 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generalization Bounds of Symbolic Regression with Genetic Programming
Apr 19, 2026Symbolic regression (SR) with genetic programming (GP) aims to discover interpretable mathematical expressions directly from data. Despite its strong empirical success, the theoretical understanding of why GP-based SR generalizes beyond the training data remains limited. In this work, we provide a learning-theoretic analysis of SR models represented as expression trees. We derive a generalization bound for GP-style SR under constraints on tree size, depth, and learnable constants. Our result decomposes the generalization gap into two interpretable components: a structure-selection term, reflecting the combinatorial complexity of choosing an expression-tree structure, and a constant-fitting term, capturing the complexity of optimizing numerical constants within a fixed structure. This decomposition provides a theoretical perspective on several widely used practices in GP, including parsimony pressure, depth limits, numerically stable operators, and interval arithmetic. In particular, our analysis shows how structural restrictions reduce hypothesis-class growth while stability mechanisms control the sensitivity of predictions to parameter perturbations. By linking these practical design choices to explicit complexity terms in the generalization bound, our work offers a principled explanation for commonly observed empirical behaviors in GP-based SR and contributes towards a more rigorous understanding of its generalization properties.
Takeuchi's Information Criteria as Generalization Measures for DNNs Close to NTK Regime
Feb 26, 2026Generalization measures have been studied extensively in the machine learning community to better characterize generalization gaps. However, establishing a reliable generalization measure for statistically singular models such as deep neural networks (DNNs) is difficult due to their complex nature. This study focuses on Takeuchi's information criterion (TIC) to investigate the conditions under which this classical measure can effectively explain the generalization gaps of DNNs. Importantly, the developed theory indicates the applicability of TIC near the neural tangent kernel (NTK) regime. In a series of experiments, we trained more than 5,000 DNN models with 12 architectures, including large models (e.g., VGG-16), on four datasets, and estimated the corresponding TIC values to examine the relationship between the generalization gap and the TIC estimates. We applied several TIC approximation methods with feasible computational costs and assessed the accuracy trade-off. Our experimental results indicate that the estimated TIC values correlate well with the generalization gap under conditions close to the NTK regime. However, we show both theoretically and empirically that outside the NTK regime such correlation disappears. Finally, we demonstrate that TIC provides better trial pruning ability than existing methods for hyperparameter optimization.
Beyond Match Maximization and Fairness: Retention-Optimized Two-Sided Matching
Feb 17, 2026On two-sided matching platforms such as online dating and recruiting, recommendation algorithms often aim to maximize the total number of matches. However, this objective creates an imbalance, where some users receive far too many matches while many others receive very few and eventually abandon the platform. Retaining users is crucial for many platforms, such as those that depend heavily on subscriptions. Some may use fairness objectives to solve the problem of match maximization. However, fairness in itself is not the ultimate objective for many platforms, as users do not suddenly reward the platform simply because exposure is equalized. In practice, where user retention is often the ultimate goal, casually relying on fairness will leave the optimization of retention up to luck. In this work, instead of maximizing matches or axiomatically defining fairness, we formally define the new problem setting of maximizing user retention in two-sided matching platforms. To this end, we introduce a dynamic learning-to-rank (LTR) algorithm called Matching for Retention (MRet). Unlike conventional algorithms for two-sided matching, our approach models user retention by learning personalized retention curves from each user's profile and interaction history. Based on these curves, MRet dynamically adapts recommendations by jointly considering the retention gains of both the user receiving recommendations and those who are being recommended, so that limited matching opportunities can be allocated where they most improve overall retention. Naturally but importantly, empirical evaluations on synthetic and real-world datasets from a major online dating platform show that MRet achieves higher user retention, since conventional methods optimize matches or fairness rather than retention.
Multi-start Optimization Method via Scalarization based on Target Point-based Tchebycheff Distance for Multi-objective Optimization
May 02, 2025Multi-objective optimization is crucial in scientific and industrial applications where solutions must balance trade-offs among conflicting objectives. State-of-the-art methods, such as NSGA-III and MOEA/D, can handle many objectives but struggle with coverage issues, particularly in cases involving inverted triangular Pareto fronts or strong nonlinearity. Moreover, NSGA-III often relies on simulated binary crossover, which deteriorates in problems with variable dependencies. In this study, we propose a novel multi-start optimization method that addresses these challenges. Our approach introduces a newly introduced scalarization technique, the Target Point-based Tchebycheff Distance (TPTD) method, which significantly improves coverage on problems with inverted triangular Pareto fronts. For efficient multi-start optimization, TPTD leverages a target point defined in the objective space, which plays a critical role in shaping the scalarized function. The position of the target point is adaptively determined according to the shape of the Pareto front, ensuring improvement in coverage. Furthermore, the flexibility of this scalarization allows seamless integration with powerful single-objective optimization methods, such as natural evolution strategies, to efficiently handle variable dependencies. Experimental results on benchmark problems, including those with inverted triangular Pareto fronts, demonstrate that our method outperforms NSGA-II, NSGA-III, and MOEA/D-DE in terms of the Hypervolume indicator. Notably, our approach achieves computational efficiency improvements of up to 474 times over these baselines.
A Memetic Algorithm based on Variational Autoencoder for Black-Box Discrete Optimization with Epistasis among Parameters
Apr 30, 2025

Black-box discrete optimization (BB-DO) problems arise in many real-world applications, such as neural architecture search and mathematical model estimation. A key challenge in BB-DO is epistasis among parameters where multiple variables must be modified simultaneously to effectively improve the objective function. Estimation of Distribution Algorithms (EDAs) provide a powerful framework for tackling BB-DO problems. In particular, an EDA leveraging a Variational Autoencoder (VAE) has demonstrated strong performance on relatively low-dimensional problems with epistasis while reducing computational cost. Meanwhile, evolutionary algorithms such as DSMGA-II and P3, which integrate bit-flip-based local search with linkage learning, have shown excellent performance on high-dimensional problems. In this study, we propose a new memetic algorithm that combines VAE-based sampling with local search. The proposed method inherits the strengths of both VAE-based EDAs and local search-based approaches: it effectively handles high-dimensional problems with epistasis among parameters without incurring excessive computational overhead. Experiments on NK landscapes -- a challenging benchmark for BB-DO involving epistasis among parameters -- demonstrate that our method outperforms state-of-the-art VAE-based EDA methods, as well as leading approaches such as P3 and DSMGA-II.
CatCMA with Margin: Stochastic Optimization for Continuous, Integer, and Categorical Variables
Apr 10, 2025This study focuses on mixed-variable black-box optimization (MV-BBO), addressing continuous, integer, and categorical variables. Many real-world MV-BBO problems involve dependencies among these different types of variables, requiring efficient methods to optimize them simultaneously. Recently, stochastic optimization methods leveraging the mechanism of the covariance matrix adaptation evolution strategy have shown promising results in mixed-integer or mixed-category optimization. However, such methods cannot handle the three types of variables simultaneously. In this study, we propose CatCMA with Margin (CatCMAwM), a stochastic optimization method for MV-BBO that jointly optimizes continuous, integer, and categorical variables. CatCMAwM is developed by incorporating a novel integer handling into CatCMA, a mixed-category black-box optimization method employing a joint distribution of multivariate Gaussian and categorical distributions. The proposed integer handling is carefully designed by reviewing existing integer handlings and following the design principles of CatCMA. Even when applied to mixed-integer problems, it stabilizes the marginal probability and improves the convergence performance of continuous variables. Numerical experiments show that CatCMAwM effectively handles the three types of variables, outperforming state-of-the-art Bayesian optimization methods and baselines that simply incorporate existing integer handlings into CatCMA.
Instance-wise Supervision-level Optimization in Active Learning
Mar 09, 2025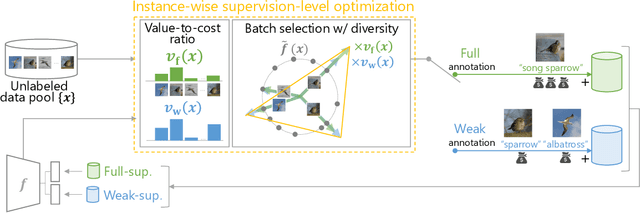

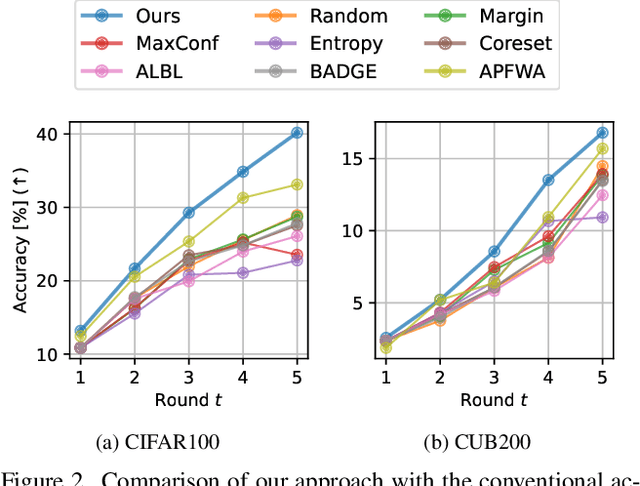
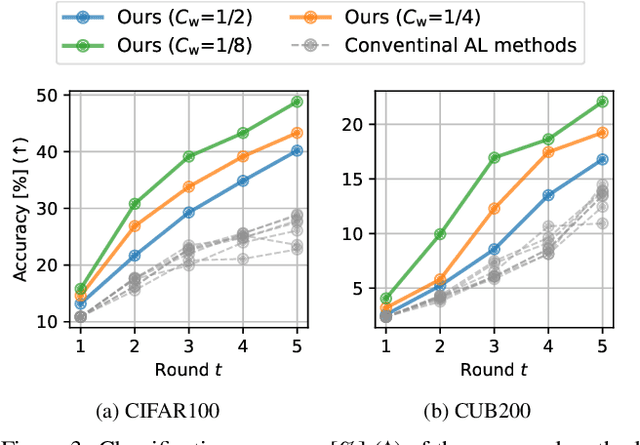
Active learning (AL) is a label-efficient machine learning paradigm that focuses on selectively annotating high-value instances to maximize learning efficiency. Its effectiveness can be further enhanced by incorporating weak supervision, which uses rough yet cost-effective annotations instead of exact (i.e., full) but expensive annotations. We introduce a novel AL framework, Instance-wise Supervision-Level Optimization (ISO), which not only selects the instances to annotate but also determines their optimal annotation level within a fixed annotation budget. Its optimization criterion leverages the value-to-cost ratio (VCR) of each instance while ensuring diversity among the selected instances. In classification experiments, ISO consistently outperforms traditional AL methods and surpasses a state-of-the-art AL approach that combines full and weak supervision, achieving higher accuracy at a lower overall cost. This code is available at https://github.com/matsuo-shinnosuke/ISOAL.
Harnessing the Latent Diffusion Model for Training-Free Image Style Transfer
Oct 02, 2024



Diffusion models have recently shown the ability to generate high-quality images. However, controlling its generation process still poses challenges. The image style transfer task is one of those challenges that transfers the visual attributes of a style image to another content image. Typical obstacle of this task is the requirement of additional training of a pre-trained model. We propose a training-free style transfer algorithm, Style Tracking Reverse Diffusion Process (STRDP) for a pretrained Latent Diffusion Model (LDM). Our algorithm employs Adaptive Instance Normalization (AdaIN) function in a distinct manner during the reverse diffusion process of an LDM while tracking the encoding history of the style image. This algorithm enables style transfer in the latent space of LDM for reduced computational cost, and provides compatibility for various LDM models. Through a series of experiments and a user study, we show that our method can quickly transfer the style of an image without additional training. The speed, compatibility, and training-free aspect of our algorithm facilitates agile experiments with combinations of styles and LDMs for extensive application.
CMA-ES for Discrete and Mixed-Variable Optimization on Sets of Points
Aug 23, 2024Discrete and mixed-variable optimization problems have appeared in several real-world applications. Most of the research on mixed-variable optimization considers a mixture of integer and continuous variables, and several integer handlings have been developed to inherit the optimization performance of the continuous optimization methods to mixed-integer optimization. In some applications, acceptable solutions are given by selecting possible points in the disjoint subspaces. This paper focuses on the optimization on sets of points and proposes an optimization method by extending the covariance matrix adaptation evolution strategy (CMA-ES), termed the CMA-ES on sets of points (CMA-ES-SoP). The CMA-ES-SoP incorporates margin correction that maintains the generation probability of neighboring points to prevent premature convergence to a specific non-optimal point, which is an effective integer-handling technique for CMA-ES. In addition, because margin correction with a fixed margin value tends to increase the marginal probabilities for a portion of neighboring points more than necessary, the CMA-ES-SoP updates the target margin value adaptively to make the average of the marginal probabilities close to a predefined target probability. Numerical simulations demonstrated that the CMA-ES-SoP successfully optimized the optimization problems on sets of points, whereas the naive CMA-ES failed to optimize them due to premature convergence.
Effective Off-Policy Evaluation and Learning in Contextual Combinatorial Bandits
Aug 20, 2024
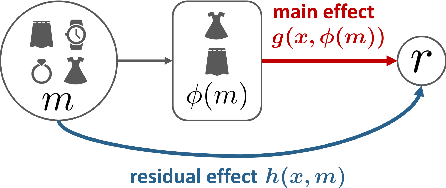
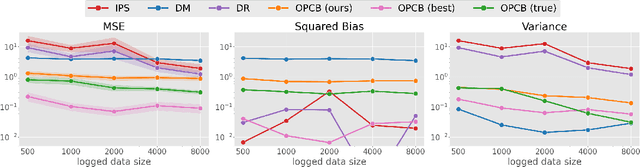
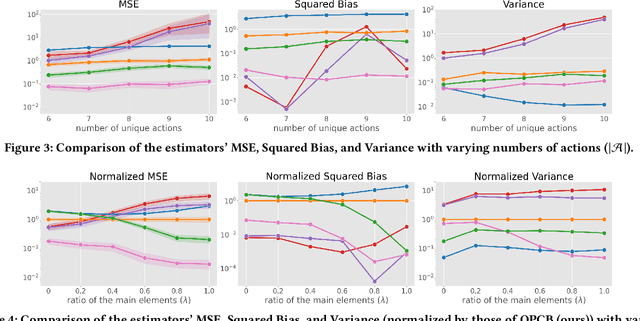
We explore off-policy evaluation and learning (OPE/L) in contextual combinatorial bandits (CCB), where a policy selects a subset in the action space. For example, it might choose a set of furniture pieces (a bed and a drawer) from available items (bed, drawer, chair, etc.) for interior design sales. This setting is widespread in fields such as recommender systems and healthcare, yet OPE/L of CCB remains unexplored in the relevant literature. Typical OPE/L methods such as regression and importance sampling can be applied to the CCB problem, however, they face significant challenges due to high bias or variance, exacerbated by the exponential growth in the number of available subsets. To address these challenges, we introduce a concept of factored action space, which allows us to decompose each subset into binary indicators. This formulation allows us to distinguish between the ''main effect'' derived from the main actions, and the ''residual effect'', originating from the supplemental actions, facilitating more effective OPE. Specifically, our estimator, called OPCB, leverages an importance sampling-based approach to unbiasedly estimate the main effect, while employing regression-based approach to deal with the residual effect with low variance. OPCB achieves substantial variance reduction compared to conventional importance sampling methods and bias reduction relative to regression methods under certain conditions, as illustrated in our theoretical analysis. Experiments demonstrate OPCB's superior performance over typical methods in both OPE and OPL.