 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Off-Policy Evaluation and Learning in Contextual Combinatorial Bandits
Aug 20, 2024
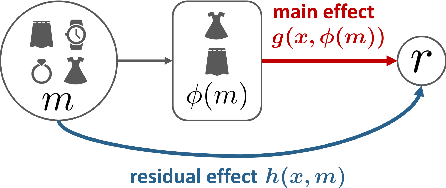
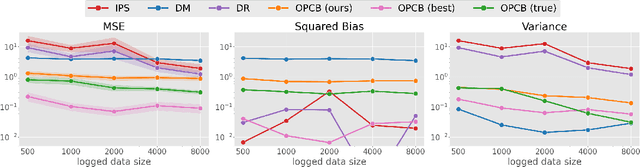
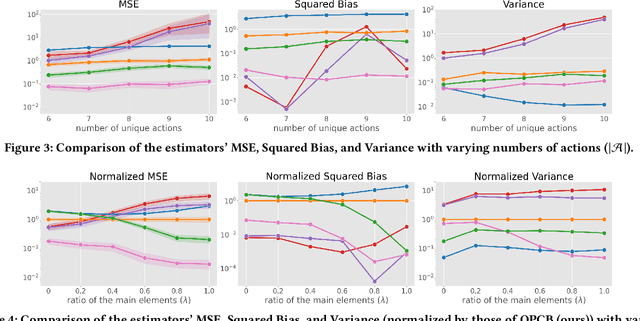
We explore off-policy evaluation and learning (OPE/L) in contextual combinatorial bandits (CCB), where a policy selects a subset in the action space. For example, it might choose a set of furniture pieces (a bed and a drawer) from available items (bed, drawer, chair, etc.) for interior design sales. This setting is widespread in fields such as recommender systems and healthcare, yet OPE/L of CCB remains unexplored in the relevant literature. Typical OPE/L methods such as regression and importance sampling can be applied to the CCB problem, however, they face significant challenges due to high bias or variance, exacerbated by the exponential growth in the number of available subsets. To address these challenges, we introduce a concept of factored action space, which allows us to decompose each subset into binary indicators. This formulation allows us to distinguish between the ''main effect'' derived from the main actions, and the ''residual effect'', originating from the supplemental actions, facilitating more effective OPE. Specifically, our estimator, called OPCB, leverages an importance sampling-based approach to unbiasedly estimate the main effect, while employing regression-based approach to deal with the residual effect with low variance. OPCB achieves substantial variance reduction compared to conventional importance sampling methods and bias reduction relative to regression methods under certain conditions, as illustrated in our theoretical analysis. Experiments demonstrate OPCB's superior performance over typical methods in both OPE and OPL.