 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Off-Policy Evaluation and Learning in Contextual Combinatorial Bandits
Aug 20, 2024
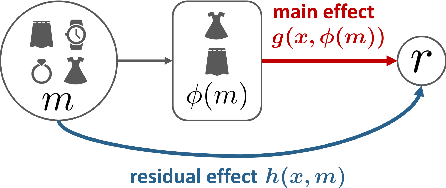
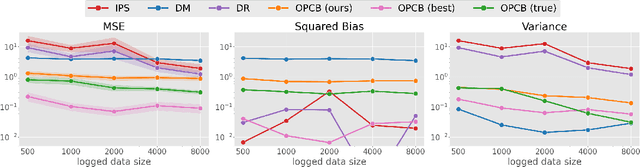
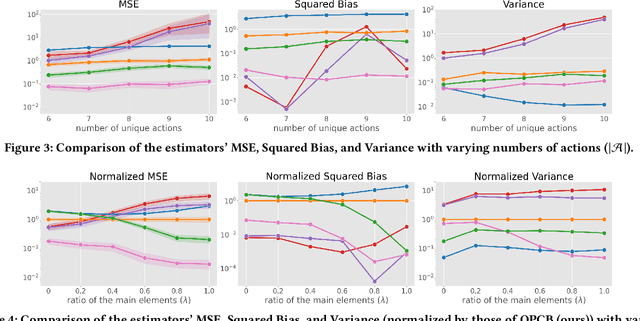
We explore off-policy evaluation and learning (OPE/L) in contextual combinatorial bandits (CCB), where a policy selects a subset in the action space. For example, it might choose a set of furniture pieces (a bed and a drawer) from available items (bed, drawer, chair, etc.) for interior design sales. This setting is widespread in fields such as recommender systems and healthcare, yet OPE/L of CCB remains unexplored in the relevant literature. Typical OPE/L methods such as regression and importance sampling can be applied to the CCB problem, however, they face significant challenges due to high bias or variance, exacerbated by the exponential growth in the number of available subsets. To address these challenges, we introduce a concept of factored action space, which allows us to decompose each subset into binary indicators. This formulation allows us to distinguish between the ''main effect'' derived from the main actions, and the ''residual effect'', originating from the supplemental actions, facilitating more effective OPE. Specifically, our estimator, called OPCB, leverages an importance sampling-based approach to unbiasedly estimate the main effect, while employing regression-based approach to deal with the residual effect with low variance. OPCB achieves substantial variance reduction compared to conventional importance sampling methods and bias reduction relative to regression methods under certain conditions, as illustrated in our theoretical analysis. Experiments demonstrate OPCB's superior performance over typical methods in both OPE and OPL.
Diffusion Model in Causal Inference with Unmeasured Confounders
Aug 15, 2023We study how to extend the use of the diffusion model to answer the causal question from the observational data under the existence of unmeasured confounders. In Pearl's framework of using a Directed Acyclic Graph (DAG) to capture the causal intervention, a Diffusion-based Causal Model (DCM) was proposed incorporating the diffusion model to answer the causal questions more accurately, assuming that all of the confounders are observed. However, unmeasured confounders in practice exist, which hinders DCM from being applicable. To alleviate this limitation of DCM, we propose an extended model called Backdoor Criterion based DCM (BDCM), whose idea is rooted in the Backdoor criterion to find the variables in DAG to be included in the decoding process of the diffusion model so that we can extend DCM to the case with unmeasured confounders. Synthetic data experiment demonstrates that our proposed model captures the counterfactual distribution more precisely than DCM under the unmeasured confounders.
Doubly Robust Estimator for Off-Policy Evaluation with Large Action Spaces
Aug 09, 2023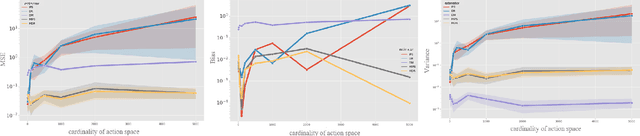
We study Off-Policy Evaluation (OPE) in contextual bandit settings with large action spaces. The benchmark estimators suffer from severe bias and variance tradeoffs. Parametric approaches suffer from bias due to difficulty specifying the correct model, whereas ones with importance weight suffer from variance. To overcome these limitations, Marginalized Inverse Propensity Scoring (MIPS) was proposed to mitigate the estimator's variance via embeddings of an action. To make the estimator more accurate, we propose the doubly robust estimator of MIPS called the Marginalized Doubly Robust (MDR) estimator. Theoretical analysis shows that the proposed estimator is unbiased under weaker assumptions than MIPS while maintaining variance reduction against IPS, which was the main advantage of MIPS. The empirical experiment verifies the supremacy of MDR against existing estimators.