 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Off-Policy Learning with Partially-Observed Reward
Jun 17, 2025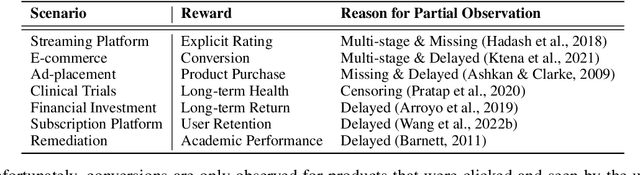
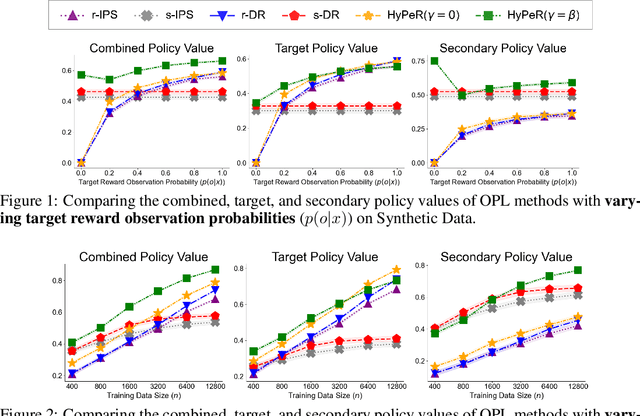
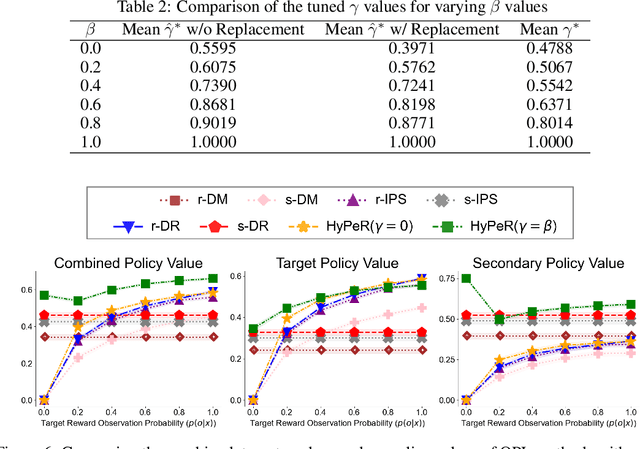
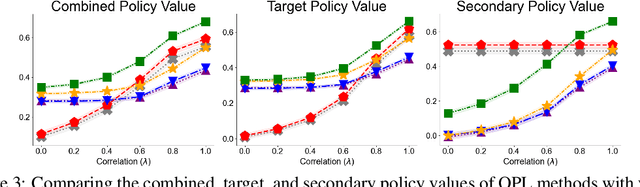
Off-policy learning (OPL) in contextual bandits aims to learn a decision-making policy that maximizes the target rewards by using only historical interaction data collected under previously developed policies. Unfortunately, when rewards are only partially observed, the effectiveness of OPL degrades severely. Well-known examples of such partial rewards include explicit ratings in content recommendations, conversion signals on e-commerce platforms that are partial due to delay, and the issue of censoring in medical problems. One possible solution to deal with such partial rewards is to use secondary rewards, such as dwelling time, clicks, and medical indicators, which are more densely observed. However, relying solely on such secondary rewards can also lead to poor policy learning since they may not align with the target reward. Thus, this work studies a new and general problem of OPL where the goal is to learn a policy that maximizes the expected target reward by leveraging densely observed secondary rewards as supplemental data. We then propose a new method called Hybrid Policy Optimization for Partially-Observed Reward (HyPeR), which effectively uses the secondary rewards in addition to the partially-observed target reward to achieve effective OPL despite the challenging scenario. We also discuss a case where we aim to optimize not only the expected target reward but also the expected secondary rewards to some extent; counter-intuitively, we will show that leveraging the two objectives is in fact advantageous also for the optimization of only the target reward. Along with statistical analysis of our proposed methods, empirical evaluations on both synthetic and real-world data show that HyPeR outperforms existing methods in various scenarios.
* 10 pages, 5 figures. Published as a conference paper at ICLR 2025
Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation
Dec 04, 2023
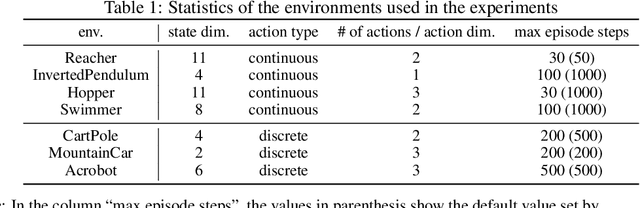
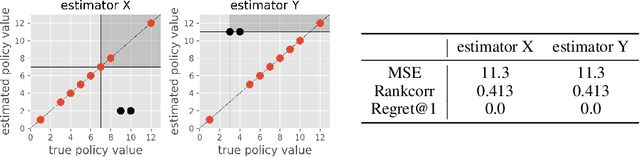
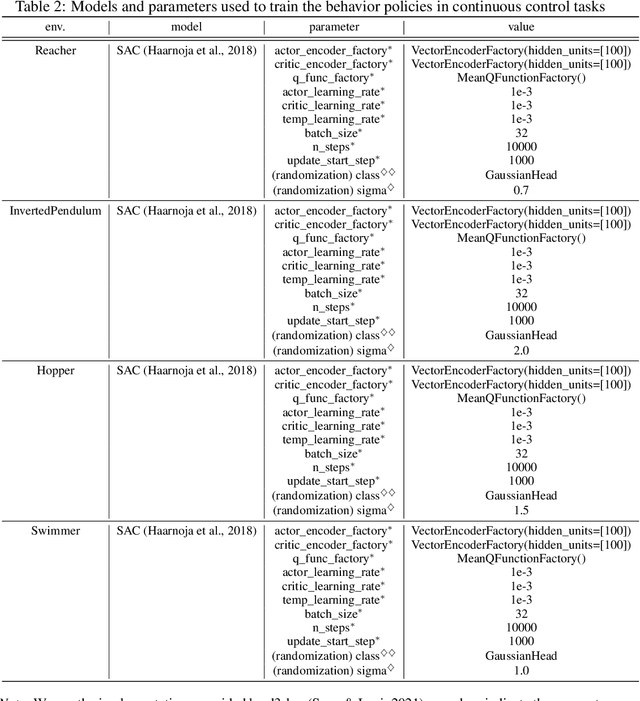
Off-Policy Evaluation (OPE) aims to assess the effectiveness of counterfactual policies using only offline logged data and is often used to identify the top-k promising policies for deployment in online A/B tests. Existing evaluation metrics for OPE estimators primarily focus on the "accuracy" of OPE or that of downstream policy selection, neglecting risk-return tradeoff in the subsequent online policy deployment. To address this issue, we draw inspiration from portfolio evaluation in finance and develop a new metric, called SharpeRatio@k, which measures the risk-return tradeoff of policy portfolios formed by an OPE estimator under varying online evaluation budgets (k). We validate our metric in two example scenarios, demonstrating its ability to effectively distinguish between low-risk and high-risk estimators and to accurately identify the most efficient estimator. This efficient estimator is characterized by its capability to form the most advantageous policy portfolios, maximizing returns while minimizing risks during online deployment, a nuance that existing metrics typically overlook. To facilitate a quick, accurate, and consistent evaluation of OPE via SharpeRatio@k, we have also integrated this metric into an open-source software, SCOPE-RL. Employing SharpeRatio@k and SCOPE-RL, we conduct comprehensive benchmarking experiments on various estimators and RL tasks, focusing on their risk-return tradeoff. These experiments offer several interesting directions and suggestions for future OPE research.
SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation
Dec 04, 2023
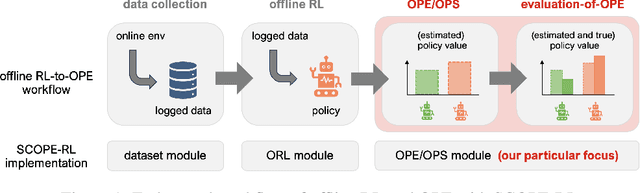
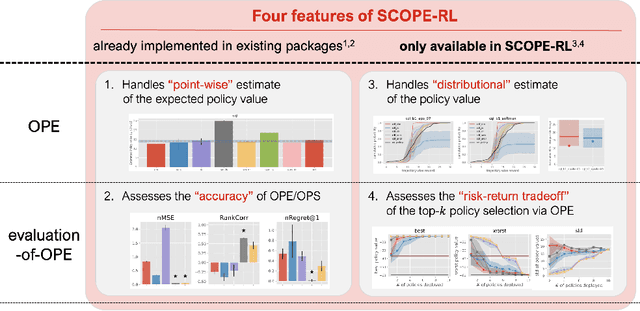

This paper introduces SCOPE-RL, a comprehensive open-source Python software designed for offline reinforcement learning (offline RL), off-policy evaluation (OPE), and selection (OPS). Unlike most existing libraries that focus solely on either policy learning or evaluation, SCOPE-RL seamlessly integrates these two key aspects, facilitating flexible and complete implementations of both offline RL and OPE processes. SCOPE-RL put particular emphasis on its OPE modules, offering a range of OPE estimators and robust evaluation-of-OPE protocols. This approach enables more in-depth and reliable OPE compared to other packages. For instance, SCOPE-RL enhances OPE by estimating the entire reward distribution under a policy rather than its mere point-wise expected value. Additionally, SCOPE-RL provides a more thorough evaluation-of-OPE by presenting the risk-return tradeoff in OPE results, extending beyond mere accuracy evaluations in existing OPE literature. SCOPE-RL is designed with user accessibility in mind. Its user-friendly APIs, comprehensive documentation, and a variety of easy-to-follow examples assist researchers and practitioners in efficiently implementing and experimenting with various offline RL methods and OPE estimators, tailored to their specific problem contexts. The documentation of SCOPE-RL is available at https://scope-rl.readthedocs.io/en/latest/.
Accelerating Offline Reinforcement Learning Application in Real-Time Bidding and Recommendation: Potential Use of Simulation
Sep 17, 2021
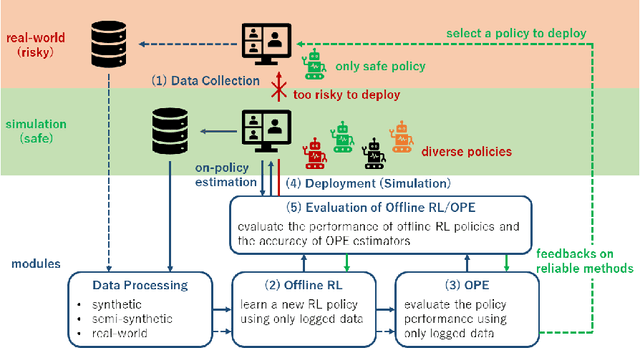
In recommender systems (RecSys) and real-time bidding (RTB) for online advertisements, we often try to optimize sequential decision making using bandit and reinforcement learning (RL) techniques. In these applications, offline reinforcement learning (offline RL) and off-policy evaluation (OPE) are beneficial because they enable safe policy optimization using only logged data without any risky online interaction. In this position paper, we explore the potential of using simulation to accelerate practical research of offline RL and OPE, particularly in RecSys and RTB. Specifically, we discuss how simulation can help us conduct empirical research of offline RL and OPE. We take a position to argue that we should effectively use simulations in the empirical research of offline RL and OPE. To refute the counterclaim that experiments using only real-world data are preferable, we first point out the underlying risks and reproducibility issue in real-world experiments. Then, we describe how these issues can be addressed by using simulations. Moreover, we show how to incorporate the benefits of both real-world and simulation-based experiments to defend our position. Finally, we also present an open challenge to further facilitate practical research of offline RL and OPE in RecSys and RTB, with respect to public simulation platforms. As a possible solution for the issue, we show our ongoing open source project and its potential use case. We believe that building and utilizing simulation-based evaluation platforms for offline RL and OPE will be of great interest and relevance for the RecSys and RTB community.