 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversification as Risk Minimization
Oct 26, 2025Users tend to remember failures of a search session more than its many successes. This observation has led to work on search robustness, where systems are penalized if they perform very poorly on some queries. However, this principle of robustness has been overlooked within a single query. An ambiguous or underspecified query (e.g., ``jaguar'') can have several user intents, where popular intents often dominate the ranking, leaving users with minority intents unsatisfied. Although the diversification literature has long recognized this issue, existing metrics only model the average relevance across intents and provide no robustness guarantees. More surprisingly, we show theoretically and empirically that many well-known diversification algorithms are no more robust than a naive, non-diversified algorithm. To address this critical gap, we propose to frame diversification as a risk-minimization problem. We introduce VRisk, which measures the expected risk faced by the least-served fraction of intents in a query. Optimizing VRisk produces a robust ranking, reducing the likelihood of poor user experiences. We then propose VRisker, a fast greedy re-ranker with provable approximation guarantees. Finally, experiments on NTCIR INTENT-2, TREC Web 2012, and MovieLens show the vulnerability of existing methods. VRisker reduces worst-case intent failures by up to 33% with a minimal 2% drop in average performance.
Simple Projection Variants Improve ColBERT Performance
Oct 14, 2025



Multi-vector dense retrieval methods like ColBERT systematically use a single-layer linear projection to reduce the dimensionality of individual vectors. In this study, we explore the implications of the MaxSim operator on the gradient flows of the training of multi-vector models and show that such a simple linear projection has inherent, if non-critical, limitations in this setting. We then discuss the theoretical improvements that could result from replacing this single-layer projection with well-studied alternative feedforward linear networks (FFN), such as deeper, non-linear FFN blocks, GLU blocks, and skip-connections, could alleviate these limitations. Through the design and systematic evaluation of alternate projection blocks, we show that better-designed final projections positively impact the downstream performance of ColBERT models. We highlight that many projection variants outperform the original linear projections, with the best-performing variants increasing average performance on a range of retrieval benchmarks across domains by over 2 NDCG@10 points. We then conduct further exploration on the individual parameters of these projections block in order to understand what drives this empirical performance, highlighting the particular importance of upscaled intermediate projections and residual connections. As part of these ablation studies, we show that numerous suboptimal projection variants still outperform the traditional single-layer projection across multiple benchmarks, confirming our hypothesis. Finally, we observe that this effect is consistent across random seeds, further confirming that replacing the linear layer of ColBERT models is a robust, drop-in upgrade.
A General Framework for Off-Policy Learning with Partially-Observed Reward
Jun 17, 2025
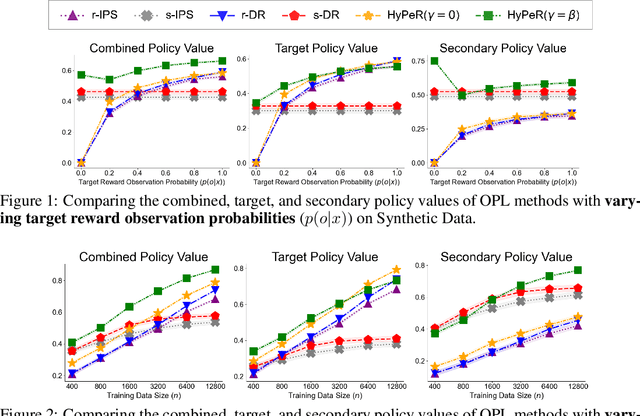
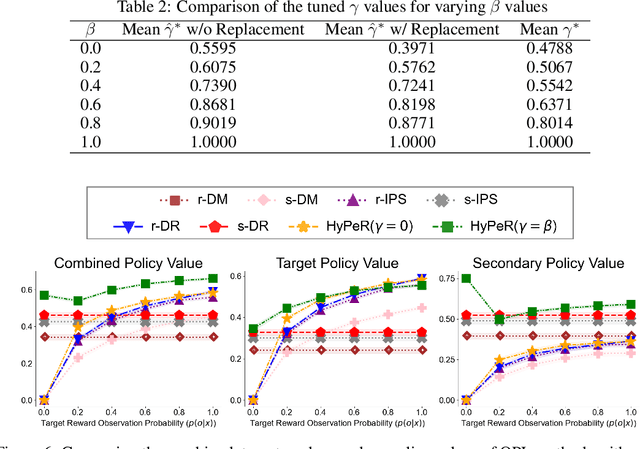
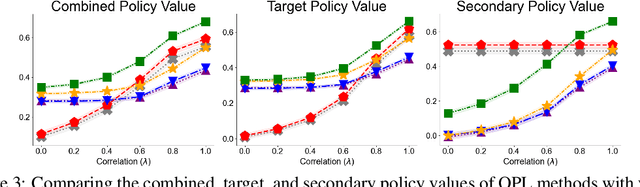
Off-policy learning (OPL) in contextual bandits aims to learn a decision-making policy that maximizes the target rewards by using only historical interaction data collected under previously developed policies. Unfortunately, when rewards are only partially observed, the effectiveness of OPL degrades severely. Well-known examples of such partial rewards include explicit ratings in content recommendations, conversion signals on e-commerce platforms that are partial due to delay, and the issue of censoring in medical problems. One possible solution to deal with such partial rewards is to use secondary rewards, such as dwelling time, clicks, and medical indicators, which are more densely observed. However, relying solely on such secondary rewards can also lead to poor policy learning since they may not align with the target reward. Thus, this work studies a new and general problem of OPL where the goal is to learn a policy that maximizes the expected target reward by leveraging densely observed secondary rewards as supplemental data. We then propose a new method called Hybrid Policy Optimization for Partially-Observed Reward (HyPeR), which effectively uses the secondary rewards in addition to the partially-observed target reward to achieve effective OPL despite the challenging scenario. We also discuss a case where we aim to optimize not only the expected target reward but also the expected secondary rewards to some extent; counter-intuitively, we will show that leveraging the two objectives is in fact advantageous also for the optimization of only the target reward. Along with statistical analysis of our proposed methods, empirical evaluations on both synthetic and real-world data show that HyPeR outperforms existing methods in various scenarios.
* 10 pages, 5 figures. Published as a conference paper at ICLR 2025
LLM-Assisted Relevance Assessments: When Should We Ask LLMs for Help?
Nov 11, 2024Test collections are information retrieval tools that allow researchers to quickly and easily evaluate ranking algorithms. While test collections have become an integral part of IR research, the process of data creation involves significant efforts in manual annotations, which often makes it very expensive and time-consuming. Thus, the test collections could become small when the budget is limited, which may lead to unstable evaluations. As an alternative, recent studies have proposed the use of large language models (LLMs) to completely replace human assessors. However, while LLMs seem to somewhat correlate with human judgments, they are not perfect and often show bias. Moreover, even if a well-performing LLM or prompt is found on one dataset, there is no guarantee that it will perform similarly in practice, due to difference in tasks and data. Thus a complete replacement with LLMs is argued to be too risky and not fully trustable. Thus, in this paper, we propose \textbf{L}LM-\textbf{A}ssisted \textbf{R}elevance \textbf{A}ssessments (\textbf{LARA}), an effective method to balance manual annotations with LLM annotations, which helps to make a rich and reliable test collection. We use the LLM's predicted relevance probabilities in order to select the most profitable documents to manually annotate under a budget constraint. While solely relying on LLM's predicted probabilities to manually annotate performs fairly well, with theoretical reasoning, LARA guides the human annotation process even more effectively via online calibration learning. Then, using the calibration model learned from the limited manual annotations, LARA debiases the LLM predictions to annotate the remaining non-assessed data. Empirical evaluations on TREC-COVID and TREC-8 Ad Hoc datasets show that LARA outperforms the alternative solutions under almost any budget constraint.
Open-Domain Dialogue Quality Evaluation: Deriving Nugget-level Scores from Turn-level Scores
Sep 30, 2023



Existing dialogue quality evaluation systems can return a score for a given system turn from a particular viewpoint, e.g., engagingness. However, to improve dialogue systems by locating exactly where in a system turn potential problems lie, a more fine-grained evaluation may be necessary. We therefore propose an evaluation approach where a turn is decomposed into nuggets (i.e., expressions associated with a dialogue act), and nugget-level evaluation is enabled by leveraging an existing turn-level evaluation system. We demonstrate the potential effectiveness of our evaluation method through a case study.