 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHOM: Generating Physically Plausible Hand-Object Meshes From Text
Apr 03, 2026The generation of 3D hand-object interactions (HOIs) from text is crucial for dexterous robotic grasping and VR/AR content generation, requiring both high visual fidelity and physical plausibility. Nevertheless, the ill-posed problem of mesh extraction from text-generated Gaussians, and physics-based optimization on the erroneous meshes pose challenges. To address these issues, we introduce THOM, a training-free framework that generates photorealistic, physically plausible 3D HOI meshes without the need for a template object mesh. THOM employs a two-stage pipeline, initially generating the hand and object Gaussians, followed by physics-based HOI optimization. Our new mesh extraction method and vertex-to-Gaussian mapping explicitly assign Gaussian elements to mesh vertices, allowing topology-aware regularization. Furthermore, we improve the physical plausibility of interactions by VLM-guided translation refinement and contact-aware optimization. Comprehensive experiments demonstrate that THOM consistently surpasses state-of-the-art methods in terms of text alignment, visual realism, and interaction plausibility.
Physically Guided Visual Mass Estimation from a Single RGB Image
Jan 28, 2026Estimating object mass from visual input is challenging because mass depends jointly on geometric volume and material-dependent density, neither of which is directly observable from RGB appearance. Consequently, mass prediction from pixels is ill-posed and therefore benefits from physically meaningful representations to constrain the space of plausible solutions. We propose a physically structured framework for single-image mass estimation that addresses this ambiguity by aligning visual cues with the physical factors governing mass. From a single RGB image, we recover object-centric three-dimensional geometry via monocular depth estimation to inform volume and extract coarse material semantics using a vision-language model to guide density-related reasoning. These geometry, semantic, and appearance representations are fused through an instance-adaptive gating mechanism, and two physically guided latent factors (volume- and density-related) are predicted through separate regression heads under mass-only supervision. Experiments on image2mass and ABO-500 show that the proposed method consistently outperforms state-of-the-art methods.
Subspace-based Approximate Hessian Method for Zeroth-Order Optimization
Jul 08, 2025Zeroth-order optimization addresses problems where gradient information is inaccessible or impractical to compute. While most existing methods rely on first-order approximations, incorporating second-order (curvature) information can, in principle, significantly accelerate convergence. However, the high cost of function evaluations required to estimate Hessian matrices often limits practical applicability. We present the subspace-based approximate Hessian (ZO-SAH) method, a zeroth-order optimization algorithm that mitigates these costs by focusing on randomly selected two-dimensional subspaces. Within each subspace, ZO-SAH estimates the Hessian by fitting a quadratic polynomial to the objective function and extracting its second-order coefficients. To further reduce function-query costs, ZO-SAH employs a periodic subspace-switching strategy that reuses function evaluations across optimization steps. Experiments on eight benchmark datasets, including logistic regression and deep neural network training tasks, demonstrate that ZO-SAH achieves significantly faster convergence than existing zeroth-order methods.
PoseBH: Prototypical Multi-Dataset Training Beyond Human Pose Estimation
May 23, 2025We study multi-dataset training (MDT) for pose estimation, where skeletal heterogeneity presents a unique challenge that existing methods have yet to address. In traditional domains, \eg regression and classification, MDT typically relies on dataset merging or multi-head supervision. However, the diversity of skeleton types and limited cross-dataset supervision complicate integration in pose estimation. To address these challenges, we introduce PoseBH, a new MDT framework that tackles keypoint heterogeneity and limited supervision through two key techniques. First, we propose nonparametric keypoint prototypes that learn within a unified embedding space, enabling seamless integration across skeleton types. Second, we develop a cross-type self-supervision mechanism that aligns keypoint predictions with keypoint embedding prototypes, providing supervision without relying on teacher-student models or additional augmentations. PoseBH substantially improves generalization across whole-body and animal pose datasets, including COCO-WholeBody, AP-10K, and APT-36K, while preserving performance on standard human pose benchmarks (COCO, MPII, and AIC). Furthermore, our learned keypoint embeddings transfer effectively to hand shape estimation (InterHand2.6M) and human body shape estimation (3DPW). The code for PoseBH is available at: https://github.com/uyoung-jeong/PoseBH.
GraspCorrect: Robotic Grasp Correction via Vision-Language Model-Guided Feedback
Mar 19, 2025Despite significant advancements in robotic manipulation, achieving consistent and stable grasping remains a fundamental challenge, often limiting the successful execution of complex tasks. Our analysis reveals that even state-of-the-art policy models frequently exhibit unstable grasping behaviors, leading to failure cases that create bottlenecks in real-world robotic applications. To address these challenges, we introduce GraspCorrect, a plug-and-play module designed to enhance grasp performance through vision-language model-guided feedback. GraspCorrect employs an iterative visual question-answering framework with two key components: grasp-guided prompting, which incorporates task-specific constraints, and object-aware sampling, which ensures the selection of physically feasible grasp candidates. By iteratively generating intermediate visual goals and translating them into joint-level actions, GraspCorrect significantly improves grasp stability and consistently enhances task success rates across existing policy models in the RLBench and CALVIN datasets.
REP: Resource-Efficient Prompting for On-device Continual Learning
Jun 07, 2024



On-device continual learning (CL) requires the co-optimization of model accuracy and resource efficiency to be practical. This is extremely challenging because it must preserve accuracy while learning new tasks with continuously drifting data and maintain both high energy and memory efficiency to be deployable on real-world devices. Typically, a CL method leverages one of two types of backbone networks: CNN or ViT. It is commonly believed that CNN-based CL excels in resource efficiency, whereas ViT-based CL is superior in model performance, making each option attractive only for a single aspect. In this paper, we revisit this comparison while embracing powerful pre-trained ViT models of various sizes, including ViT-Ti (5.8M parameters). Our detailed analysis reveals that many practical options exist today for making ViT-based methods more suitable for on-device CL, even when accuracy, energy, and memory are all considered. To further expand this impact, we introduce REP, which improves resource efficiency specifically targeting prompt-based rehearsal-free methods. Our key focus is on avoiding catastrophic trade-offs with accuracy while trimming computational and memory costs throughout the training process. We achieve this by exploiting swift prompt selection that enhances input data using a carefully provisioned model, and by developing two novel algorithms-adaptive token merging (AToM) and adaptive layer dropping (ALD)-that optimize the prompt updating stage. In particular, AToM and ALD perform selective skipping across the data and model-layer dimensions without compromising task-specific features in vision transformer models. Extensive experiments on three image classification datasets validate REP's superior resource efficiency over current state-of-the-art methods.
In Search of a Data Transformation That Accelerates Neural Field Training
Nov 28, 2023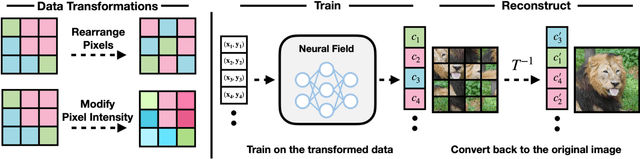
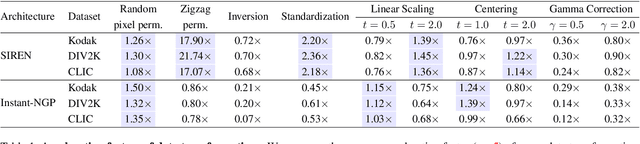
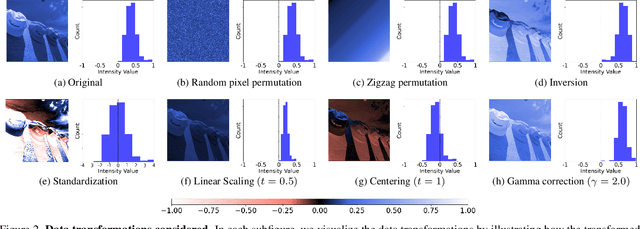
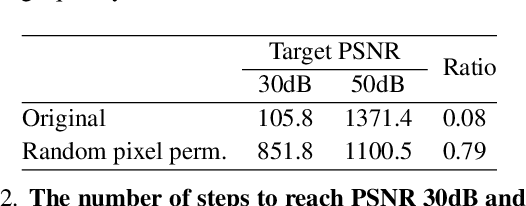
Neural field is an emerging paradigm in data representation that trains a neural network to approximate the given signal. A key obstacle that prevents its widespread adoption is the encoding speed-generating neural fields requires an overfitting of a neural network, which can take a significant number of SGD steps to reach the desired fidelity level. In this paper, we delve into the impacts of data transformations on the speed of neural field training, specifically focusing on how permuting pixel locations affect the convergence speed of SGD. Counterintuitively, we find that randomly permuting the pixel locations can considerably accelerate the training. To explain this phenomenon, we examine the neural field training through the lens of PSNR curves, loss landscapes, and error patterns. Our analyses suggest that the random pixel permutations remove the easy-to-fit patterns, which facilitate easy optimization in the early stage but hinder capturing fine details of the signal.
BoIR: Box-Supervised Instance Representation for Multi-Person Pose Estimation
Sep 25, 2023



Single-stage multi-person human pose estimation (MPPE) methods have shown great performance improvements, but existing methods fail to disentangle features by individual instances under crowded scenes. In this paper, we propose a bounding box-level instance representation learning called BoIR, which simultaneously solves instance detection, instance disentanglement, and instance-keypoint association problems. Our new instance embedding loss provides a learning signal on the entire area of the image with bounding box annotations, achieving globally consistent and disentangled instance representation. Our method exploits multi-task learning of bottom-up keypoint estimation, bounding box regression, and contrastive instance embedding learning, without additional computational cost during inference. BoIR is effective for crowded scenes, outperforming state-of-the-art on COCO val (0.8 AP), COCO test-dev (0.5 AP), CrowdPose (4.9 AP), and OCHuman (3.5 AP). Code will be available at https://github.com/uyoung-jeong/BoIR
Active Deep Learning Guided by Efficient Gaussian Process Surrogates
Jan 07, 2023


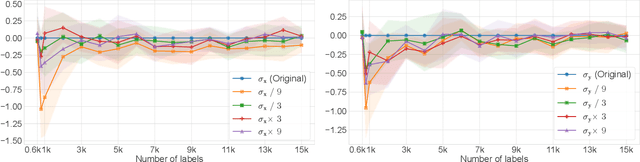
The success of active learning relies on the exploration of the underlying data-generating distributions, populating sparsely labeled data areas, and exploitation of the information about the task gained by the baseline (neural network) learners. In this paper, we present a new algorithm that combines these two active learning modes. Our algorithm adopts a Bayesian surrogate for the baseline learner, and it optimizes the exploration process by maximizing the gain of information caused by new labels. Further, by instantly updating the surrogate learner for each new data instance, our model can faithfully simulate and exploit the continuous learning behavior of the learner without having to actually retrain it per label. In experiments with four benchmark classification datasets, our method demonstrated significant performance gain over state-of-the-arts.
S$^2$Contact: Graph-based Network for 3D Hand-Object Contact Estimation with Semi-Supervised Learning
Aug 01, 2022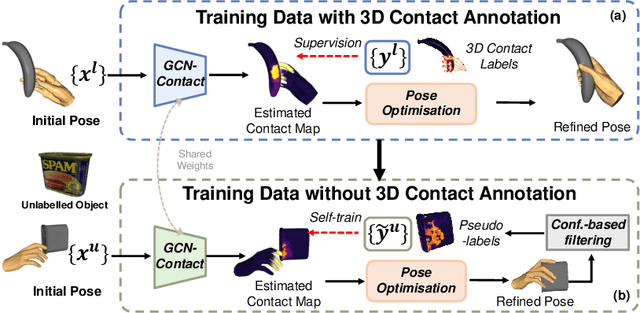
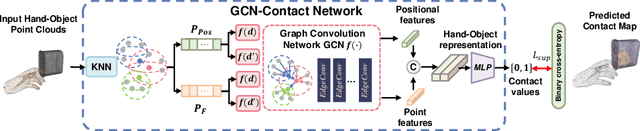
Despite the recent efforts in accurate 3D annotations in hand and object datasets, there still exist gaps in 3D hand and object reconstructions. Existing works leverage contact maps to refine inaccurate hand-object pose estimations and generate grasps given object models. However, they require explicit 3D supervision which is seldom available and therefore, are limited to constrained settings, e.g., where thermal cameras observe residual heat left on manipulated objects. In this paper, we propose a novel semi-supervised framework that allows us to learn contact from monocular images. Specifically, we leverage visual and geometric consistency constraints in large-scale datasets for generating pseudo-labels in semi-supervised learning and propose an efficient graph-based network to infer contact. Our semi-supervised learning framework achieves a favourable improvement over the existing supervised learning methods trained on data with `limited' annotations. Notably, our proposed model is able to achieve superior results with less than half the network parameters and memory access cost when compared with the commonly-used PointNet-based approach. We show benefits from using a contact map that rules hand-object interactions to produce more accurate reconstructions. We further demonstrate that training with pseudo-labels can extend contact map estimations to out-of-domain objects and generalise better across multiple datasets.