 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Assisted Relevance Assessments: When Should We Ask LLMs for Help?
Nov 11, 2024Test collections are information retrieval tools that allow researchers to quickly and easily evaluate ranking algorithms. While test collections have become an integral part of IR research, the process of data creation involves significant efforts in manual annotations, which often makes it very expensive and time-consuming. Thus, the test collections could become small when the budget is limited, which may lead to unstable evaluations. As an alternative, recent studies have proposed the use of large language models (LLMs) to completely replace human assessors. However, while LLMs seem to somewhat correlate with human judgments, they are not perfect and often show bias. Moreover, even if a well-performing LLM or prompt is found on one dataset, there is no guarantee that it will perform similarly in practice, due to difference in tasks and data. Thus a complete replacement with LLMs is argued to be too risky and not fully trustable. Thus, in this paper, we propose \textbf{L}LM-\textbf{A}ssisted \textbf{R}elevance \textbf{A}ssessments (\textbf{LARA}), an effective method to balance manual annotations with LLM annotations, which helps to make a rich and reliable test collection. We use the LLM's predicted relevance probabilities in order to select the most profitable documents to manually annotate under a budget constraint. While solely relying on LLM's predicted probabilities to manually annotate performs fairly well, with theoretical reasoning, LARA guides the human annotation process even more effectively via online calibration learning. Then, using the calibration model learned from the limited manual annotations, LARA debiases the LLM predictions to annotate the remaining non-assessed data. Empirical evaluations on TREC-COVID and TREC-8 Ad Hoc datasets show that LARA outperforms the alternative solutions under almost any budget constraint.
Human Preferences as Dueling Bandits
Apr 21, 2022
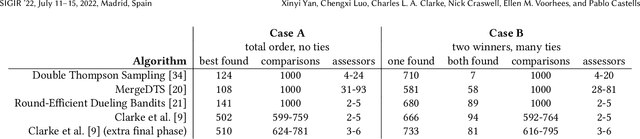
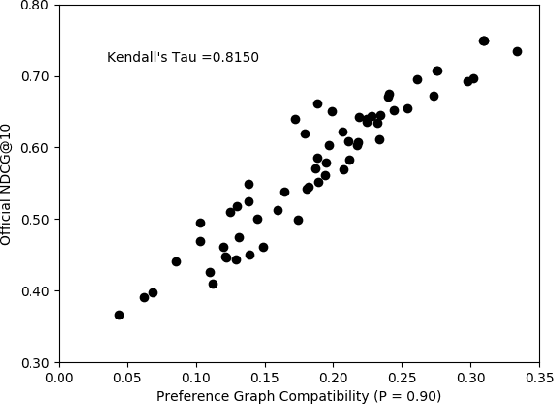
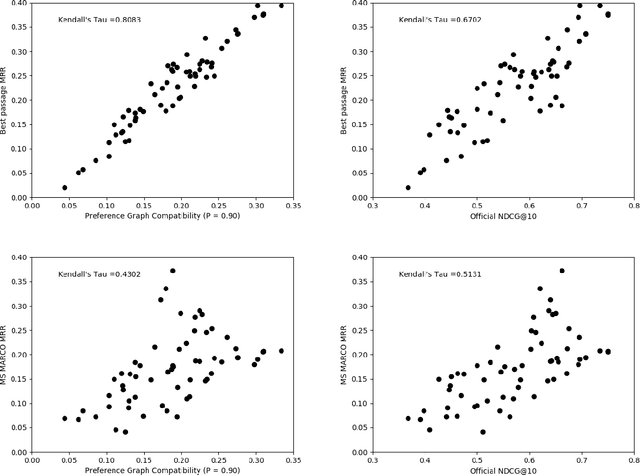
The dramatic improvements in core information retrieval tasks engendered by neural rankers create a need for novel evaluation methods. If every ranker returns highly relevant items in the top ranks, it becomes difficult to recognize meaningful differences between them and to build reusable test collections. Several recent papers explore pairwise preference judgments as an alternative to traditional graded relevance assessments. Rather than viewing items one at a time, assessors view items side-by-side and indicate the one that provides the better response to a query, allowing fine-grained distinctions. If we employ preference judgments to identify the probably best items for each query, we can measure rankers by their ability to place these items as high as possible. We frame the problem of finding best items as a dueling bandits problem. While many papers explore dueling bandits for online ranker evaluation via interleaving, they have not been considered as a framework for offline evaluation via human preference judgments. We review the literature for possible solutions. For human preference judgments, any usable algorithm must tolerate ties, since two items may appear nearly equal to assessors, and it must minimize the number of judgments required for any specific pair, since each such comparison requires an independent assessor. Since the theoretical guarantees provided by most algorithms depend on assumptions that are not satisfied by human preference judgments, we simulate selected algorithms on representative test cases to provide insight into their practical utility. Based on these simulations, one algorithm stands out for its potential. Our simulations suggest modifications to further improve its performance. Using the modified algorithm, we collect over 10,000 preference judgments for submissions to the TREC 2021 Deep Learning Track, confirming its suitability.
Can Old TREC Collections Reliably Evaluate Modern Neural Retrieval Models?
Jan 26, 2022Neural retrieval models are generally regarded as fundamentally different from the retrieval techniques used in the late 1990's when the TREC ad hoc test collections were constructed. They thus provide the opportunity to empirically test the claim that pooling-built test collections can reliably evaluate retrieval systems that did not contribute to the construction of the collection (in other words, that such collections can be reusable). To test the reusability claim, we asked TREC assessors to judge new pools created from new search results for the TREC-8 ad hoc collection. These new search results consisted of five new runs (one each from three transformer-based models and two baseline runs that use BM25) plus the set of TREC-8 submissions that did not previously contribute to pools. The new runs did retrieve previously unseen documents, but the vast majority of those documents were not relevant. The ranking of all runs by mean evaluation score when evaluated using the official TREC-8 relevance judgment set and the newly expanded relevance set are almost identical, with Kendall's tau correlations greater than 0.99. Correlations for individual topics are also high. The TREC-8 ad hoc collection was originally constructed using deep pools over a diverse set of runs, including several effective manual runs. Its judgment budget, and hence construction cost, was relatively large. However, it does appear that the expense was well-spent: even with the advent of neural techniques, the collection has stood the test of time and remains a reliable evaluation instrument as retrieval techniques have advanced.
TREC Deep Learning Track: Reusable Test Collections in the Large Data Regime
Apr 19, 2021



The TREC Deep Learning (DL) Track studies ad hoc search in the large data regime, meaning that a large set of human-labeled training data is available. Results so far indicate that the best models with large data may be deep neural networks. This paper supports the reuse of the TREC DL test collections in three ways. First we describe the data sets in detail, documenting clearly and in one place some details that are otherwise scattered in track guidelines, overview papers and in our associated MS MARCO leaderboard pages. We intend this description to make it easy for newcomers to use the TREC DL data. Second, because there is some risk of iteration and selection bias when reusing a data set, we describe the best practices for writing a paper using TREC DL data, without overfitting. We provide some illustrative analysis. Finally we address a number of issues around the TREC DL data, including an analysis of reusability.
Overview of the TREC 2019 deep learning track
Mar 18, 2020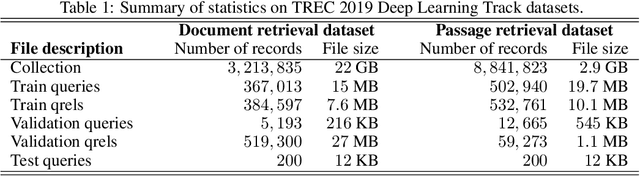
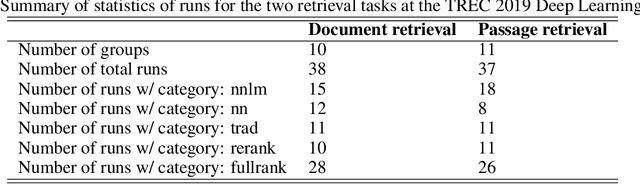
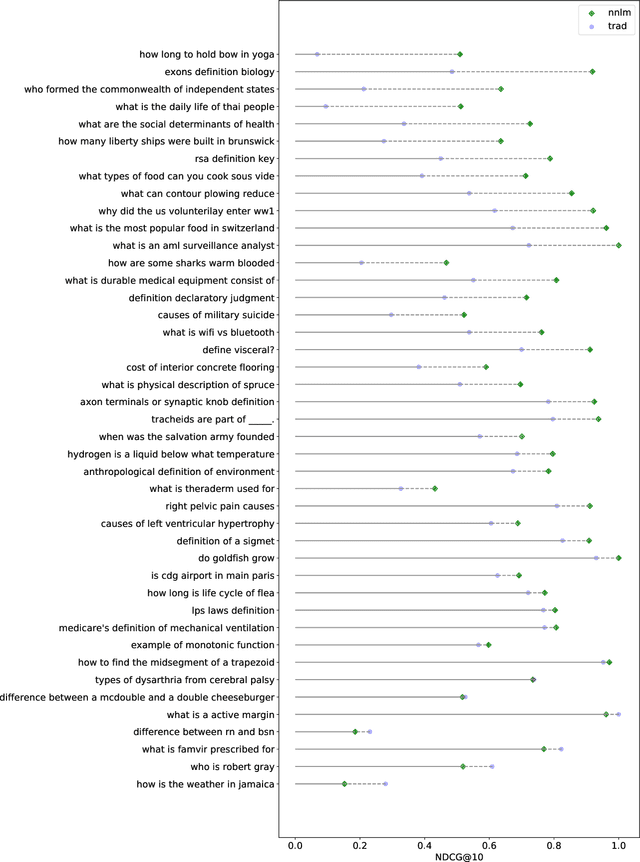
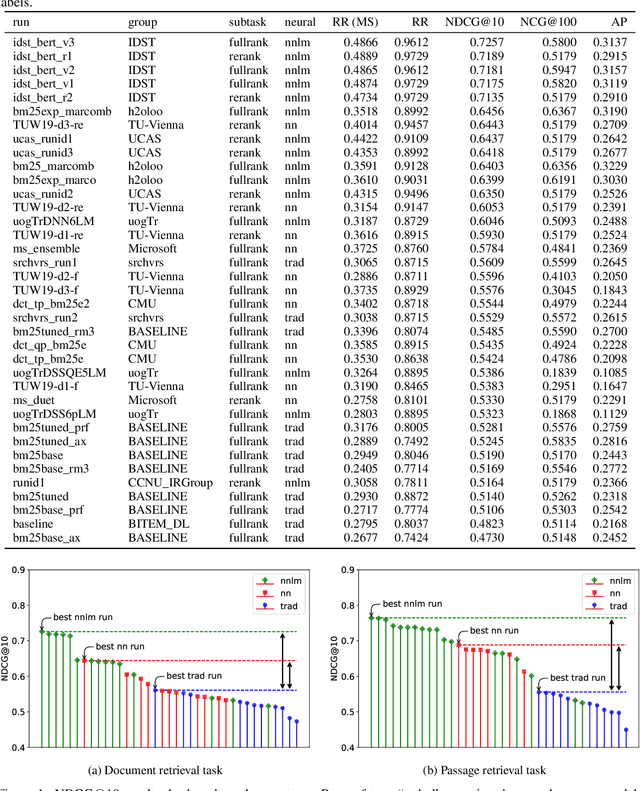
The Deep Learning Track is a new track for TREC 2019, with the goal of studying ad hoc ranking in a large data regime. It is the first track with large human-labeled training sets, introducing two sets corresponding to two tasks, each with rigorous TREC-style blind evaluation and reusable test sets. The document retrieval task has a corpus of 3.2 million documents with 367 thousand training queries, for which we generate a reusable test set of 43 queries. The passage retrieval task has a corpus of 8.8 million passages with 503 thousand training queries, for which we generate a reusable test set of 43 queries. This year 15 groups submitted a total of 75 runs, using various combinations of deep learning, transfer learning and traditional IR ranking methods. Deep learning runs significantly outperformed traditional IR runs. Possible explanations for this result are that we introduced large training data and we included deep models trained on such data in our judging pools, whereas some past studies did not have such training data or pooling.