 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning of Pooling Layers for Character Recognition
Mar 17, 2021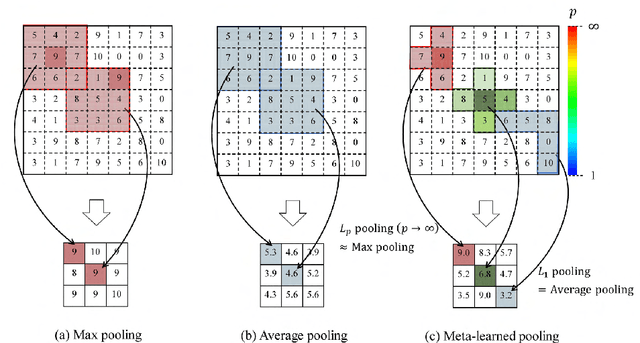
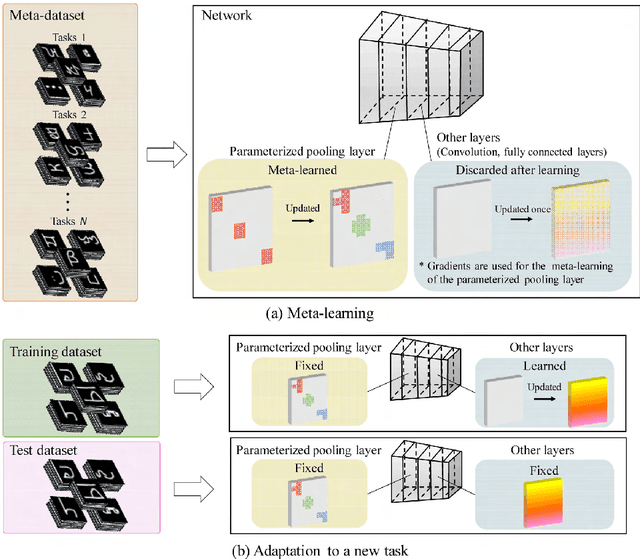
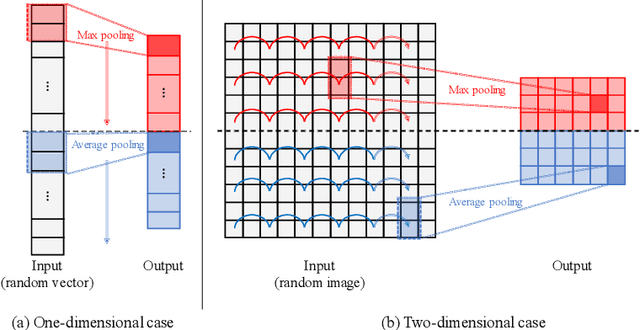
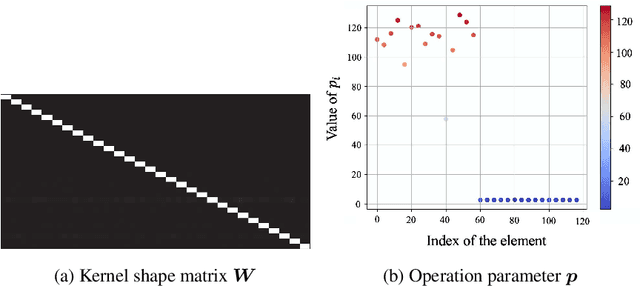
In convolutional neural network-based character recognition, pooling layers play an important role in dimensionality reduction and deformation compensation. However, their kernel shapes and pooling operations are empirically predetermined; typically, a fixed-size square kernel shape and max pooling operation are used. In this paper, we propose a meta-learning framework for pooling layers. As part of our framework, a parameterized pooling layer is proposed in which the kernel shape and pooling operation are trainable using two parameters, thereby allowing flexible pooling of the input data. We also propose a meta-learning algorithm for the parameterized pooling layer, which allows us to acquire a suitable pooling layer across multiple tasks. In the experiment, we applied the proposed meta-learning framework to character recognition tasks. The results demonstrate that a pooling layer that is suitable across character recognition tasks was obtained via meta-learning, and the obtained pooling layer improved the performance of the model in both few-shot character recognition and noisy image recognition tasks.
Regularized Pooling
May 06, 2020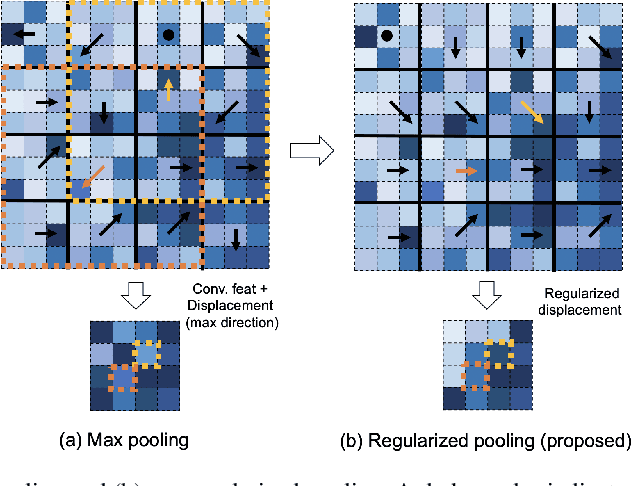

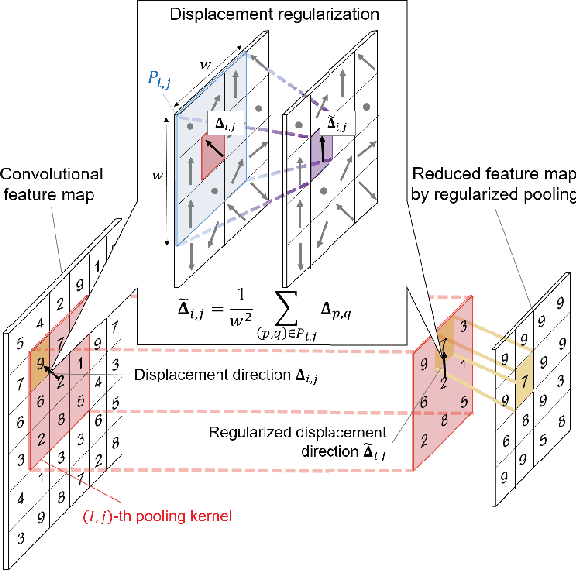
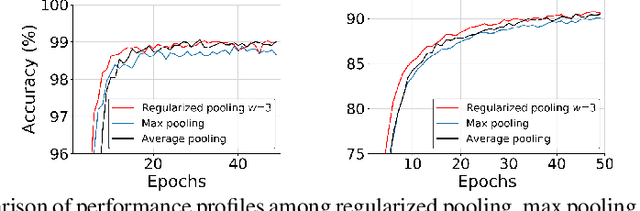
In convolutional neural networks (CNNs), pooling operations play important roles such as dimensionality reduction and deformation compensation. In general, max pooling, which is the most widely used operation for local pooling, is performed independently for each kernel. However, the deformation may be spatially smooth over the neighboring kernels. This means that max pooling is too flexible to compensate for actual deformations. In other words, its excessive flexibility risks canceling the essential spatial differences between classes. In this paper, we propose regularized pooling, which enables the value selection direction in the pooling operation to be spatially smooth across adjacent kernels so as to compensate only for actual deformations. The results of experiments on handwritten character images and texture images showed that regularized pooling not only improves recognition accuracy but also accelerates the convergence of learning compared with conventional pooling operations.