 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGC-MoE: Genomics-Guided Cell-Type-Specific Mixture of Experts for Histology-Based Single-Cell Spatial Transcriptomics
Jun 01, 2026Histology-based single-cell spatial transcriptomics (ST) estimation aims to predict gene expression for individual cells from histopathological images and cell locations, reducing the need for costly single-cell ST measurements. Unlike existing histology-to-ST methods that mainly predict spot-level profiles for local regions containing multiple cells, this task requires modeling cell-to-cell expression variability, which is strongly structured by cell type. We propose Genomics-Guided Cell-Type-Specific Mixture-of-Experts (GC-MoE), which estimates cell-type probabilities with a routing network and softly combines cell-type-specific experts for gene expression prediction. To further encode cell-type-dependent gene programs, we introduce the Cell-Type-Specific Co-Expression-Aware Predictor (CAP), together with a lightweight Cell-to-Cell Interaction Attention (C2CA) module for neighboring-cell context. Experiments and ablations on public single-cell ST datasets show consistent improvements over existing single-cell and adapted spot-level baselines.
Leveraging Spatial Transcriptomics as Alternative to Manual Annotations for Deep Learning-Based Nuclei Analysis
Apr 26, 2026Deep learning-based nuclei segmentation and classification in pathology images typically rely on large-scale pixel-level manual annotations, which are costly and difficult to obtain across diverse tissues and staining conditions. To address this limitation, we propose a framework that leverages spatial transcriptomics (ST) data as supervision for nuclei segmentation and classification. By incorporating cell-level ST data, we obtain gene expression profiles and corresponding nuclear masks from histopathological images. Gene expression profiles are converted into cell-type labels and used as training data for image-based classification. Because existing gene expression-based cell-type classification methods are not designed for image recognition, we introduce an image-oriented classification approach that bridges gene expression-based cell typing and image-based cell classification. To evaluate generalization, we conduct segmentation experiments on previously unseen organs and compare our method with conventional supervised models. Despite being trained on fewer organ types, our framework achieves higher segmentation accuracy, demonstrating strong transferability. Classification experiments further show consistent improvements over existing approaches.
Cell Instance Segmentation via Multi-Task Image-to-Image Schrödinger Bridge
Apr 14, 2026Existing cell instance segmentation pipelines typically combine deterministic predictions with post-processing, which imposes limited explicit constraints on the global structure of instance masks. In this work, we propose a multi-task image-to-image Schrödinger Bridge framework that formulates instance segmentation as a distribution-based image-to-image generation problem. Boundary-aware supervision is integrated through a reverse distance map, and deterministic inference is employed to produce stable predictions. Experimental results on the PanNuke dataset demonstrate that the proposed method achieves competitive or superior performance without relying on SAM pre-training or additional post-processing. Additional results on the MoNuSeg dataset show robustness under limited training data. These findings indicate that Schrödinger Bridge-based image-to-image generation provides an effective framework for cell instance segmentation.
Ranking-Guided Semi-Supervised Domain Adaptation for Severity Classification
Apr 02, 2026Semi-supervised domain adaptation leverages a few labeled and many unlabeled target samples, making it promising for addressing domain shifts in medical image analysis. However, existing methods struggle with severity classification due to unclear class boundaries. Severity classification involves naturally ordered class labels, complicating adaptation. We propose a novel method that aligns source and target domains using rank scores learned via ranking with class order. Specifically, Cross-Domain Ranking ranks sample pairs across domains, while Continuous Distribution Alignment aligns rank score distributions. Experiments on ulcerative colitis and diabetic retinopathy classification validate the effectiveness of our approach, demonstrating successful alignment of class-specific rank score distributions.
Cell-Type Prototype-Informed Neural Network for Gene Expression Estimation from Pathology Images
Mar 19, 2026Estimating slide- and patch-level gene expression profiles from pathology images enables rapid and low-cost molecular analysis with broad clinical impact. Despite strong results, existing approaches treat gene expression as a mere slide- or spot-level signal and do not incorporate the fact that the measured expression arises from the aggregation of underlying cell-level expression. To explicitly introduce this missing cell-resolved guidance, we propose a Cell-type Prototype-informed Neural Network (CPNN) that leverages publicly available single-cell RNA-sequencing datasets. Since single-cell measurements are noisy and not paired with histology images, we first estimate cell-type prototypes-mean expression profiles that reflect stable gene-gene co-variation patterns.CPNN then learns cell-type compositional weights directly from images and models the relationship between prototypes and observed bulk or spatial expression, providing a biologically grounded and structurally regularized prediction framework. We evaluate CPNN on three slide-level datasets and three patch-level spatial transcriptomics datasets. Across all settings, CPNN achieves the highest performance in terms of Spearman correlation. Moreover, by visualizing the inferred compositional weights, our framework provides interpretable insights into which cell types drive the predicted expression. Code is publicly available at https://github.com/naivete5656/CPNN.
VesselFusion: Diffusion Models for Vessel Centerline Extraction from 3D CT Images
Mar 09, 2026Vessel centerline extraction from 3D CT images is an important task because it reduces annotation effort to build a model that estimates a vessel structure. It is challenging to estimate natural vessel structures since conventional approaches are deterministic models, which cannot capture a complex human structure. In this study, we propose VesselFusion, which is a diffusion model to extract the vessel centerline from 3D CT image. The proposed method uses a coarse-to-fine representation of the centerline and a voting-based aggregation for a natural and stable extraction. VesselFusion was evaluated on a publicly available CT image dataset and achieved higher extraction accuracy and a more natural result than conventional approaches.
Leveraging Label Proportion Prior for Class-Imbalanced Semi-Supervised Learning
Mar 03, 2026Semi-supervised learning (SSL) often suffers under class imbalance, where pseudo-labeling amplifies majority bias and suppresses minority performance. We address this issue with a lightweight framework that, to our knowledge, is the first to introduce Proportion Loss from learning from label proportions (LLP) into SSL as a regularization term. Proportion Loss aligns model predictions with the global class distribution, mitigating bias across both majority and minority classes. To further stabilize training, we formulate a stochastic variant that accounts for fluctuations in mini-batch composition. Experiments on the Long-tailed CIFAR-10 benchmark show that integrating Proportion Loss into FixMatch and ReMixMatch consistently improves performance over the baselines across imbalance severities and label ratios, and achieves competitive or superior results compared to existing CISSL methods, particularly under scarce-label conditions.
Hypernetwork-Based Adaptive Aggregation for Multimodal Multiple-Instance Learning in Predicting Coronary Calcium Debulking
Jan 29, 2026In this paper, we present the first attempt to estimate the necessity of debulking coronary artery calcifications from computed tomography (CT) images. We formulate this task as a Multiple-instance Learning (MIL) problem. The difficulty of this task lies in that physicians adjust their focus and decision criteria for device usage according to tabular data representing each patient's condition. To address this issue, we propose a hypernetwork-based adaptive aggregation transformer (HyperAdAgFormer), which adaptively modifies the feature aggregation strategy for each patient based on tabular data through a hypernetwork. The experiments using the clinical dataset demonstrated the effectiveness of HyperAdAgFormer. The code is publicly available at https://github.com/Shiku-Kaito/HyperAdAgFormer.
Domain Adaptation for Ulcerative Colitis Severity Estimation Using Patient-Level Diagnoses
Sep 18, 2025



The development of methods to estimate the severity of Ulcerative Colitis (UC) is of significant importance. However, these methods often suffer from domain shifts caused by differences in imaging devices and clinical settings across hospitals. Although several domain adaptation methods have been proposed to address domain shift, they still struggle with the lack of supervision in the target domain or the high cost of annotation. To overcome these challenges, we propose a novel Weakly Supervised Domain Adaptation method that leverages patient-level diagnostic results, which are routinely recorded in UC diagnosis, as weak supervision in the target domain. The proposed method aligns class-wise distributions across domains using Shared Aggregation Tokens and a Max-Severity Triplet Loss, which leverages the characteristic that patient-level diagnoses are determined by the most severe region within each patient. Experimental results demonstrate that our method outperforms comparative DA approaches, improving UC severity estimation in a domain-shifted setting.
Learning from Majority Label: A Novel Problem in Multi-class Multiple-Instance Learning
Sep 04, 2025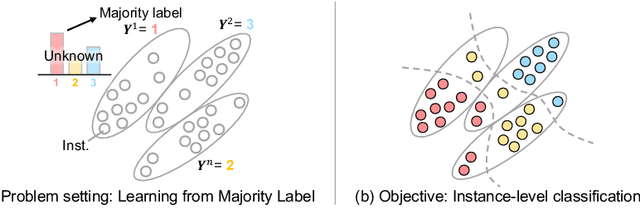
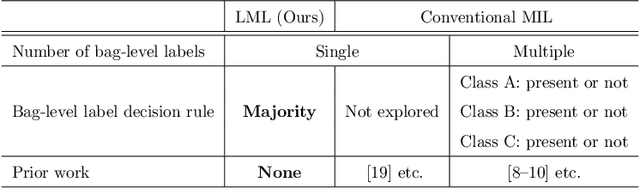

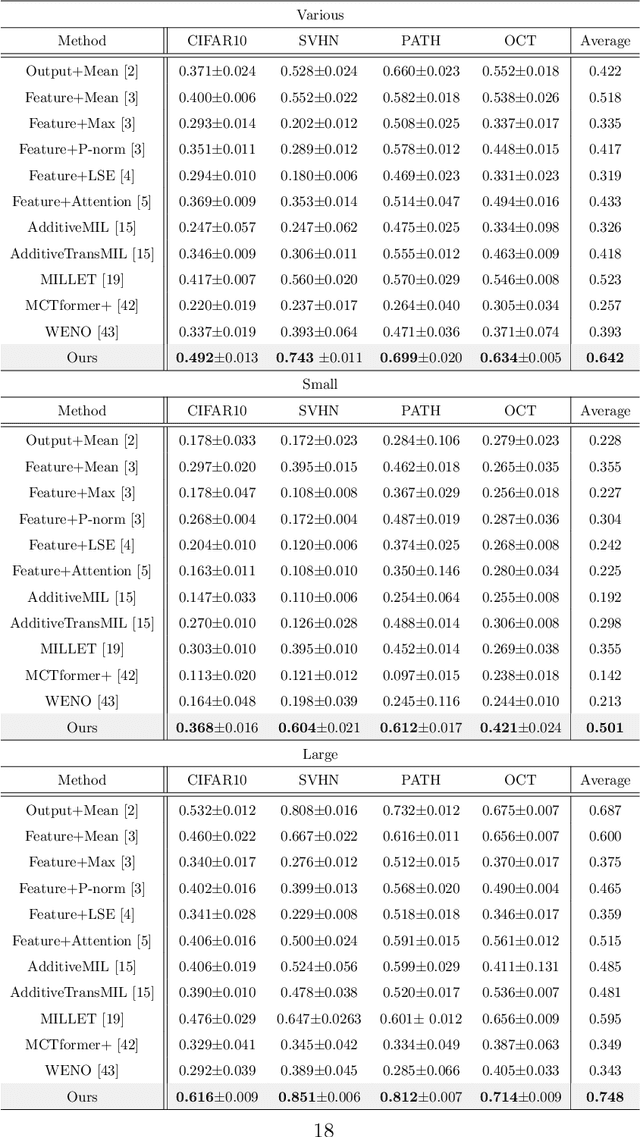
The paper proposes a novel multi-class Multiple-Instance Learning (MIL) problem called Learning from Majority Label (LML). In LML, the majority class of instances in a bag is assigned as the bag-level label. The goal of LML is to train a classification model that estimates the class of each instance using the majority label. This problem is valuable in a variety of applications, including pathology image segmentation, political voting prediction, customer sentiment analysis, and environmental monitoring. To solve LML, we propose a Counting Network trained to produce bag-level majority labels, estimated by counting the number of instances in each class. Furthermore, analysis experiments on the characteristics of LML revealed that bags with a high proportion of the majority class facilitate learning. Based on this result, we developed a Majority Proportion Enhancement Module (MPEM) that increases the proportion of the majority class by removing minority class instances within the bags. Experiments demonstrate the superiority of the proposed method on four datasets compared to conventional MIL methods. Moreover, ablation studies confirmed the effectiveness of each module. The code is available at \href{https://github.com/Shiku-Kaito/Learning-from-Majority-Label-A-Novel-Problem-in-Multi-class-Multiple-Instance-Learning}{here}.