 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseBH: Prototypical Multi-Dataset Training Beyond Human Pose Estimation
May 23, 2025We study multi-dataset training (MDT) for pose estimation, where skeletal heterogeneity presents a unique challenge that existing methods have yet to address. In traditional domains, \eg regression and classification, MDT typically relies on dataset merging or multi-head supervision. However, the diversity of skeleton types and limited cross-dataset supervision complicate integration in pose estimation. To address these challenges, we introduce PoseBH, a new MDT framework that tackles keypoint heterogeneity and limited supervision through two key techniques. First, we propose nonparametric keypoint prototypes that learn within a unified embedding space, enabling seamless integration across skeleton types. Second, we develop a cross-type self-supervision mechanism that aligns keypoint predictions with keypoint embedding prototypes, providing supervision without relying on teacher-student models or additional augmentations. PoseBH substantially improves generalization across whole-body and animal pose datasets, including COCO-WholeBody, AP-10K, and APT-36K, while preserving performance on standard human pose benchmarks (COCO, MPII, and AIC). Furthermore, our learned keypoint embeddings transfer effectively to hand shape estimation (InterHand2.6M) and human body shape estimation (3DPW). The code for PoseBH is available at: https://github.com/uyoung-jeong/PoseBH.
Clothes Grasping and Unfolding Based on RGB-D Semantic Segmentation
May 08, 2023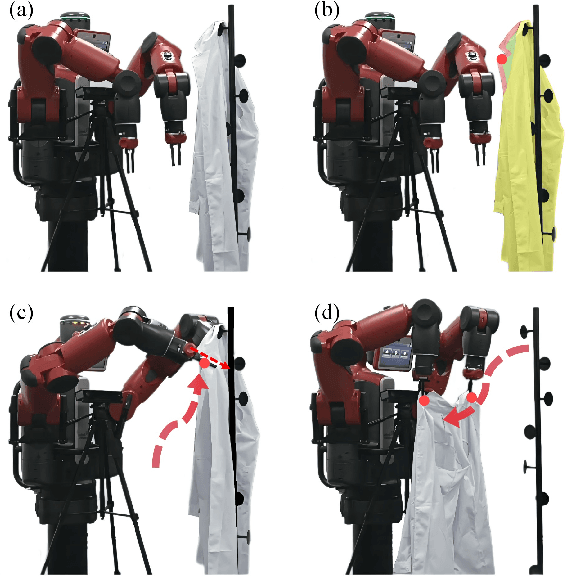
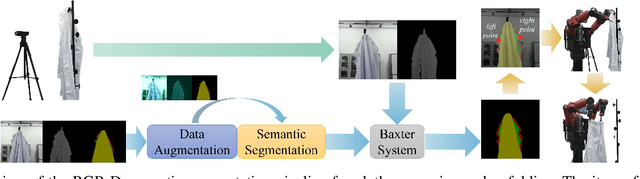
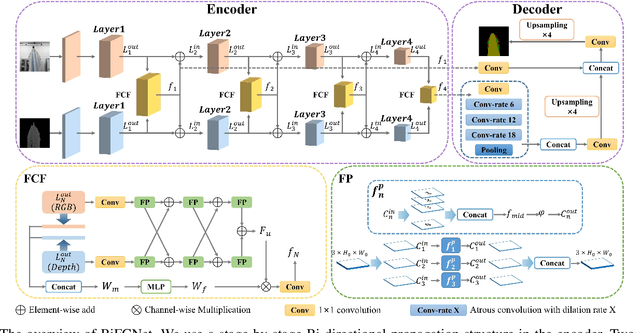

Clothes grasping and unfolding is a core step in robotic-assisted dressing. Most existing works leverage depth images of clothes to train a deep learning-based model to recognize suitable grasping points. These methods often utilize physics engines to synthesize depth images to reduce the cost of real labeled data collection. However, the natural domain gap between synthetic and real images often leads to poor performance of these methods on real data. Furthermore, these approaches often struggle in scenarios where grasping points are occluded by the clothing item itself. To address the above challenges, we propose a novel Bi-directional Fractal Cross Fusion Network (BiFCNet) for semantic segmentation, enabling recognition of graspable regions in order to provide more possibilities for grasping. Instead of using depth images only, we also utilize RGB images with rich color features as input to our network in which the Fractal Cross Fusion (FCF) module fuses RGB and depth data by considering global complex features based on fractal geometry. To reduce the cost of real data collection, we further propose a data augmentation method based on an adversarial strategy, in which the color and geometric transformations simultaneously process RGB and depth data while maintaining the label correspondence. Finally, we present a pipeline for clothes grasping and unfolding from the perspective of semantic segmentation, through the addition of a strategy for grasp point selection from segmentation regions based on clothing flatness measures, while taking into account the grasping direction. We evaluate our BiFCNet on the public dataset NYUDv2 and obtained comparable performance to current state-of-the-art models. We also deploy our model on a Baxter robot, running extensive grasping and unfolding experiments as part of our ablation studies, achieving an 84% success rate.