 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCORPION: Addressing Scanner-Induced Variability in Histopathology
Jul 28, 2025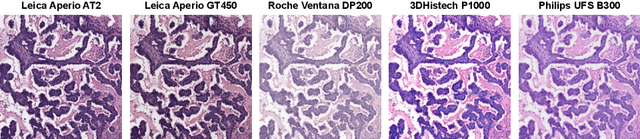
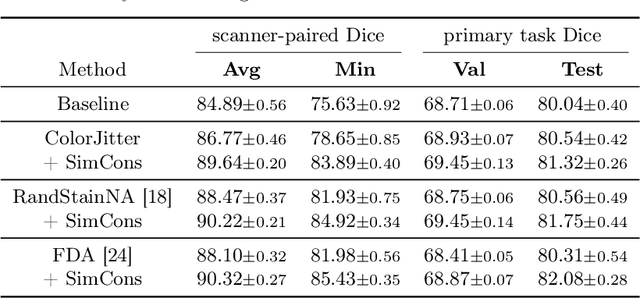


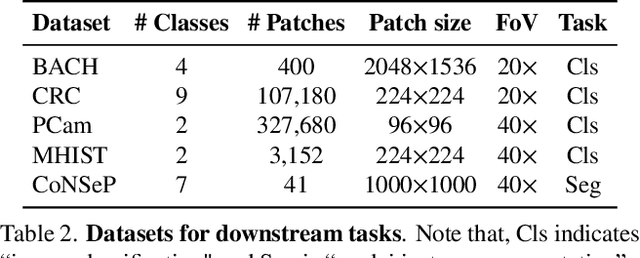
Ensuring reliable model performance across diverse domains is a critical challenge in computational pathology. A particular source of variability in Whole-Slide Images is introduced by differences in digital scanners, thus calling for better scanner generalization. This is critical for the real-world adoption of computational pathology, where the scanning devices may differ per institution or hospital, and the model should not be dependent on scanner-induced details, which can ultimately affect the patient's diagnosis and treatment planning. However, past efforts have primarily focused on standard domain generalization settings, evaluating on unseen scanners during training, without directly evaluating consistency across scanners for the same tissue. To overcome this limitation, we introduce SCORPION, a new dataset explicitly designed to evaluate model reliability under scanner variability. SCORPION includes 480 tissue samples, each scanned with 5 scanners, yielding 2,400 spatially aligned patches. This scanner-paired design allows for the isolation of scanner-induced variability, enabling a rigorous evaluation of model consistency while controlling for differences in tissue composition. Furthermore, we propose SimCons, a flexible framework that combines augmentation-based domain generalization techniques with a consistency loss to explicitly address scanner generalization. We empirically show that SimCons improves model consistency on varying scanners without compromising task-specific performance. By releasing the SCORPION dataset and proposing SimCons, we provide the research community with a crucial resource for evaluating and improving model consistency across diverse scanners, setting a new standard for reliability testing.
Bayesian Optimization Meets Self-Distillation
Apr 25, 2023



Bayesian optimization (BO) has contributed greatly to improving model performance by suggesting promising hyperparameter configurations iteratively based on observations from multiple training trials. However, only partial knowledge (i.e., the measured performances of trained models and their hyperparameter configurations) from previous trials is transferred. On the other hand, Self-Distillation (SD) only transfers partial knowledge learned by the task model itself. To fully leverage the various knowledge gained from all training trials, we propose the BOSS framework, which combines BO and SD. BOSS suggests promising hyperparameter configurations through BO and carefully selects pre-trained models from previous trials for SD, which are otherwise abandoned in the conventional BO process. BOSS achieves significantly better performance than both BO and SD in a wide range of tasks including general image classification, learning with noisy labels, semi-supervised learning, and medical image analysis tasks.
Benchmarking Self-Supervised Learning on Diverse Pathology Datasets
Dec 09, 2022


Computational pathology can lead to saving human lives, but models are annotation hungry and pathology images are notoriously expensive to annotate. Self-supervised learning has shown to be an effective method for utilizing unlabeled data, and its application to pathology could greatly benefit its downstream tasks. Yet, there are no principled studies that compare SSL methods and discuss how to adapt them for pathology. To address this need, we execute the largest-scale study of SSL pre-training on pathology image data, to date. Our study is conducted using 4 representative SSL methods on diverse downstream tasks. We establish that large-scale domain-aligned pre-training in pathology consistently out-performs ImageNet pre-training in standard SSL settings such as linear and fine-tuning evaluations, as well as in low-label regimes. Moreover, we propose a set of domain-specific techniques that we experimentally show leads to a performance boost. Lastly, for the first time, we apply SSL to the challenging task of nuclei instance segmentation and show large and consistent performance improvements under diverse settings.
Variability Matters : Evaluating inter-rater variability in histopathology for robust cell detection
Oct 11, 2022

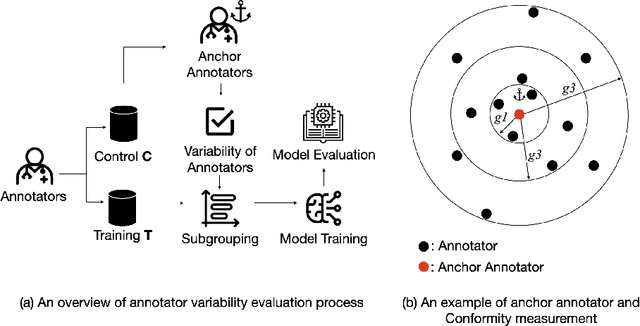
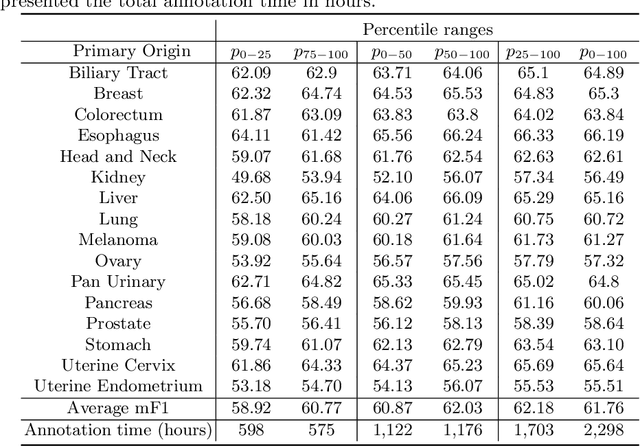
Large annotated datasets have been a key component in the success of deep learning. However, annotating medical images is challenging as it requires expertise and a large budget. In particular, annotating different types of cells in histopathology suffer from high inter- and intra-rater variability due to the ambiguity of the task. Under this setting, the relation between annotators' variability and model performance has received little attention. We present a large-scale study on the variability of cell annotations among 120 board-certified pathologists and how it affects the performance of a deep learning model. We propose a method to measure such variability, and by excluding those annotators with low variability, we verify the trade-off between the amount of data and its quality. We found that naively increasing the data size at the expense of inter-rater variability does not necessarily lead to better-performing models in cell detection. Instead, decreasing the inter-rater variability with the expense of decreasing dataset size increased the model performance. Furthermore, models trained from data annotated with lower inter-labeler variability outperform those from higher inter-labeler variability. These findings suggest that the evaluation of the annotators may help tackle the fundamental budget issues in the histopathology domain
Interactive Multi-Class Tiny-Object Detection
Mar 29, 2022

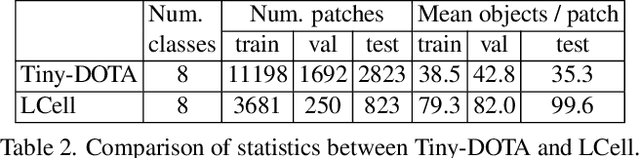
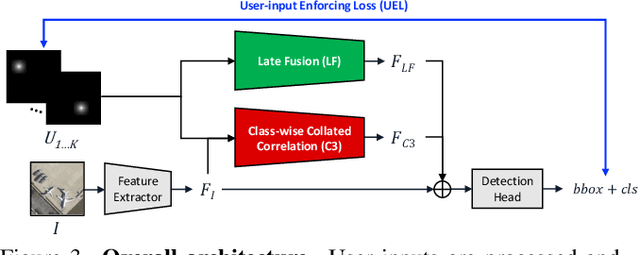
Annotating tens or hundreds of tiny objects in a given image is laborious yet crucial for a multitude of Computer Vision tasks. Such imagery typically contains objects from various categories, yet the multi-class interactive annotation setting for the detection task has thus far been unexplored. To address these needs, we propose a novel interactive annotation method for multiple instances of tiny objects from multiple classes, based on a few point-based user inputs. Our approach, C3Det, relates the full image context with annotator inputs in a local and global manner via late-fusion and feature-correlation, respectively. We perform experiments on the Tiny-DOTA and LCell datasets using both two-stage and one-stage object detection architectures to verify the efficacy of our approach. Our approach outperforms existing approaches in interactive annotation, achieving higher mAP with fewer clicks. Furthermore, we validate the annotation efficiency of our approach in a user study where it is shown to be 2.85x faster and yield only 0.36x task load (NASA-TLX, lower is better) compared to manual annotation. The code is available at https://github.com/ChungYi347/Interactive-Multi-Class-Tiny-Object-Detection.
Meta-learning of Pooling Layers for Character Recognition
Mar 17, 2021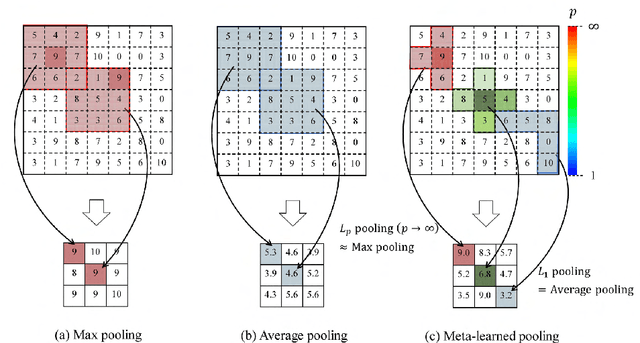
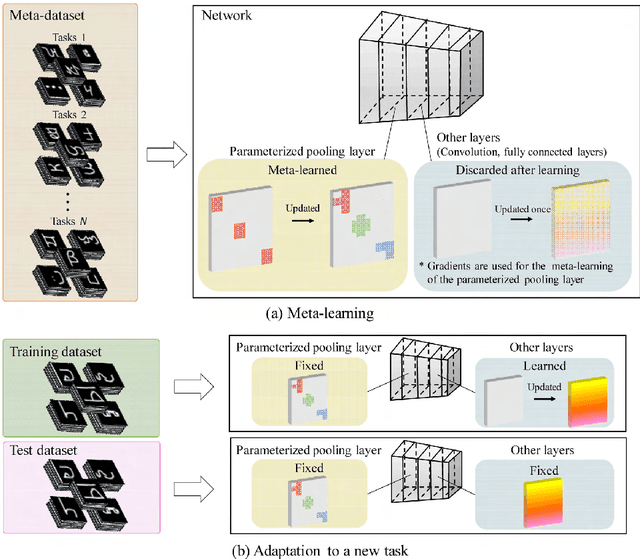
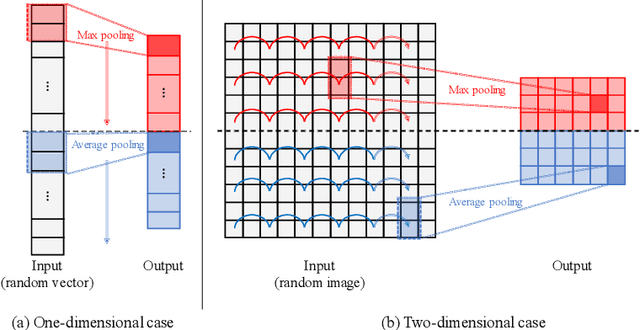
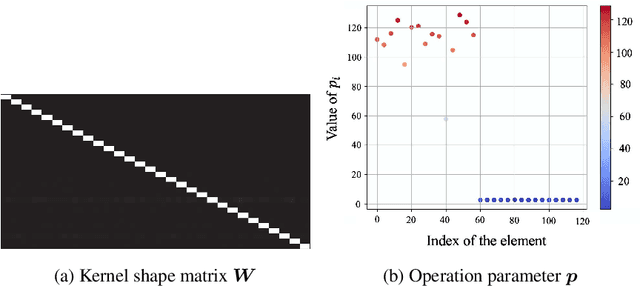
In convolutional neural network-based character recognition, pooling layers play an important role in dimensionality reduction and deformation compensation. However, their kernel shapes and pooling operations are empirically predetermined; typically, a fixed-size square kernel shape and max pooling operation are used. In this paper, we propose a meta-learning framework for pooling layers. As part of our framework, a parameterized pooling layer is proposed in which the kernel shape and pooling operation are trainable using two parameters, thereby allowing flexible pooling of the input data. We also propose a meta-learning algorithm for the parameterized pooling layer, which allows us to acquire a suitable pooling layer across multiple tasks. In the experiment, we applied the proposed meta-learning framework to character recognition tasks. The results demonstrate that a pooling layer that is suitable across character recognition tasks was obtained via meta-learning, and the obtained pooling layer improved the performance of the model in both few-shot character recognition and noisy image recognition tasks.
AAA: Adaptive Aggregation of Arbitrary Online Trackers with Theoretical Performance Guarantee
Sep 24, 2020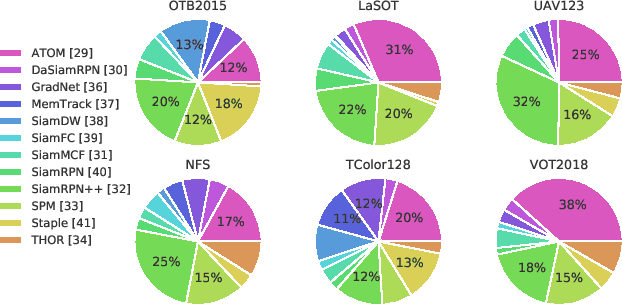
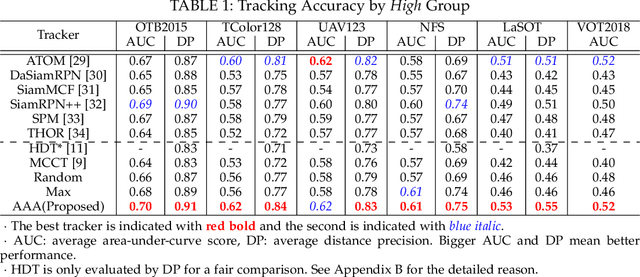

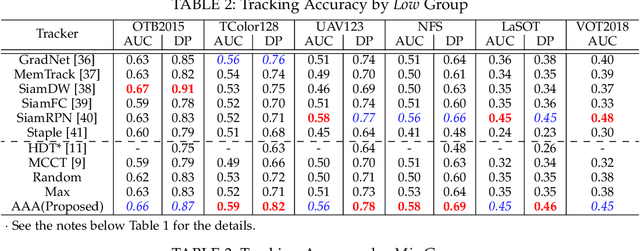
For visual object tracking, it is difficult to realize an almighty online tracker due to the huge variations of target appearance depending on an image sequence. This paper proposes an online tracking method that adaptively aggregates arbitrary multiple online trackers. The performance of the proposed method is theoretically guaranteed to be comparable to that of the best tracker for any image sequence, although the best expert is unknown during tracking. The experimental study on the large variations of benchmark datasets and aggregated trackers demonstrates that the proposed method can achieve state-of-the-art performance. The code is available at https://github.com/songheony/AAA-journal.