 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Off-Policy Evaluation and Learning in Contextual Combinatorial Bandits
Aug 20, 2024
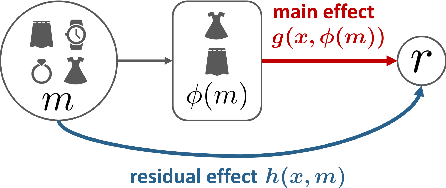
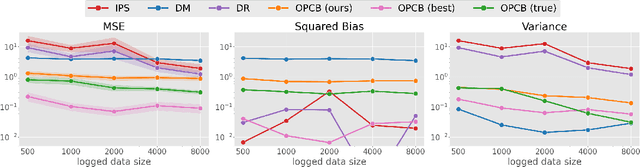
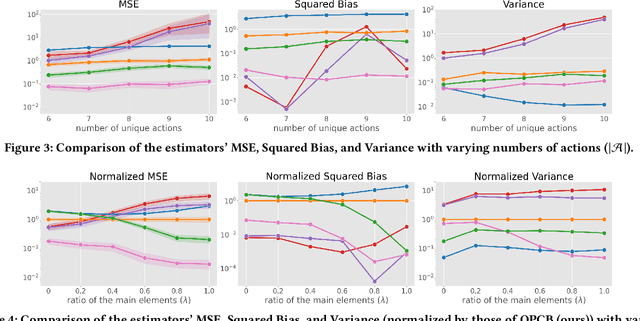
We explore off-policy evaluation and learning (OPE/L) in contextual combinatorial bandits (CCB), where a policy selects a subset in the action space. For example, it might choose a set of furniture pieces (a bed and a drawer) from available items (bed, drawer, chair, etc.) for interior design sales. This setting is widespread in fields such as recommender systems and healthcare, yet OPE/L of CCB remains unexplored in the relevant literature. Typical OPE/L methods such as regression and importance sampling can be applied to the CCB problem, however, they face significant challenges due to high bias or variance, exacerbated by the exponential growth in the number of available subsets. To address these challenges, we introduce a concept of factored action space, which allows us to decompose each subset into binary indicators. This formulation allows us to distinguish between the ''main effect'' derived from the main actions, and the ''residual effect'', originating from the supplemental actions, facilitating more effective OPE. Specifically, our estimator, called OPCB, leverages an importance sampling-based approach to unbiasedly estimate the main effect, while employing regression-based approach to deal with the residual effect with low variance. OPCB achieves substantial variance reduction compared to conventional importance sampling methods and bias reduction relative to regression methods under certain conditions, as illustrated in our theoretical analysis. Experiments demonstrate OPCB's superior performance over typical methods in both OPE and OPL.
SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation
Dec 04, 2023
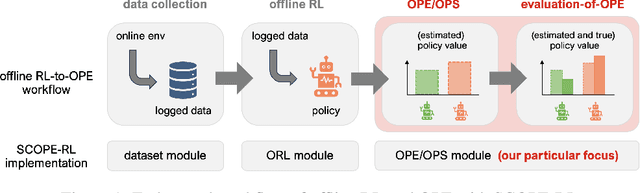
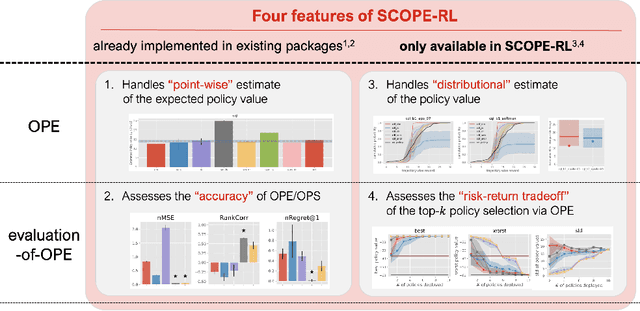

This paper introduces SCOPE-RL, a comprehensive open-source Python software designed for offline reinforcement learning (offline RL), off-policy evaluation (OPE), and selection (OPS). Unlike most existing libraries that focus solely on either policy learning or evaluation, SCOPE-RL seamlessly integrates these two key aspects, facilitating flexible and complete implementations of both offline RL and OPE processes. SCOPE-RL put particular emphasis on its OPE modules, offering a range of OPE estimators and robust evaluation-of-OPE protocols. This approach enables more in-depth and reliable OPE compared to other packages. For instance, SCOPE-RL enhances OPE by estimating the entire reward distribution under a policy rather than its mere point-wise expected value. Additionally, SCOPE-RL provides a more thorough evaluation-of-OPE by presenting the risk-return tradeoff in OPE results, extending beyond mere accuracy evaluations in existing OPE literature. SCOPE-RL is designed with user accessibility in mind. Its user-friendly APIs, comprehensive documentation, and a variety of easy-to-follow examples assist researchers and practitioners in efficiently implementing and experimenting with various offline RL methods and OPE estimators, tailored to their specific problem contexts. The documentation of SCOPE-RL is available at https://scope-rl.readthedocs.io/en/latest/.
Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation
Dec 04, 2023
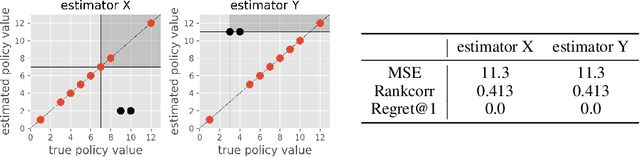
Off-Policy Evaluation (OPE) aims to assess the effectiveness of counterfactual policies using only offline logged data and is often used to identify the top-k promising policies for deployment in online A/B tests. Existing evaluation metrics for OPE estimators primarily focus on the "accuracy" of OPE or that of downstream policy selection, neglecting risk-return tradeoff in the subsequent online policy deployment. To address this issue, we draw inspiration from portfolio evaluation in finance and develop a new metric, called SharpeRatio@k, which measures the risk-return tradeoff of policy portfolios formed by an OPE estimator under varying online evaluation budgets (k). We validate our metric in two example scenarios, demonstrating its ability to effectively distinguish between low-risk and high-risk estimators and to accurately identify the most efficient estimator. This efficient estimator is characterized by its capability to form the most advantageous policy portfolios, maximizing returns while minimizing risks during online deployment, a nuance that existing metrics typically overlook. To facilitate a quick, accurate, and consistent evaluation of OPE via SharpeRatio@k, we have also integrated this metric into an open-source software, SCOPE-RL. Employing SharpeRatio@k and SCOPE-RL, we conduct comprehensive benchmarking experiments on various estimators and RL tasks, focusing on their risk-return tradeoff. These experiments offer several interesting directions and suggestions for future OPE research.