 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Majority Label: A Novel Problem in Multi-class Multiple-Instance Learning
Sep 04, 2025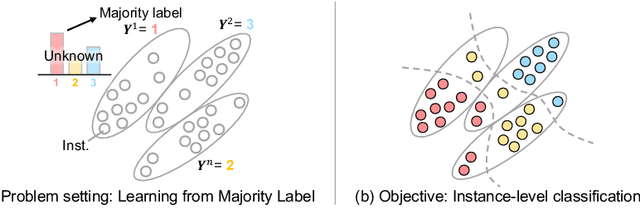

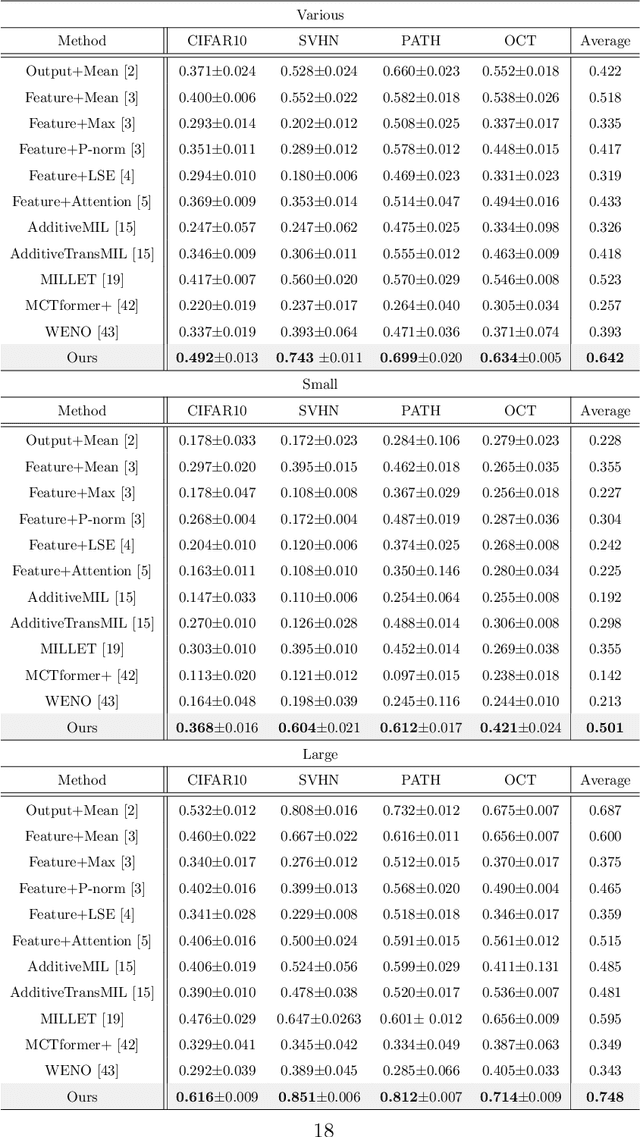
The paper proposes a novel multi-class Multiple-Instance Learning (MIL) problem called Learning from Majority Label (LML). In LML, the majority class of instances in a bag is assigned as the bag-level label. The goal of LML is to train a classification model that estimates the class of each instance using the majority label. This problem is valuable in a variety of applications, including pathology image segmentation, political voting prediction, customer sentiment analysis, and environmental monitoring. To solve LML, we propose a Counting Network trained to produce bag-level majority labels, estimated by counting the number of instances in each class. Furthermore, analysis experiments on the characteristics of LML revealed that bags with a high proportion of the majority class facilitate learning. Based on this result, we developed a Majority Proportion Enhancement Module (MPEM) that increases the proportion of the majority class by removing minority class instances within the bags. Experiments demonstrate the superiority of the proposed method on four datasets compared to conventional MIL methods. Moreover, ablation studies confirmed the effectiveness of each module. The code is available at \href{https://github.com/Shiku-Kaito/Learning-from-Majority-Label-A-Novel-Problem-in-Multi-class-Multiple-Instance-Learning}{here}.
Ordinal Multiple-instance Learning for Ulcerative Colitis Severity Estimation with Selective Aggregated Transformer
Nov 22, 2024



Patient-level diagnosis of severity in ulcerative colitis (UC) is common in real clinical settings, where the most severe score in a patient is recorded. However, previous UC classification methods (i.e., image-level estimation) mainly assumed the input was a single image. Thus, these methods can not utilize severity labels recorded in real clinical settings. In this paper, we propose a patient-level severity estimation method by a transformer with selective aggregator tokens, where a severity label is estimated from multiple images taken from a patient, similar to a clinical setting. Our method can effectively aggregate features of severe parts from a set of images captured in each patient, and it facilitates improving the discriminative ability between adjacent severity classes. Experiments demonstrate the effectiveness of the proposed method on two datasets compared with the state-of-the-art MIL methods. Moreover, we evaluated our method in real clinical settings and confirmed that our method outperformed the previous image-level methods. The code is publicly available at https://github.com/Shiku-Kaito/Ordinal-Multiple-instance-Learning-for-Ulcerative-Colitis-Severity-Estimation.
Theoretical Proportion Label Perturbation for Learning from Label Proportions in Large Bags
Aug 26, 2024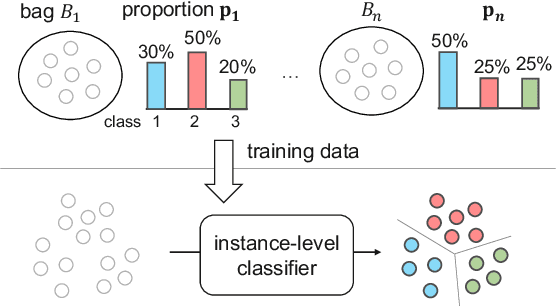

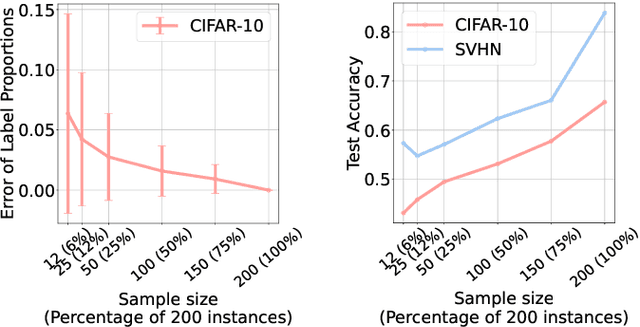
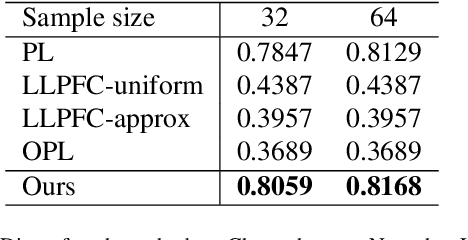
Learning from label proportions (LLP) is a kind of weakly supervised learning that trains an instance-level classifier from label proportions of bags, which consist of sets of instances without using instance labels. A challenge in LLP arises when the number of instances in a bag (bag size) is numerous, making the traditional LLP methods difficult due to GPU memory limitations. This study aims to develop an LLP method capable of learning from bags with large sizes. In our method, smaller bags (mini-bags) are generated by sampling instances from large-sized bags (original bags), and these mini-bags are used in place of the original bags. However, the proportion of a mini-bag is unknown and differs from that of the original bag, leading to overfitting. To address this issue, we propose a perturbation method for the proportion labels of sampled mini-bags to mitigate overfitting to noisy label proportions. This perturbation is added based on the multivariate hypergeometric distribution, which is statistically modeled. Additionally, loss weighting is implemented to reduce the negative impact of proportions sampled from the tail of the distribution. Experimental results demonstrate that the proportion label perturbation and loss weighting achieve classification accuracy comparable to that obtained without sampling. Our codes are available at https://github.com/stainlessnight/LLP-LargeBags.
Learning from Partial Label Proportions for Whole Slide Image Segmentation
May 15, 2024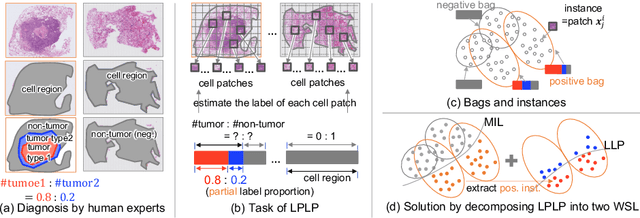

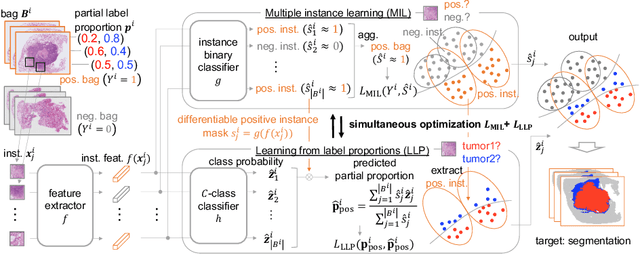
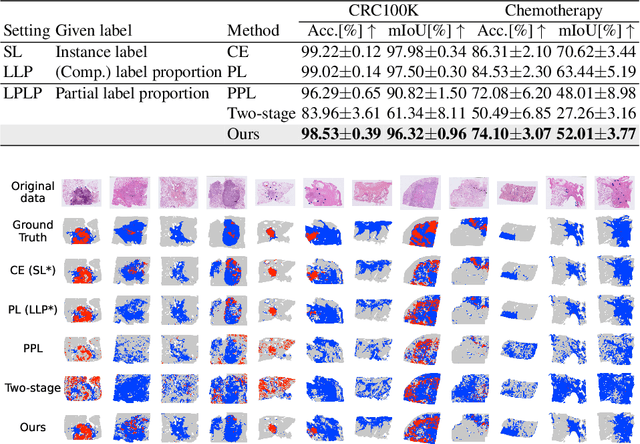
In this paper, we address the segmentation of tumor subtypes in whole slide images (WSI) by utilizing incomplete label proportions. Specifically, we utilize `partial' label proportions, which give the proportions among tumor subtypes but do not give the proportion between tumor and non-tumor. Partial label proportions are recorded as the standard diagnostic information by pathologists, and we, therefore, want to use them for realizing the segmentation model that can classify each WSI patch into one of the tumor subtypes or non-tumor. We call this problem ``learning from partial label proportions (LPLP)'' and formulate the problem as a weakly supervised learning problem. Then, we propose an efficient algorithm for this challenging problem by decomposing it into two weakly supervised learning subproblems: multiple instance learning (MIL) and learning from label proportions (LLP). These subproblems are optimized efficiently in the end-to-end manner. The effectiveness of our algorithm is demonstrated through experiments conducted on two WSI datasets.
Counting Network for Learning from Majority Label
Mar 20, 2024

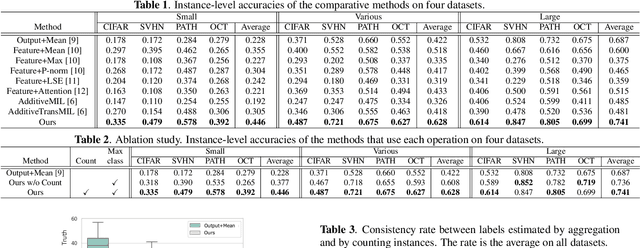
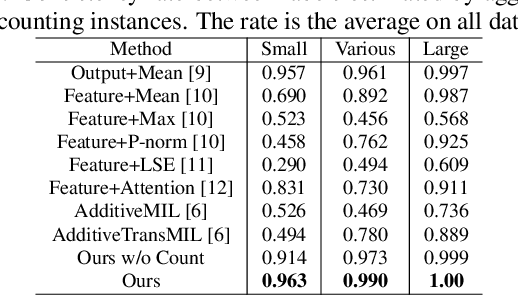
The paper proposes a novel problem in multi-class Multiple-Instance Learning (MIL) called Learning from the Majority Label (LML). In LML, the majority class of instances in a bag is assigned as the bag's label. LML aims to classify instances using bag-level majority classes. This problem is valuable in various applications. Existing MIL methods are unsuitable for LML due to aggregating confidences, which may lead to inconsistency between the bag-level label and the label obtained by counting the number of instances for each class. This may lead to incorrect instance-level classification. We propose a counting network trained to produce the bag-level majority labels estimated by counting the number of instances for each class. This led to the consistency of the majority class between the network outputs and one obtained by counting the number of instances. Experimental results show that our counting network outperforms conventional MIL methods on four datasets The code is publicly available at https://github.com/Shiku-Kaito/Counting-Network-for-Learning-from-Majority-Label.
Boosting for Bounding the Worst-class Error
Oct 20, 2023
This paper tackles the problem of the worst-class error rate, instead of the standard error rate averaged over all classes. For example, a three-class classification task with class-wise error rates of 10\%, 10\%, and 40\% has a worst-class error rate of 40\%, whereas the average is 20\% under the class-balanced condition. The worst-class error is important in many applications. For example, in a medical image classification task, it would not be acceptable for the malignant tumor class to have a 40\% error rate, while the benign and healthy classes have 10\% error rates.We propose a boosting algorithm that guarantees an upper bound of the worst-class training error and derive its generalization bound. Experimental results show that the algorithm lowers worst-class test error rates while avoiding overfitting to the training set.
MixBag: Bag-Level Data Augmentation for Learning from Label Proportions
Aug 17, 2023
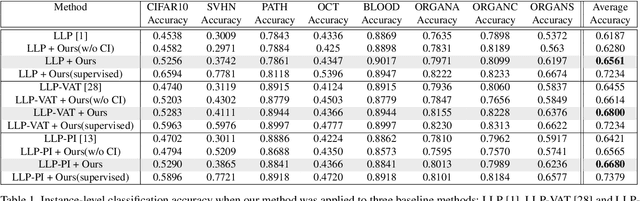

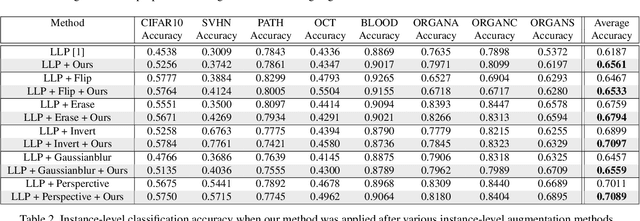
Learning from label proportions (LLP) is a promising weakly supervised learning problem. In LLP, a set of instances (bag) has label proportions, but no instance-level labels are given. LLP aims to train an instance-level classifier by using the label proportions of the bag. In this paper, we propose a bag-level data augmentation method for LLP called MixBag, based on the key observation from our preliminary experiments; that the instance-level classification accuracy improves as the number of labeled bags increases even though the total number of instances is fixed. We also propose a confidence interval loss designed based on statistical theory to use the augmented bags effectively. To the best of our knowledge, this is the first attempt to propose bag-level data augmentation for LLP. The advantage of MixBag is that it can be applied to instance-level data augmentation techniques and any LLP method that uses the proportion loss. Experimental results demonstrate this advantage and the effectiveness of our method.
Learning from Label Proportion with Online Pseudo-Label Decision by Regret Minimization
Feb 17, 2023This paper proposes a novel and efficient method for Learning from Label Proportions (LLP), whose goal is to train a classifier only by using the class label proportions of instance sets, called bags. We propose a novel LLP method based on an online pseudo-labeling method with regret minimization. As opposed to the previous LLP methods, the proposed method effectively works even if the bag sizes are large. We demonstrate the effectiveness of the proposed method using some benchmark datasets.
Revealing Reliable Signatures by Learning Top-Rank Pairs
Mar 17, 2022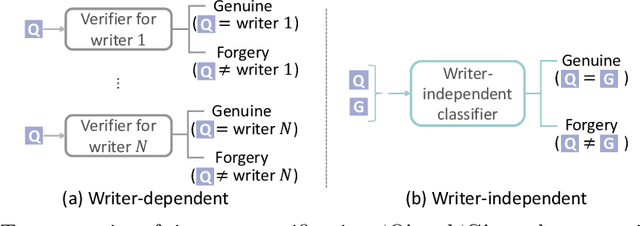
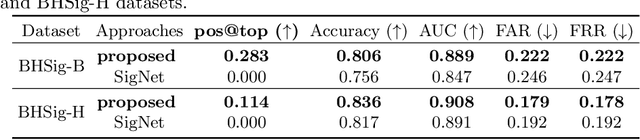
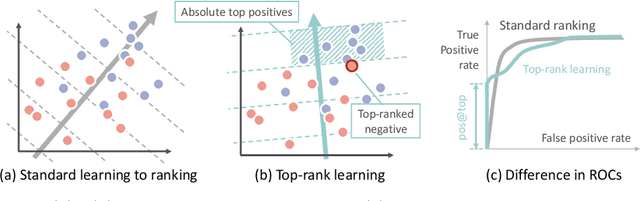
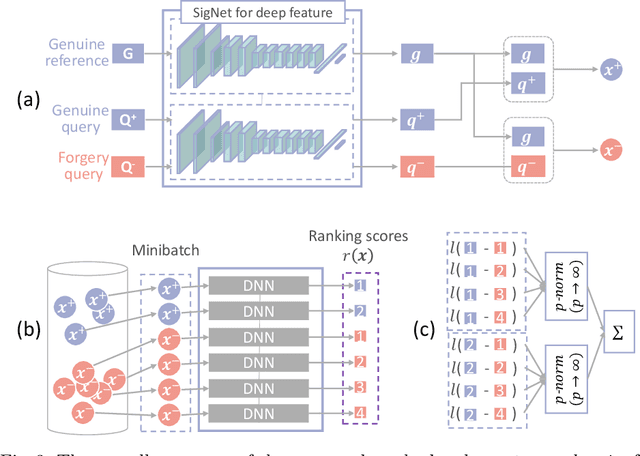
Signature verification, as a crucial practical documentation analysis task, has been continuously studied by researchers in machine learning and pattern recognition fields. In specific scenarios like confirming financial documents and legal instruments, ensuring the absolute reliability of signatures is of top priority. In this work, we proposed a new method to learn "top-rank pairs" for writer-independent offline signature verification tasks. By this scheme, it is possible to maximize the number of absolutely reliable signatures. More precisely, our method to learn top-rank pairs aims at pushing positive samples beyond negative samples, after pairing each of them with a genuine reference signature. In the experiment, BHSig-B and BHSig-H datasets are used for evaluation, on which the proposed model achieves overwhelming better pos@top (the ratio of absolute top positive samples to all of the positive samples) while showing encouraging performance on both Area Under the Curve (AUC) and accuracy.
Optimal Rejection Function Meets Character Recognition Tasks
Mar 17, 2022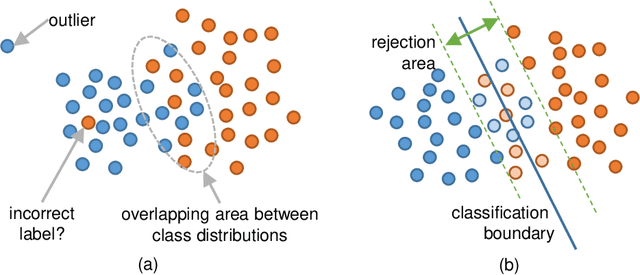
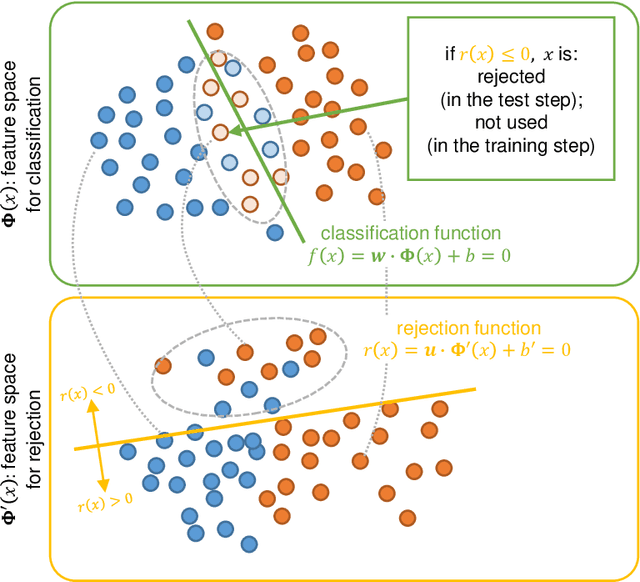


In this paper, we propose an optimal rejection method for rejecting ambiguous samples by a rejection function. This rejection function is trained together with a classification function under the framework of Learning-with-Rejection (LwR). The highlights of LwR are: (1) the rejection strategy is not heuristic but has a strong background from a machine learning theory, and (2) the rejection function can be trained on an arbitrary feature space which is different from the feature space for classification. The latter suggests we can choose a feature space that is more suitable for rejection. Although the past research on LwR focused only on its theoretical aspect, we propose to utilize LwR for practical pattern classification tasks. Moreover, we propose to use features from different CNN layers for classification and rejection. Our extensive experiments of notMNIST classification and character/non-character classification demonstrate that the proposed method achieves better performance than traditional rejection strategies.