 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCell-Type Prototype-Informed Neural Network for Gene Expression Estimation from Pathology Images
Mar 19, 2026Estimating slide- and patch-level gene expression profiles from pathology images enables rapid and low-cost molecular analysis with broad clinical impact. Despite strong results, existing approaches treat gene expression as a mere slide- or spot-level signal and do not incorporate the fact that the measured expression arises from the aggregation of underlying cell-level expression. To explicitly introduce this missing cell-resolved guidance, we propose a Cell-type Prototype-informed Neural Network (CPNN) that leverages publicly available single-cell RNA-sequencing datasets. Since single-cell measurements are noisy and not paired with histology images, we first estimate cell-type prototypes-mean expression profiles that reflect stable gene-gene co-variation patterns.CPNN then learns cell-type compositional weights directly from images and models the relationship between prototypes and observed bulk or spatial expression, providing a biologically grounded and structurally regularized prediction framework. We evaluate CPNN on three slide-level datasets and three patch-level spatial transcriptomics datasets. Across all settings, CPNN achieves the highest performance in terms of Spearman correlation. Moreover, by visualizing the inferred compositional weights, our framework provides interpretable insights into which cell types drive the predicted expression. Code is publicly available at https://github.com/naivete5656/CPNN.
Leveraging Label Proportion Prior for Class-Imbalanced Semi-Supervised Learning
Mar 03, 2026Semi-supervised learning (SSL) often suffers under class imbalance, where pseudo-labeling amplifies majority bias and suppresses minority performance. We address this issue with a lightweight framework that, to our knowledge, is the first to introduce Proportion Loss from learning from label proportions (LLP) into SSL as a regularization term. Proportion Loss aligns model predictions with the global class distribution, mitigating bias across both majority and minority classes. To further stabilize training, we formulate a stochastic variant that accounts for fluctuations in mini-batch composition. Experiments on the Long-tailed CIFAR-10 benchmark show that integrating Proportion Loss into FixMatch and ReMixMatch consistently improves performance over the baselines across imbalance severities and label ratios, and achieves competitive or superior results compared to existing CISSL methods, particularly under scarce-label conditions.
Learning from Majority Label: A Novel Problem in Multi-class Multiple-Instance Learning
Sep 04, 2025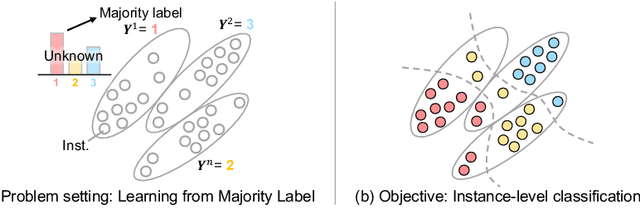
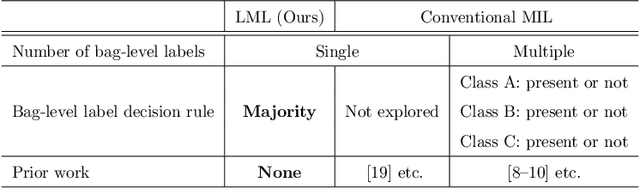

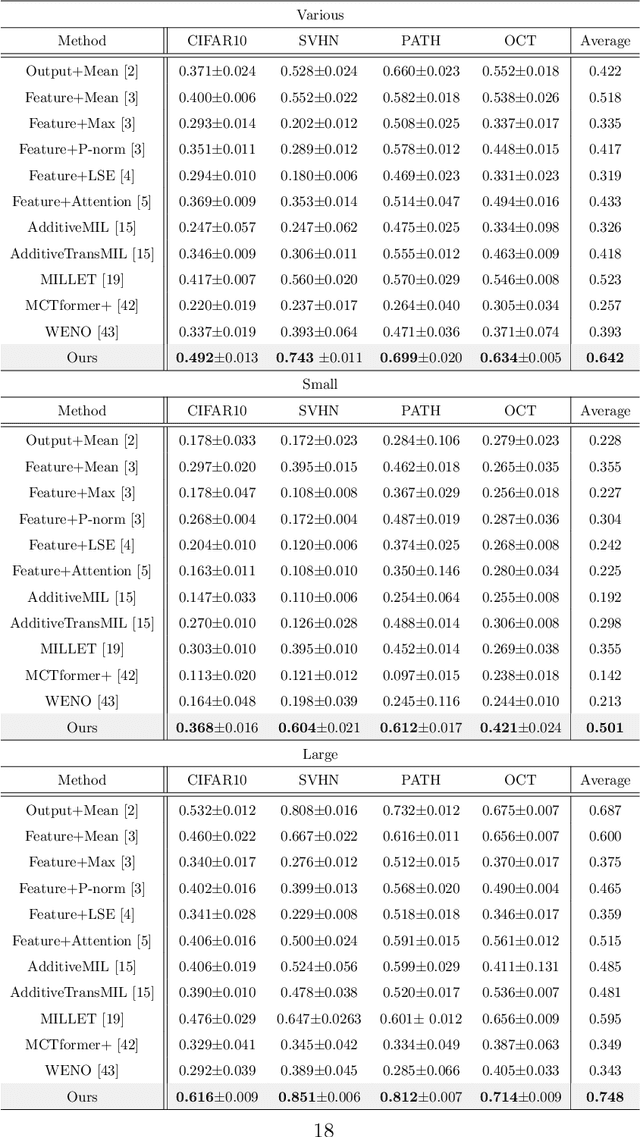
The paper proposes a novel multi-class Multiple-Instance Learning (MIL) problem called Learning from Majority Label (LML). In LML, the majority class of instances in a bag is assigned as the bag-level label. The goal of LML is to train a classification model that estimates the class of each instance using the majority label. This problem is valuable in a variety of applications, including pathology image segmentation, political voting prediction, customer sentiment analysis, and environmental monitoring. To solve LML, we propose a Counting Network trained to produce bag-level majority labels, estimated by counting the number of instances in each class. Furthermore, analysis experiments on the characteristics of LML revealed that bags with a high proportion of the majority class facilitate learning. Based on this result, we developed a Majority Proportion Enhancement Module (MPEM) that increases the proportion of the majority class by removing minority class instances within the bags. Experiments demonstrate the superiority of the proposed method on four datasets compared to conventional MIL methods. Moreover, ablation studies confirmed the effectiveness of each module. The code is available at \href{https://github.com/Shiku-Kaito/Learning-from-Majority-Label-A-Novel-Problem-in-Multi-class-Multiple-Instance-Learning}{here}.
Instance-wise Supervision-level Optimization in Active Learning
Mar 09, 2025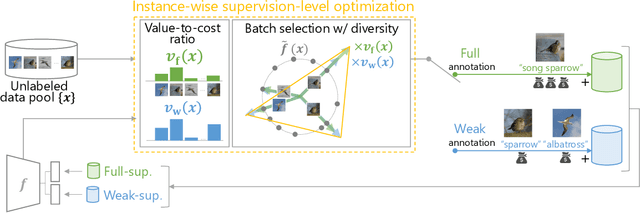

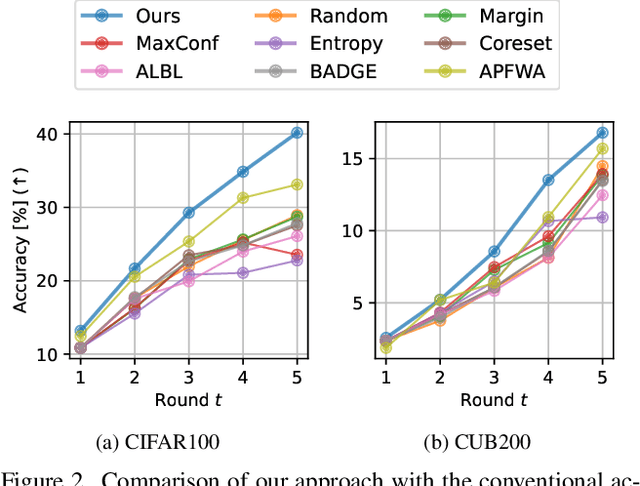
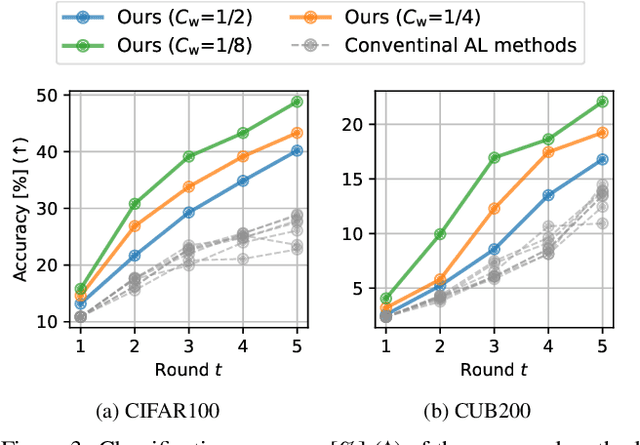
Active learning (AL) is a label-efficient machine learning paradigm that focuses on selectively annotating high-value instances to maximize learning efficiency. Its effectiveness can be further enhanced by incorporating weak supervision, which uses rough yet cost-effective annotations instead of exact (i.e., full) but expensive annotations. We introduce a novel AL framework, Instance-wise Supervision-Level Optimization (ISO), which not only selects the instances to annotate but also determines their optimal annotation level within a fixed annotation budget. Its optimization criterion leverages the value-to-cost ratio (VCR) of each instance while ensuring diversity among the selected instances. In classification experiments, ISO consistently outperforms traditional AL methods and surpasses a state-of-the-art AL approach that combines full and weak supervision, achieving higher accuracy at a lower overall cost. This code is available at https://github.com/matsuo-shinnosuke/ISOAL.
Theoretical Proportion Label Perturbation for Learning from Label Proportions in Large Bags
Aug 26, 2024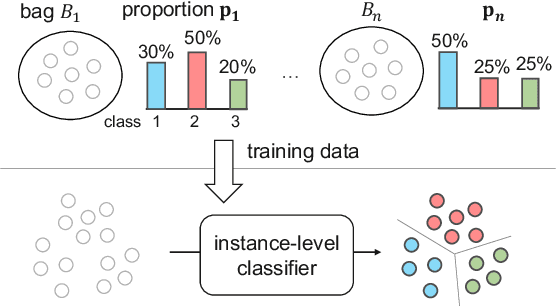

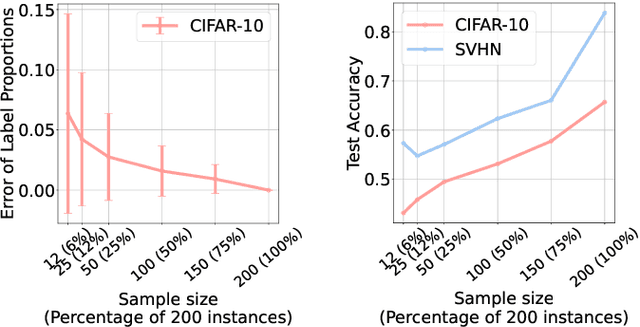
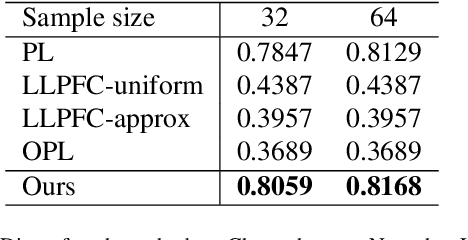
Learning from label proportions (LLP) is a kind of weakly supervised learning that trains an instance-level classifier from label proportions of bags, which consist of sets of instances without using instance labels. A challenge in LLP arises when the number of instances in a bag (bag size) is numerous, making the traditional LLP methods difficult due to GPU memory limitations. This study aims to develop an LLP method capable of learning from bags with large sizes. In our method, smaller bags (mini-bags) are generated by sampling instances from large-sized bags (original bags), and these mini-bags are used in place of the original bags. However, the proportion of a mini-bag is unknown and differs from that of the original bag, leading to overfitting. To address this issue, we propose a perturbation method for the proportion labels of sampled mini-bags to mitigate overfitting to noisy label proportions. This perturbation is added based on the multivariate hypergeometric distribution, which is statistically modeled. Additionally, loss weighting is implemented to reduce the negative impact of proportions sampled from the tail of the distribution. Experimental results demonstrate that the proportion label perturbation and loss weighting achieve classification accuracy comparable to that obtained without sampling. Our codes are available at https://github.com/stainlessnight/LLP-LargeBags.
Learning from Partial Label Proportions for Whole Slide Image Segmentation
May 15, 2024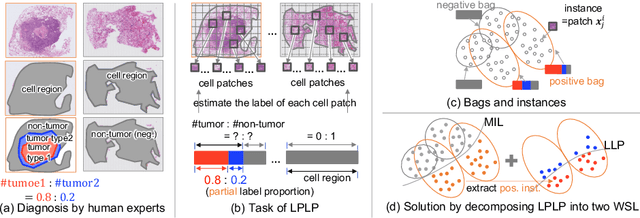

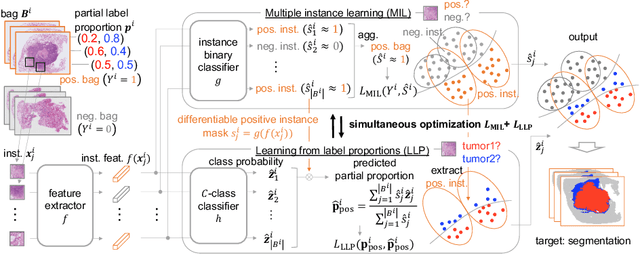
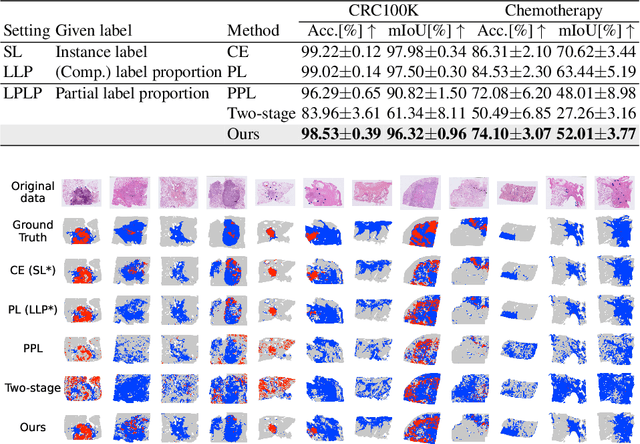
In this paper, we address the segmentation of tumor subtypes in whole slide images (WSI) by utilizing incomplete label proportions. Specifically, we utilize `partial' label proportions, which give the proportions among tumor subtypes but do not give the proportion between tumor and non-tumor. Partial label proportions are recorded as the standard diagnostic information by pathologists, and we, therefore, want to use them for realizing the segmentation model that can classify each WSI patch into one of the tumor subtypes or non-tumor. We call this problem ``learning from partial label proportions (LPLP)'' and formulate the problem as a weakly supervised learning problem. Then, we propose an efficient algorithm for this challenging problem by decomposing it into two weakly supervised learning subproblems: multiple instance learning (MIL) and learning from label proportions (LLP). These subproblems are optimized efficiently in the end-to-end manner. The effectiveness of our algorithm is demonstrated through experiments conducted on two WSI datasets.
Test-Time Augmentation for Traveling Salesperson Problem
May 08, 2024
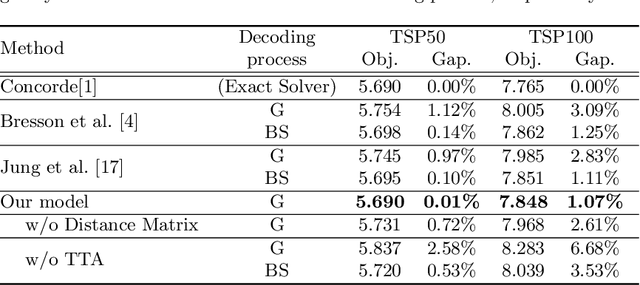
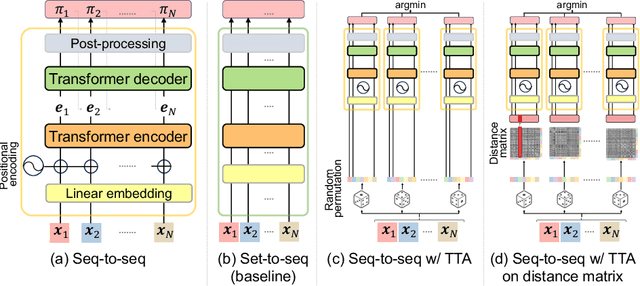
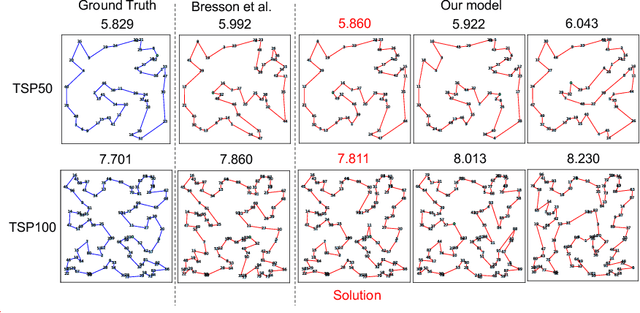
We propose Test-Time Augmentation (TTA) as an effective technique for addressing combinatorial optimization problems, including the Traveling Salesperson Problem. In general, deep learning models possessing the property of invariance, where the output is uniquely determined regardless of the node indices, have been proposed to learn graph structures efficiently. In contrast, we interpret the permutation of node indices, which exchanges the elements of the distance matrix, as a TTA scheme. The results demonstrate that our method is capable of obtaining shorter solutions than the latest models. Furthermore, we show that the probability of finding a solution closer to an exact solution increases depending on the augmentation size.
Counting Network for Learning from Majority Label
Mar 20, 2024

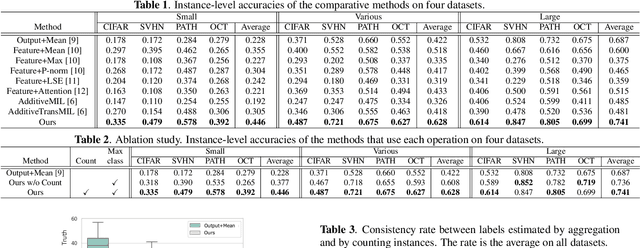
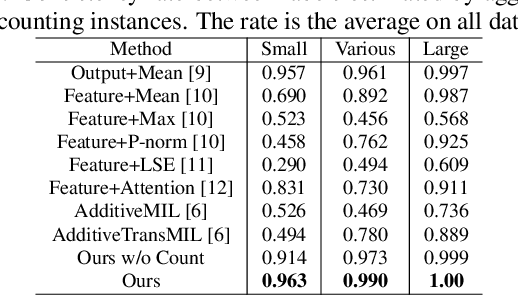
The paper proposes a novel problem in multi-class Multiple-Instance Learning (MIL) called Learning from the Majority Label (LML). In LML, the majority class of instances in a bag is assigned as the bag's label. LML aims to classify instances using bag-level majority classes. This problem is valuable in various applications. Existing MIL methods are unsuitable for LML due to aggregating confidences, which may lead to inconsistency between the bag-level label and the label obtained by counting the number of instances for each class. This may lead to incorrect instance-level classification. We propose a counting network trained to produce the bag-level majority labels estimated by counting the number of instances for each class. This led to the consistency of the majority class between the network outputs and one obtained by counting the number of instances. Experimental results show that our counting network outperforms conventional MIL methods on four datasets The code is publicly available at https://github.com/Shiku-Kaito/Counting-Network-for-Learning-from-Majority-Label.
Boosting for Bounding the Worst-class Error
Oct 20, 2023
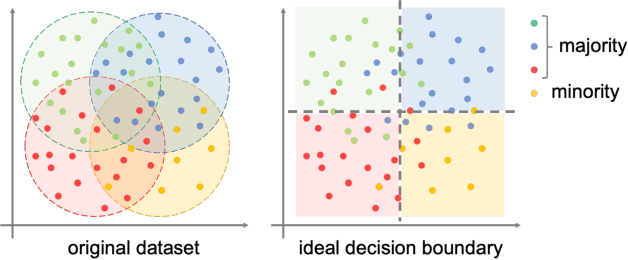
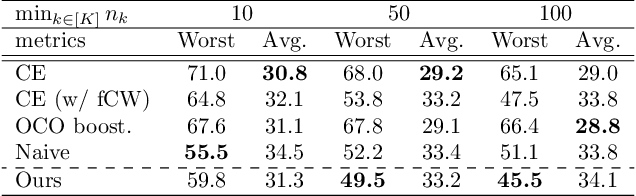
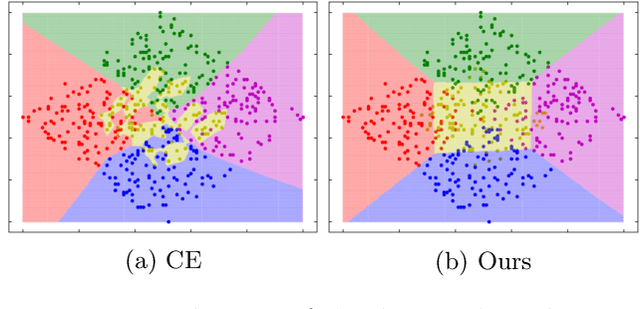
This paper tackles the problem of the worst-class error rate, instead of the standard error rate averaged over all classes. For example, a three-class classification task with class-wise error rates of 10\%, 10\%, and 40\% has a worst-class error rate of 40\%, whereas the average is 20\% under the class-balanced condition. The worst-class error is important in many applications. For example, in a medical image classification task, it would not be acceptable for the malignant tumor class to have a 40\% error rate, while the benign and healthy classes have 10\% error rates.We propose a boosting algorithm that guarantees an upper bound of the worst-class training error and derive its generalization bound. Experimental results show that the algorithm lowers worst-class test error rates while avoiding overfitting to the training set.
Deep Attentive Time Warping
Sep 13, 2023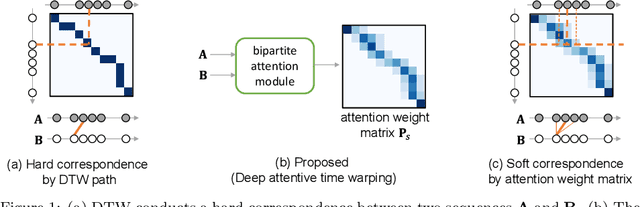
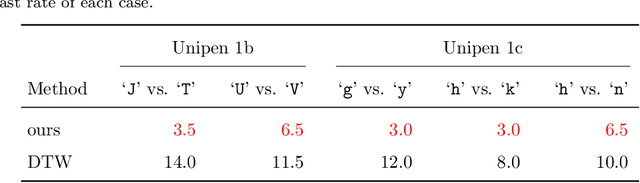
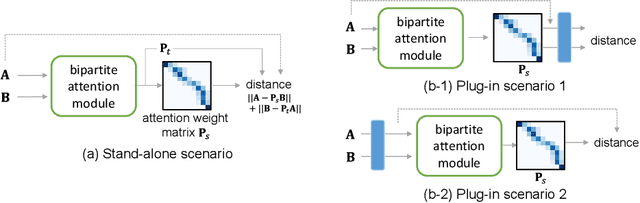
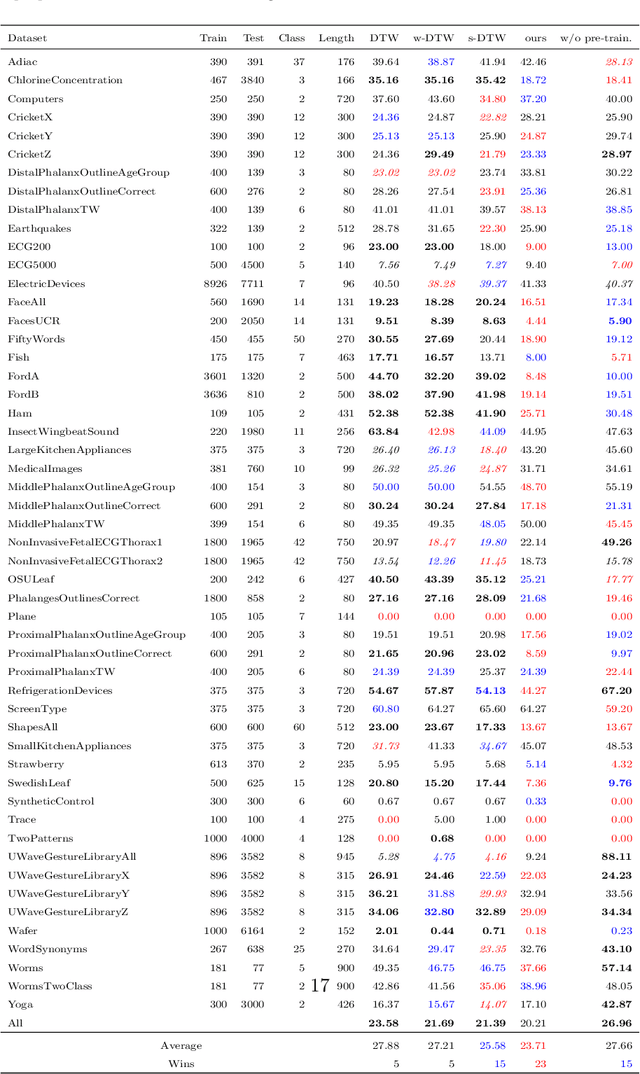
Similarity measures for time series are important problems for time series classification. To handle the nonlinear time distortions, Dynamic Time Warping (DTW) has been widely used. However, DTW is not learnable and suffers from a trade-off between robustness against time distortion and discriminative power. In this paper, we propose a neural network model for task-adaptive time warping. Specifically, we use the attention model, called the bipartite attention model, to develop an explicit time warping mechanism with greater distortion invariance. Unlike other learnable models using DTW for warping, our model predicts all local correspondences between two time series and is trained based on metric learning, which enables it to learn the optimal data-dependent warping for the target task. We also propose to induce pre-training of our model by DTW to improve the discriminative power. Extensive experiments demonstrate the superior effectiveness of our model over DTW and its state-of-the-art performance in online signature verification.