations for quantitative metrics (\eg, MPJPE, PA-MPJPE). Furthermore, our analysis reveals several inherent benchmark-quality limitations, including significant image redundancy, scenario imbalance, overly simplistic poses, and ambiguous textual descriptions, collectively undermining reliable evaluations across diverse scenarios. To alleviate manual effort and enhance reproducibility, we carefully refined the GT annotations through meticulous visual matching and publicly release these refined annotations as an open-source resource, thereby promoting consistent quantitative evaluations and facilitating future advancements in human pose-aware multimodal reasoning.
Beyond Spatial Frequency: Pixel-wise Temporal Frequency-based Deepfake Video Detection
Jul 03, 2025We introduce a deepfake video detection approach that exploits pixel-wise temporal inconsistencies, which traditional spatial frequency-based detectors often overlook. Traditional detectors represent temporal information merely by stacking spatial frequency spectra across frames, resulting in the failure to detect temporal artifacts in the pixel plane. Our approach performs a 1D Fourier transform on the time axis for each pixel, extracting features highly sensitive to temporal inconsistencies, especially in areas prone to unnatural movements. To precisely locate regions containing the temporal artifacts, we introduce an attention proposal module trained in an end-to-end manner. Additionally, our joint transformer module effectively integrates pixel-wise temporal frequency features with spatio-temporal context features, expanding the range of detectable forgery artifacts. Our framework represents a significant advancement in deepfake video detection, providing robust performance across diverse and challenging detection scenarios.
PoseBH: Prototypical Multi-Dataset Training Beyond Human Pose Estimation
May 23, 2025We study multi-dataset training (MDT) for pose estimation, where skeletal heterogeneity presents a unique challenge that existing methods have yet to address. In traditional domains, \eg regression and classification, MDT typically relies on dataset merging or multi-head supervision. However, the diversity of skeleton types and limited cross-dataset supervision complicate integration in pose estimation. To address these challenges, we introduce PoseBH, a new MDT framework that tackles keypoint heterogeneity and limited supervision through two key techniques. First, we propose nonparametric keypoint prototypes that learn within a unified embedding space, enabling seamless integration across skeleton types. Second, we develop a cross-type self-supervision mechanism that aligns keypoint predictions with keypoint embedding prototypes, providing supervision without relying on teacher-student models or additional augmentations. PoseBH substantially improves generalization across whole-body and animal pose datasets, including COCO-WholeBody, AP-10K, and APT-36K, while preserving performance on standard human pose benchmarks (COCO, MPII, and AIC). Furthermore, our learned keypoint embeddings transfer effectively to hand shape estimation (InterHand2.6M) and human body shape estimation (3DPW). The code for PoseBH is available at: https://github.com/uyoung-jeong/PoseBH.
BIGS: Bimanual Category-agnostic Interaction Reconstruction from Monocular Videos via 3D Gaussian Splatting
Apr 12, 2025Reconstructing 3Ds of hand-object interaction (HOI) is a fundamental problem that can find numerous applications. Despite recent advances, there is no comprehensive pipeline yet for bimanual class-agnostic interaction reconstruction from a monocular RGB video, where two hands and an unknown object are interacting with each other. Previous works tackled the limited hand-object interaction case, where object templates are pre-known or only one hand is involved in the interaction. The bimanual interaction reconstruction exhibits severe occlusions introduced by complex interactions between two hands and an object. To solve this, we first introduce BIGS (Bimanual Interaction 3D Gaussian Splatting), a method that reconstructs 3D Gaussians of hands and an unknown object from a monocular video. To robustly obtain object Gaussians avoiding severe occlusions, we leverage prior knowledge of pre-trained diffusion model with score distillation sampling (SDS) loss, to reconstruct unseen object parts. For hand Gaussians, we exploit the 3D priors of hand model (i.e., MANO) and share a single Gaussian for two hands to effectively accumulate hand 3D information, given limited views. To further consider the 3D alignment between hands and objects, we include the interacting-subjects optimization step during Gaussian optimization. Our method achieves the state-of-the-art accuracy on two challenging datasets, in terms of 3D hand pose estimation (MPJPE), 3D object reconstruction (CDh, CDo, F10), and rendering quality (PSNR, SSIM, LPIPS), respectively.
Diffusion Meets Few-shot Class Incremental Learning
Mar 30, 2025Few-shot class-incremental learning (FSCIL) is challenging due to extremely limited training data; while aiming to reduce catastrophic forgetting and learn new information. We propose Diffusion-FSCIL, a novel approach that employs a text-to-image diffusion model as a frozen backbone. Our conjecture is that FSCIL can be tackled using a large generative model's capabilities benefiting from 1) generation ability via large-scale pre-training; 2) multi-scale representation; 3) representational flexibility through the text encoder. To maximize the representation capability, we propose to extract multiple complementary diffusion features to play roles as latent replay with slight support from feature distillation for preventing generative biases. Our framework realizes efficiency through 1) using a frozen backbone; 2) minimal trainable components; 3) batch processing of multiple feature extractions. Extensive experiments on CUB-200, miniImageNet, and CIFAR-100 show that Diffusion-FSCIL surpasses state-of-the-art methods, preserving performance on previously learned classes and adapting effectively to new ones.
QORT-Former: Query-optimized Real-time Transformer for Understanding Two Hands Manipulating Objects
Feb 27, 2025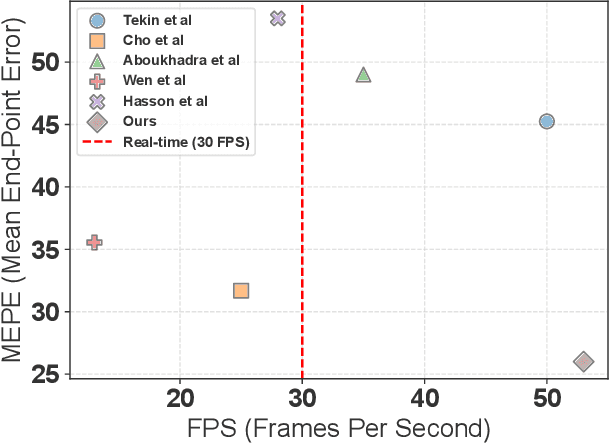
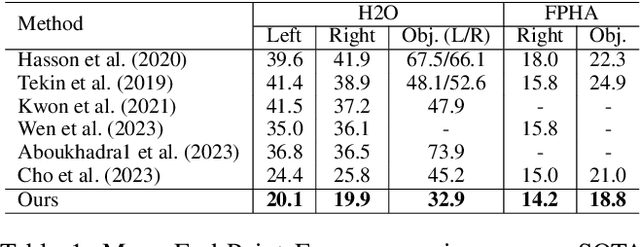
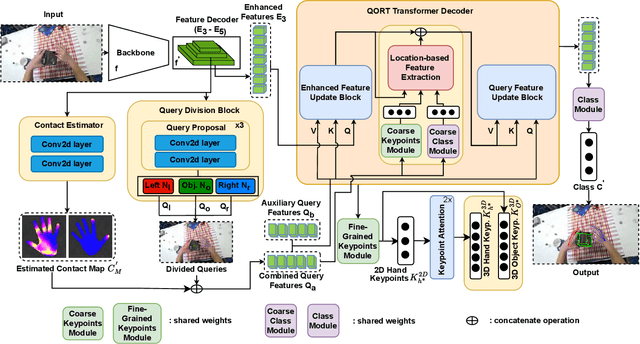
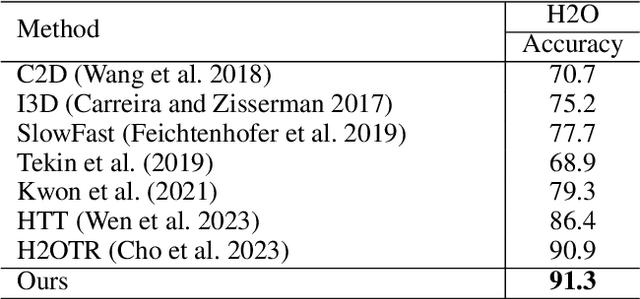
Significant advancements have been achieved in the realm of understanding poses and interactions of two hands manipulating an object. The emergence of augmented reality (AR) and virtual reality (VR) technologies has heightened the demand for real-time performance in these applications. However, current state-of-the-art models often exhibit promising results at the expense of substantial computational overhead. In this paper, we present a query-optimized real-time Transformer (QORT-Former), the first Transformer-based real-time framework for 3D pose estimation of two hands and an object. We first limit the number of queries and decoders to meet the efficiency requirement. Given limited number of queries and decoders, we propose to optimize queries which are taken as input to the Transformer decoder, to secure better accuracy: (1) we propose to divide queries into three types (a left hand query, a right hand query and an object query) and enhance query features (2) by using the contact information between hands and an object and (3) by using three-step update of enhanced image and query features with respect to one another. With proposed methods, we achieved real-time pose estimation performance using just 108 queries and 1 decoder (53.5 FPS on an RTX 3090TI GPU). Surpassing state-of-the-art results on the H2O dataset by 17.6% (left hand), 22.8% (right hand), and 27.2% (object), as well as on the FPHA dataset by 5.3% (right hand) and 10.4% (object), our method excels in accuracy. Additionally, it sets the state-of-the-art in interaction recognition, maintaining real-time efficiency with an off-the-shelf action recognition module.
B-RIGHT: Benchmark Re-evaluation for Integrity in Generalized Human-Object Interaction Testing
Jan 28, 2025Human-object interaction (HOI) is an essential problem in artificial intelligence (AI) which aims to understand the visual world that involves complex relationships between humans and objects. However, current benchmarks such as HICO-DET face the following limitations: (1) severe class imbalance and (2) varying number of train and test sets for certain classes. These issues can potentially lead to either inflation or deflation of model performance during evaluation, ultimately undermining the reliability of evaluation scores. In this paper, we propose a systematic approach to develop a new class-balanced dataset, Benchmark Re-evaluation for Integrity in Generalized Human-object Interaction Testing (B-RIGHT), that addresses these imbalanced problems. B-RIGHT achieves class balance by leveraging balancing algorithm and automated generation-and-filtering processes, ensuring an equal number of instances for each HOI class. Furthermore, we design a balanced zero-shot test set to systematically evaluate models on unseen scenario. Re-evaluating existing models using B-RIGHT reveals substantial the reduction of score variance and changes in performance rankings compared to conventional HICO-DET. Our experiments demonstrate that evaluation under balanced conditions ensure more reliable and fair model comparisons.