 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Optimization Meets Self-Distillation
Apr 25, 2023



Bayesian optimization (BO) has contributed greatly to improving model performance by suggesting promising hyperparameter configurations iteratively based on observations from multiple training trials. However, only partial knowledge (i.e., the measured performances of trained models and their hyperparameter configurations) from previous trials is transferred. On the other hand, Self-Distillation (SD) only transfers partial knowledge learned by the task model itself. To fully leverage the various knowledge gained from all training trials, we propose the BOSS framework, which combines BO and SD. BOSS suggests promising hyperparameter configurations through BO and carefully selects pre-trained models from previous trials for SD, which are otherwise abandoned in the conventional BO process. BOSS achieves significantly better performance than both BO and SD in a wide range of tasks including general image classification, learning with noisy labels, semi-supervised learning, and medical image analysis tasks.
Active Deep Learning Guided by Efficient Gaussian Process Surrogates
Jan 07, 2023


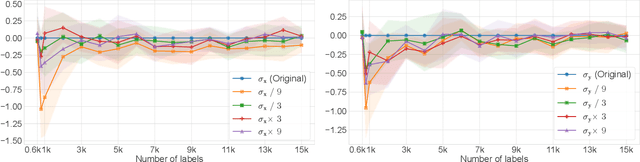
The success of active learning relies on the exploration of the underlying data-generating distributions, populating sparsely labeled data areas, and exploitation of the information about the task gained by the baseline (neural network) learners. In this paper, we present a new algorithm that combines these two active learning modes. Our algorithm adopts a Bayesian surrogate for the baseline learner, and it optimizes the exploration process by maximizing the gain of information caused by new labels. Further, by instantly updating the surrogate learner for each new data instance, our model can faithfully simulate and exploit the continuous learning behavior of the learner without having to actually retrain it per label. In experiments with four benchmark classification datasets, our method demonstrated significant performance gain over state-of-the-arts.