 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Proportion Label Perturbation for Learning from Label Proportions in Large Bags
Aug 26, 2024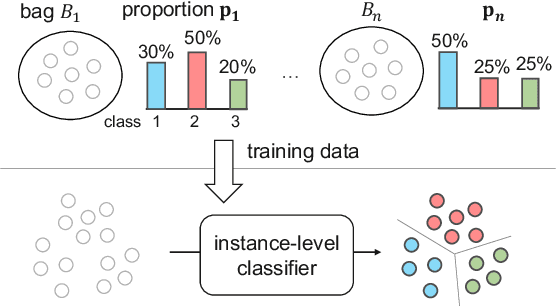

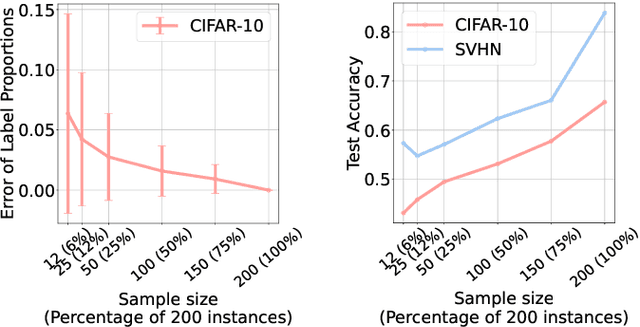
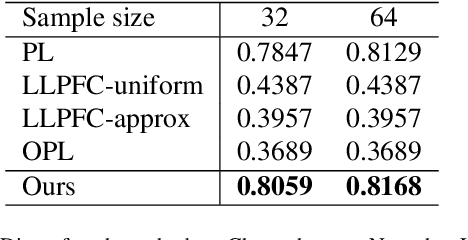
Learning from label proportions (LLP) is a kind of weakly supervised learning that trains an instance-level classifier from label proportions of bags, which consist of sets of instances without using instance labels. A challenge in LLP arises when the number of instances in a bag (bag size) is numerous, making the traditional LLP methods difficult due to GPU memory limitations. This study aims to develop an LLP method capable of learning from bags with large sizes. In our method, smaller bags (mini-bags) are generated by sampling instances from large-sized bags (original bags), and these mini-bags are used in place of the original bags. However, the proportion of a mini-bag is unknown and differs from that of the original bag, leading to overfitting. To address this issue, we propose a perturbation method for the proportion labels of sampled mini-bags to mitigate overfitting to noisy label proportions. This perturbation is added based on the multivariate hypergeometric distribution, which is statistically modeled. Additionally, loss weighting is implemented to reduce the negative impact of proportions sampled from the tail of the distribution. Experimental results demonstrate that the proportion label perturbation and loss weighting achieve classification accuracy comparable to that obtained without sampling. Our codes are available at https://github.com/stainlessnight/LLP-LargeBags.
Learning from Partial Label Proportions for Whole Slide Image Segmentation
May 15, 2024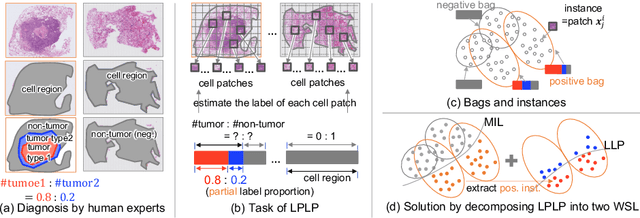

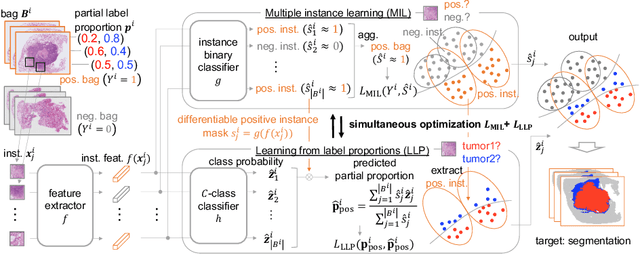
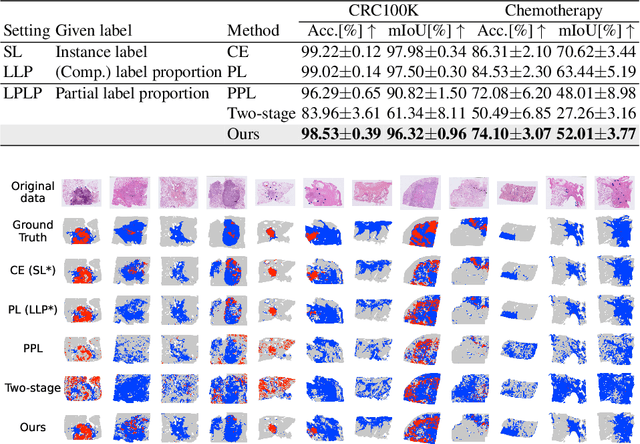
In this paper, we address the segmentation of tumor subtypes in whole slide images (WSI) by utilizing incomplete label proportions. Specifically, we utilize `partial' label proportions, which give the proportions among tumor subtypes but do not give the proportion between tumor and non-tumor. Partial label proportions are recorded as the standard diagnostic information by pathologists, and we, therefore, want to use them for realizing the segmentation model that can classify each WSI patch into one of the tumor subtypes or non-tumor. We call this problem ``learning from partial label proportions (LPLP)'' and formulate the problem as a weakly supervised learning problem. Then, we propose an efficient algorithm for this challenging problem by decomposing it into two weakly supervised learning subproblems: multiple instance learning (MIL) and learning from label proportions (LLP). These subproblems are optimized efficiently in the end-to-end manner. The effectiveness of our algorithm is demonstrated through experiments conducted on two WSI datasets.
Proportion Estimation by Masked Learning from Label Proportion
May 08, 2024The PD-L1 rate, the number of PD-L1 positive tumor cells over the total number of all tumor cells, is an important metric for immunotherapy. This metric is recorded as diagnostic information with pathological images. In this paper, we propose a proportion estimation method with a small amount of cell-level annotation and proportion annotation, which can be easily collected. Since the PD-L1 rate is calculated from only `tumor cells' and not using `non-tumor cells', we first detect tumor cells with a detection model. Then, we estimate the PD-L1 proportion by introducing a masking technique to `learning from label proportion.' In addition, we propose a weighted focal proportion loss to address data imbalance problems. Experiments using clinical data demonstrate the effectiveness of our method. Our method achieved the best performance in comparisons.
Multicoated and Folded Graph Neural Networks with Strong Lottery Tickets
Dec 06, 2023The Strong Lottery Ticket Hypothesis (SLTH) demonstrates the existence of high-performing subnetworks within a randomly initialized model, discoverable through pruning a convolutional neural network (CNN) without any weight training. A recent study, called Untrained GNNs Tickets (UGT), expanded SLTH from CNNs to shallow graph neural networks (GNNs). However, discrepancies persist when comparing baseline models with learned dense weights. Additionally, there remains an unexplored area in applying SLTH to deeper GNNs, which, despite delivering improved accuracy with additional layers, suffer from excessive memory requirements. To address these challenges, this work utilizes Multicoated Supermasks (M-Sup), a scalar pruning mask method, and implements it in GNNs by proposing a strategy for setting its pruning thresholds adaptively. In the context of deep GNNs, this research uncovers the existence of untrained recurrent networks, which exhibit performance on par with their trained feed-forward counterparts. This paper also introduces the Multi-Stage Folding and Unshared Masks methods to expand the search space in terms of both architecture and parameters. Through the evaluation of various datasets, including the Open Graph Benchmark (OGB), this work establishes a triple-win scenario for SLTH-based GNNs: by achieving high sparsity, competitive performance, and high memory efficiency with up to 98.7\% reduction, it demonstrates suitability for energy-efficient graph processing.
* 9 pages, accepted in the Second Learning on Graphs Conference (LoG 2023)
Listen to What You Want: Neural Network-based Universal Sound Selector
Jun 10, 2020



Being able to control the acoustic events (AEs) to which we want to listen would allow the development of more controllable hearable devices. This paper addresses the AE sound selection (or removal) problems, that we define as the extraction (or suppression) of all the sounds that belong to one or multiple desired AE classes. Although this problem could be addressed with a combination of source separation followed by AE classification, this is a sub-optimal way of solving the problem. Moreover, source separation usually requires knowing the maximum number of sources, which may not be practical when dealing with AEs. In this paper, we propose instead a universal sound selection neural network that enables to directly select AE sounds from a mixture given user-specified target AE classes. The proposed framework can be explicitly optimized to simultaneously select sounds from multiple desired AE classes, independently of the number of sources in the mixture. We experimentally show that the proposed method achieves promising AE sound selection performance and could be generalized to mixtures with a number of sources that are unseen during training.