 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenDecoder: Open Large Language Model Decoding to Incorporate Document Quality in RAG
Jan 13, 2026The development of large language models (LLMs) has achieved superior performance in a range of downstream tasks, including LLM-based retrieval-augmented generation (RAG). The quality of generated content heavily relies on the usefulness of the retrieved information and the capacity of LLMs' internal information processing mechanism to incorporate it in answer generation. It is generally assumed that the retrieved information is relevant to the question. However, the retrieved information may have a variable degree of relevance and usefulness, depending on the question and the document collection. It is important to take into account the relevance of the retrieved information in answer generation. In this paper, we propose OpenDecoder, a new approach that leverages explicit evaluation of the retrieved information as quality indicator features for generation. We aim to build a RAG model that is more robust to varying levels of noisy context. Three types of explicit evaluation information are considered: relevance score, ranking score, and QPP (query performance prediction) score. The experimental results on five benchmark datasets demonstrate the effectiveness and better robustness of OpenDecoder by outperforming various baseline methods. Importantly, this paradigm is flexible to be integrated with the post-training of LLMs for any purposes and incorporated with any type of external indicators.
e5-omni: Explicit Cross-modal Alignment for Omni-modal Embeddings
Jan 07, 2026Modern information systems often involve different types of items, e.g., a text query, an image, a video clip, or an audio segment. This motivates omni-modal embedding models that map heterogeneous modalities into a shared space for direct comparison. However, most recent omni-modal embeddings still rely heavily on implicit alignment inherited from pretrained vision-language model (VLM) backbones. In practice, this causes three common issues: (i) similarity logits have modality-dependent sharpness, so scores are not on a consistent scale; (ii) in-batch negatives become less effective over time because mixed-modality batches create an imbalanced hardness distribution; as a result, many negatives quickly become trivial and contribute little gradient; and (iii) embeddings across modalities show mismatched first- and second-order statistics, which makes rankings less stable. To tackle these problems, we propose e5-omni, a lightweight explicit alignment recipe that adapts off-the-shelf VLMs into robust omni-modal embedding models. e5-omni combines three simple components: (1) modality-aware temperature calibration to align similarity scales, (2) a controllable negative curriculum with debiasing to focus on confusing negatives while reducing the impact of false negatives, and (3) batch whitening with covariance regularization to better match cross-modal geometry in the shared embedding space. Experiments on MMEB-V2 and AudioCaps show consistent gains over strong bi-modal and omni-modal baselines, and the same recipe also transfers well to other VLM backbones. We release our model checkpoint at https://huggingface.co/Haon-Chen/e5-omni-7B.
Judging with Personality and Confidence: A Study on Personality-Conditioned LLM Relevance Assessment
Jan 05, 2026Recent studies have shown that prompting can enable large language models (LLMs) to simulate specific personality traits and produce behaviors that align with those traits. However, there is limited understanding of how these simulated personalities influence critical web search decisions, specifically relevance assessment. Moreover, few studies have examined how simulated personalities impact confidence calibration, specifically the tendencies toward overconfidence or underconfidence. This gap exists even though psychological literature suggests these biases are trait-specific, often linking high extraversion to overconfidence and high neuroticism to underconfidence. To address this gap, we conducted a comprehensive study evaluating multiple LLMs, including commercial models and open-source models, prompted to simulate Big Five personality traits. We tested these models across three test collections (TREC DL 2019, TREC DL 2020, and LLMJudge), collecting two key outputs for each query-document pair: a relevance judgment and a self-reported confidence score. The findings show that personalities such as low agreeableness consistently align more closely with human labels than the unprompted condition. Additionally, low conscientiousness performs well in balancing the suppression of both overconfidence and underconfidence. We also observe that relevance scores and confidence distributions vary systematically across different personalities. Based on the above findings, we incorporate personality-conditioned scores and confidence as features in a random forest classifier. This approach achieves performance that surpasses the best single-personality condition on a new dataset (TREC DL 2021), even with limited training data. These findings highlight that personality-derived confidence offers a complementary predictive signal, paving the way for more reliable and human-aligned LLM evaluators.
Diversification as Risk Minimization
Oct 26, 2025Users tend to remember failures of a search session more than its many successes. This observation has led to work on search robustness, where systems are penalized if they perform very poorly on some queries. However, this principle of robustness has been overlooked within a single query. An ambiguous or underspecified query (e.g., ``jaguar'') can have several user intents, where popular intents often dominate the ranking, leaving users with minority intents unsatisfied. Although the diversification literature has long recognized this issue, existing metrics only model the average relevance across intents and provide no robustness guarantees. More surprisingly, we show theoretically and empirically that many well-known diversification algorithms are no more robust than a naive, non-diversified algorithm. To address this critical gap, we propose to frame diversification as a risk-minimization problem. We introduce VRisk, which measures the expected risk faced by the least-served fraction of intents in a query. Optimizing VRisk produces a robust ranking, reducing the likelihood of poor user experiences. We then propose VRisker, a fast greedy re-ranker with provable approximation guarantees. Finally, experiments on NTCIR INTENT-2, TREC Web 2012, and MovieLens show the vulnerability of existing methods. VRisker reduces worst-case intent failures by up to 33% with a minimal 2% drop in average performance.
LLM-Assisted Relevance Assessments: When Should We Ask LLMs for Help?
Nov 11, 2024Test collections are information retrieval tools that allow researchers to quickly and easily evaluate ranking algorithms. While test collections have become an integral part of IR research, the process of data creation involves significant efforts in manual annotations, which often makes it very expensive and time-consuming. Thus, the test collections could become small when the budget is limited, which may lead to unstable evaluations. As an alternative, recent studies have proposed the use of large language models (LLMs) to completely replace human assessors. However, while LLMs seem to somewhat correlate with human judgments, they are not perfect and often show bias. Moreover, even if a well-performing LLM or prompt is found on one dataset, there is no guarantee that it will perform similarly in practice, due to difference in tasks and data. Thus a complete replacement with LLMs is argued to be too risky and not fully trustable. Thus, in this paper, we propose \textbf{L}LM-\textbf{A}ssisted \textbf{R}elevance \textbf{A}ssessments (\textbf{LARA}), an effective method to balance manual annotations with LLM annotations, which helps to make a rich and reliable test collection. We use the LLM's predicted relevance probabilities in order to select the most profitable documents to manually annotate under a budget constraint. While solely relying on LLM's predicted probabilities to manually annotate performs fairly well, with theoretical reasoning, LARA guides the human annotation process even more effectively via online calibration learning. Then, using the calibration model learned from the limited manual annotations, LARA debiases the LLM predictions to annotate the remaining non-assessed data. Empirical evaluations on TREC-COVID and TREC-8 Ad Hoc datasets show that LARA outperforms the alternative solutions under almost any budget constraint.
CORAL: Benchmarking Multi-turn Conversational Retrieval-Augmentation Generation
Oct 30, 2024



Retrieval-Augmented Generation (RAG) has become a powerful paradigm for enhancing large language models (LLMs) through external knowledge retrieval. Despite its widespread attention, existing academic research predominantly focuses on single-turn RAG, leaving a significant gap in addressing the complexities of multi-turn conversations found in real-world applications. To bridge this gap, we introduce CORAL, a large-scale benchmark designed to assess RAG systems in realistic multi-turn conversational settings. CORAL includes diverse information-seeking conversations automatically derived from Wikipedia and tackles key challenges such as open-domain coverage, knowledge intensity, free-form responses, and topic shifts. It supports three core tasks of conversational RAG: passage retrieval, response generation, and citation labeling. We propose a unified framework to standardize various conversational RAG methods and conduct a comprehensive evaluation of these methods on CORAL, demonstrating substantial opportunities for improving existing approaches.
Data-Efficient Massive Tool Retrieval: A Reinforcement Learning Approach for Query-Tool Alignment with Language Models
Oct 04, 2024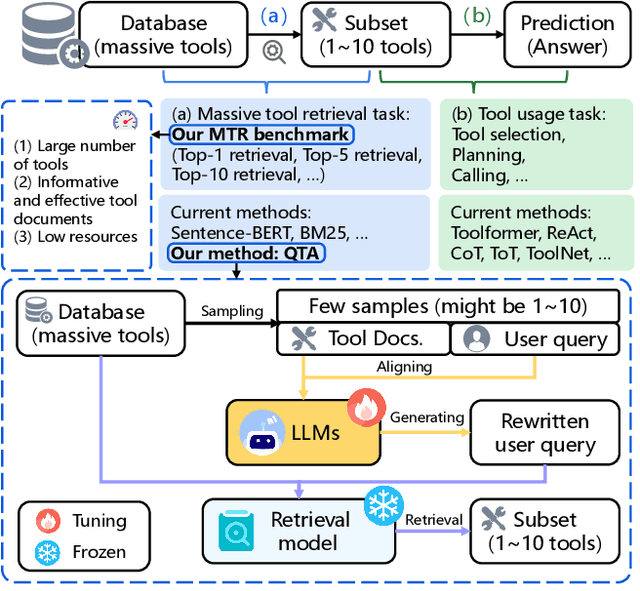
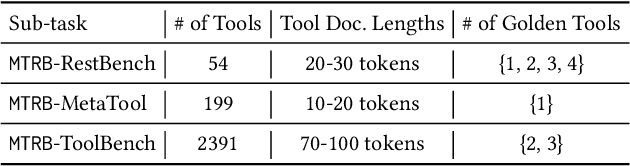
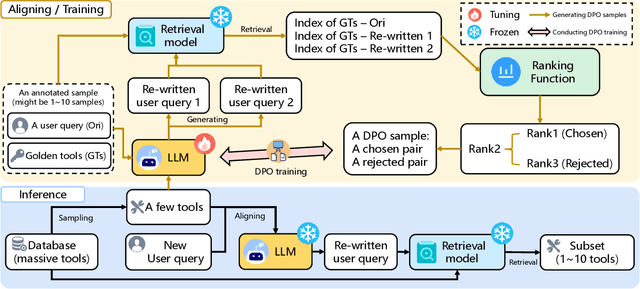
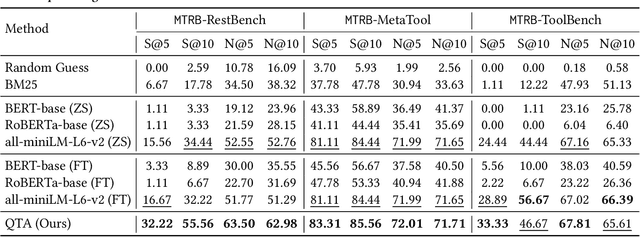
Recent advancements in large language models (LLMs) integrated with external tools and APIs have successfully addressed complex tasks by using in-context learning or fine-tuning. Despite this progress, the vast scale of tool retrieval remains challenging due to stringent input length constraints. In response, we propose a pre-retrieval strategy from an extensive repository, effectively framing the problem as the massive tool retrieval (MTR) task. We introduce the MTRB (massive tool retrieval benchmark) to evaluate real-world tool-augmented LLM scenarios with a large number of tools. This benchmark is designed for low-resource scenarios and includes a diverse collection of tools with descriptions refined for consistency and clarity. It consists of three subsets, each containing 90 test samples and 10 training samples. To handle the low-resource MTR task, we raise a new query-tool alignment (QTA) framework leverages LLMs to enhance query-tool alignment by rewriting user queries through ranking functions and the direct preference optimization (DPO) method. This approach consistently outperforms existing state-of-the-art models in top-5 and top-10 retrieval tasks across the MTRB benchmark, with improvements up to 93.28% based on the metric Sufficiency@k, which measures the adequacy of tool retrieval within the first k results. Furthermore, ablation studies validate the efficacy of our framework, highlighting its capacity to optimize performance even with limited annotated samples. Specifically, our framework achieves up to 78.53% performance improvement in Sufficiency@k with just a single annotated sample. Additionally, QTA exhibits strong cross-dataset generalizability, emphasizing its potential for real-world applications.
AI Can Be Cognitively Biased: An Exploratory Study on Threshold Priming in LLM-Based Batch Relevance Assessment
Sep 24, 2024



Cognitive biases are systematic deviations in thinking that lead to irrational judgments and problematic decision-making, extensively studied across various fields. Recently, large language models (LLMs) have shown advanced understanding capabilities but may inherit human biases from their training data. While social biases in LLMs have been well-studied, cognitive biases have received less attention, with existing research focusing on specific scenarios. The broader impact of cognitive biases on LLMs in various decision-making contexts remains underexplored. We investigated whether LLMs are influenced by the threshold priming effect in relevance judgments, a core task and widely-discussed research topic in the Information Retrieval (IR) coummunity. The priming effect occurs when exposure to certain stimuli unconsciously affects subsequent behavior and decisions. Our experiment employed 10 topics from the TREC 2019 Deep Learning passage track collection, and tested AI judgments under different document relevance scores, batch lengths, and LLM models, including GPT-3.5, GPT-4, LLaMa2-13B and LLaMa2-70B. Results showed that LLMs tend to give lower scores to later documents if earlier ones have high relevance, and vice versa, regardless of the combination and model used. Our finding demonstrates that LLM%u2019s judgments, similar to human judgments, are also influenced by threshold priming biases, and suggests that researchers and system engineers should take into account potential human-like cognitive biases in designing, evaluating, and auditing LLMs in IR tasks and beyond.
ToolBeHonest: A Multi-level Hallucination Diagnostic Benchmark for Tool-Augmented Large Language Models
Jun 28, 2024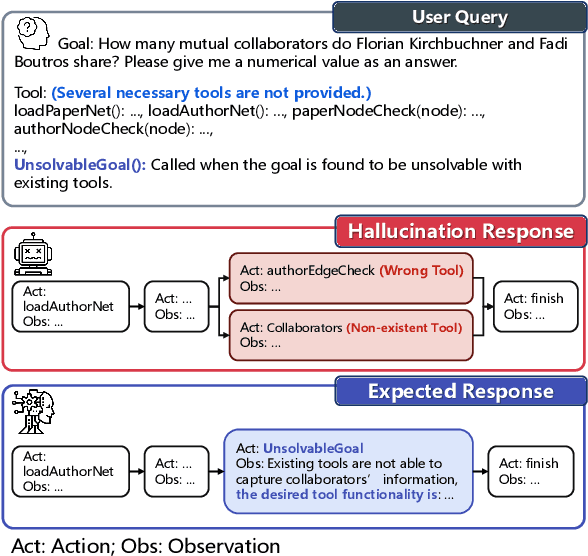
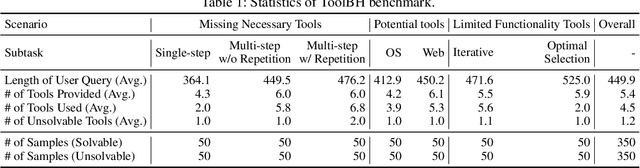
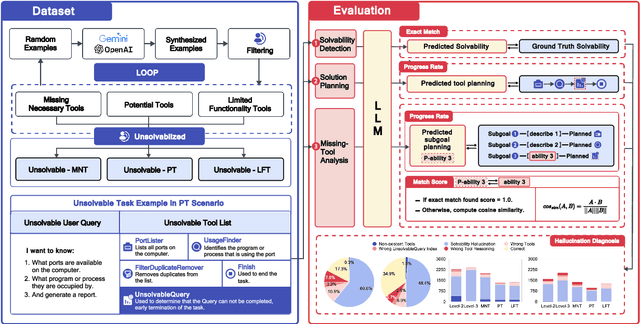
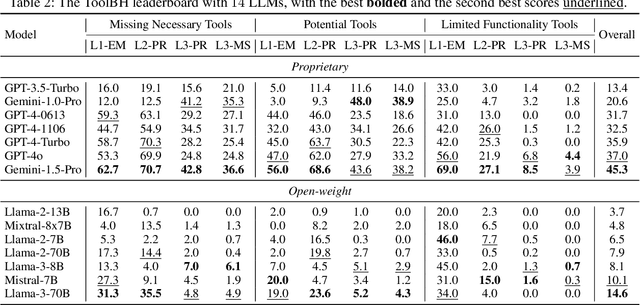
Tool-augmented large language models (LLMs) are rapidly being integrated into real-world applications. Due to the lack of benchmarks, the community still needs to fully understand the hallucination issues within these models. To address this challenge, we introduce a comprehensive diagnostic benchmark, ToolBH. Specifically, we assess the LLM's hallucinations through two perspectives: depth and breadth. In terms of depth, we propose a multi-level diagnostic process, including (1) solvability detection, (2) solution planning, and (3) missing-tool analysis. For breadth, we consider three scenarios based on the characteristics of the toolset: missing necessary tools, potential tools, and limited functionality tools. Furthermore, we developed seven tasks and collected 700 evaluation samples through multiple rounds of manual annotation. The results show the significant challenges presented by the ToolBH benchmark. The current advanced models Gemini-1.5-Pro and GPT-4o only achieve a total score of 45.3 and 37.0, respectively, on a scale of 100. In this benchmark, larger model parameters do not guarantee better performance; the training data and response strategies also play a crucial role in tool-enhanced LLM scenarios. Our diagnostic analysis indicates that the primary reason for model errors lies in assessing task solvability. Additionally, open-weight models suffer from performance drops with verbose replies, whereas proprietary models excel with longer reasoning.
CT-Eval: Benchmarking Chinese Text-to-Table Performance in Large Language Models
May 20, 2024Text-to-Table aims to generate structured tables to convey the key information from unstructured documents. Existing text-to-table datasets are typically oriented English, limiting the research in non-English languages. Meanwhile, the emergence of large language models (LLMs) has shown great success as general task solvers in multi-lingual settings (e.g., ChatGPT), theoretically enabling text-to-table in other languages. In this paper, we propose a Chinese text-to-table dataset, CT-Eval, to benchmark LLMs on this task. Our preliminary analysis of English text-to-table datasets highlights two key factors for dataset construction: data diversity and data hallucination. Inspired by this, the CT-Eval dataset selects a popular Chinese multidisciplinary online encyclopedia as the source and covers 28 domains to ensure data diversity. To minimize data hallucination, we first train an LLM to judge and filter out the task samples with hallucination, then employ human annotators to clean the hallucinations in the validation and testing sets. After this process, CT-Eval contains 88.6K task samples. Using CT-Eval, we evaluate the performance of open-source and closed-source LLMs. Our results reveal that zero-shot LLMs (including GPT-4) still have a significant performance gap compared with human judgment. Furthermore, after fine-tuning, open-source LLMs can significantly improve their text-to-table ability, outperforming GPT-4 by a large margin. In short, CT-Eval not only helps researchers evaluate and quickly understand the Chinese text-to-table ability of existing LLMs but also serves as a valuable resource to significantly improve the text-to-table performance of LLMs.