 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Preferences as Dueling Bandits
Apr 21, 2022
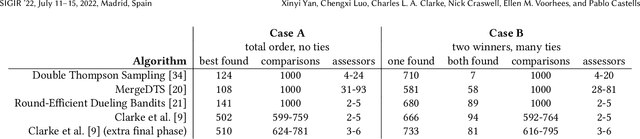
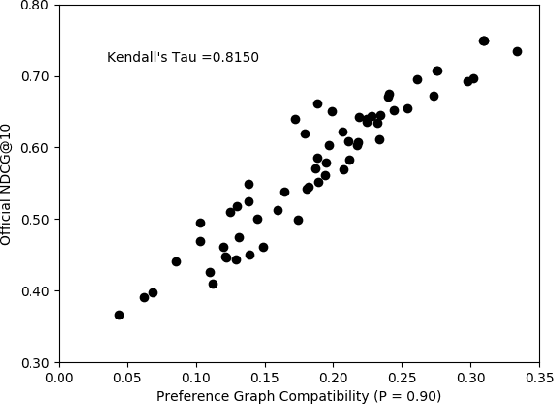
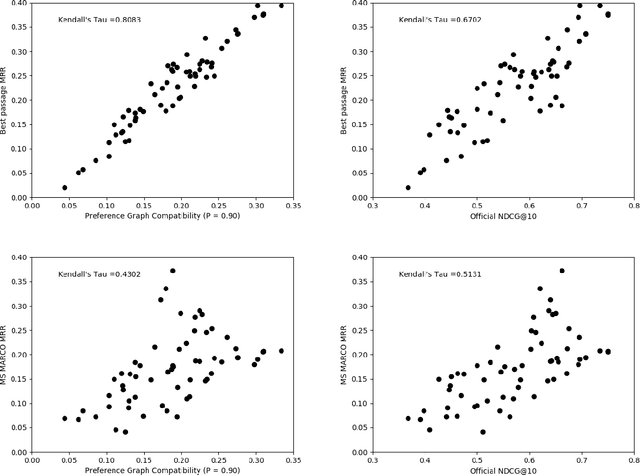
The dramatic improvements in core information retrieval tasks engendered by neural rankers create a need for novel evaluation methods. If every ranker returns highly relevant items in the top ranks, it becomes difficult to recognize meaningful differences between them and to build reusable test collections. Several recent papers explore pairwise preference judgments as an alternative to traditional graded relevance assessments. Rather than viewing items one at a time, assessors view items side-by-side and indicate the one that provides the better response to a query, allowing fine-grained distinctions. If we employ preference judgments to identify the probably best items for each query, we can measure rankers by their ability to place these items as high as possible. We frame the problem of finding best items as a dueling bandits problem. While many papers explore dueling bandits for online ranker evaluation via interleaving, they have not been considered as a framework for offline evaluation via human preference judgments. We review the literature for possible solutions. For human preference judgments, any usable algorithm must tolerate ties, since two items may appear nearly equal to assessors, and it must minimize the number of judgments required for any specific pair, since each such comparison requires an independent assessor. Since the theoretical guarantees provided by most algorithms depend on assumptions that are not satisfied by human preference judgments, we simulate selected algorithms on representative test cases to provide insight into their practical utility. Based on these simulations, one algorithm stands out for its potential. Our simulations suggest modifications to further improve its performance. Using the modified algorithm, we collect over 10,000 preference judgments for submissions to the TREC 2021 Deep Learning Track, confirming its suitability.
Predicting Efficiency/Effectiveness Trade-offs for Dense vs. Sparse Retrieval Strategy Selection
Sep 22, 2021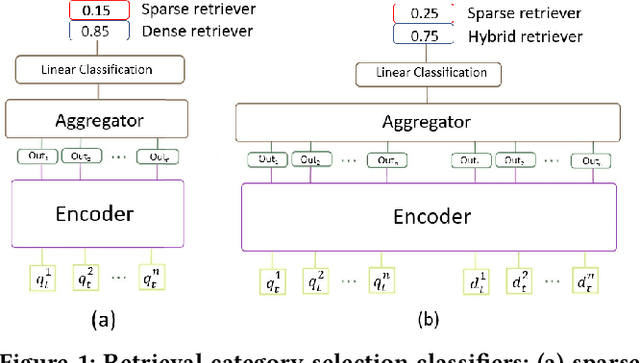
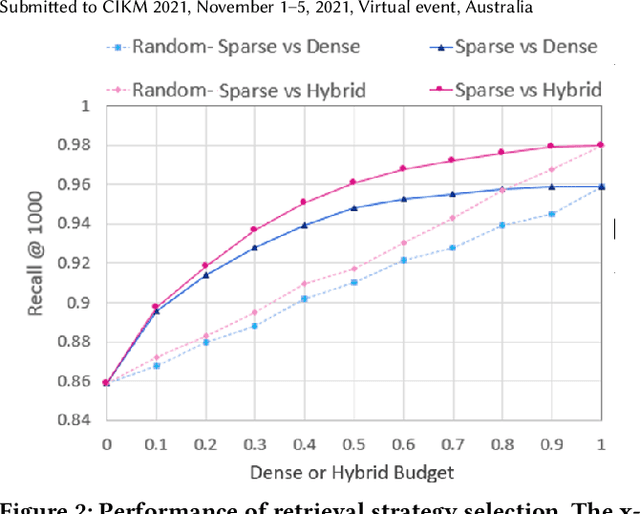
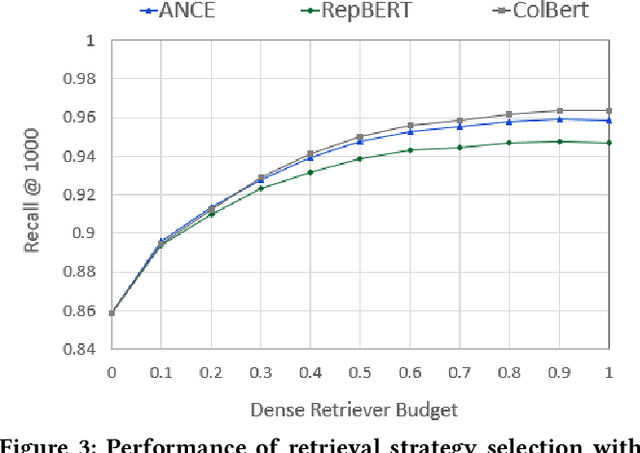
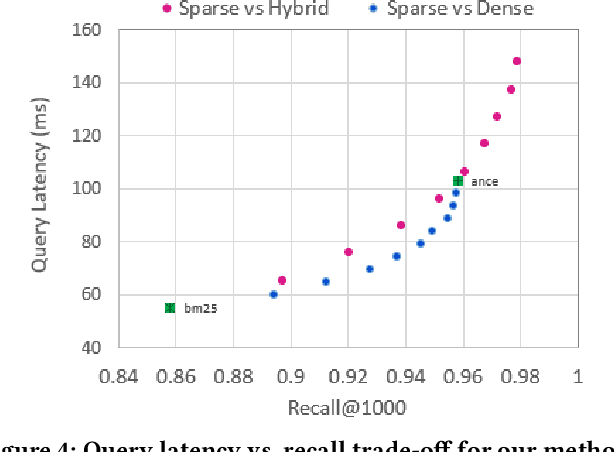
Over the last few years, contextualized pre-trained transformer models such as BERT have provided substantial improvements on information retrieval tasks. Recent approaches based on pre-trained transformer models such as BERT, fine-tune dense low-dimensional contextualized representations of queries and documents in embedding space. While these dense retrievers enjoy substantial retrieval effectiveness improvements compared to sparse retrievers, they are computationally intensive, requiring substantial GPU resources, and dense retrievers are known to be more expensive from both time and resource perspectives. In addition, sparse retrievers have been shown to retrieve complementary information with respect to dense retrievers, leading to proposals for hybrid retrievers. These hybrid retrievers leverage low-cost, exact-matching based sparse retrievers along with dense retrievers to bridge the semantic gaps between query and documents. In this work, we address this trade-off between the cost and utility of sparse vs dense retrievers by proposing a classifier to select a suitable retrieval strategy (i.e., sparse vs. dense vs. hybrid) for individual queries. Leveraging sparse retrievers for queries which can be answered with sparse retrievers decreases the number of calls to GPUs. Consequently, while utility is maintained, query latency decreases. Although we use less computational resources and spend less time, we still achieve improved performance. Our classifier can select between sparse and dense retrieval strategies based on the query alone. We conduct experiments on the MS MARCO passage dataset demonstrating an improved range of efficiency/effectiveness trade-offs between purely sparse, purely dense or hybrid retrieval strategies, allowing an appropriate strategy to be selected based on a target latency and resource budget.
Shallow pooling for sparse labels
Aug 31, 2021
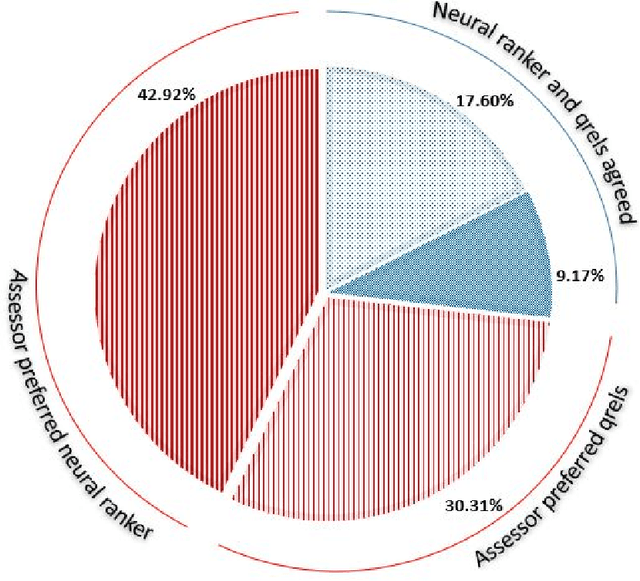
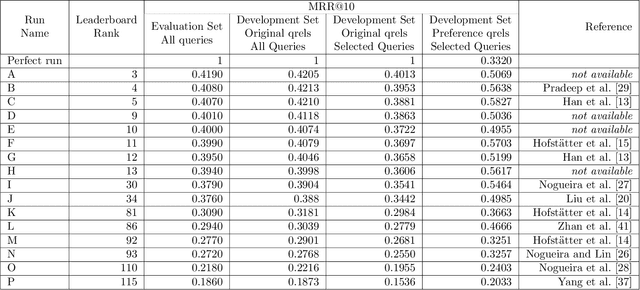
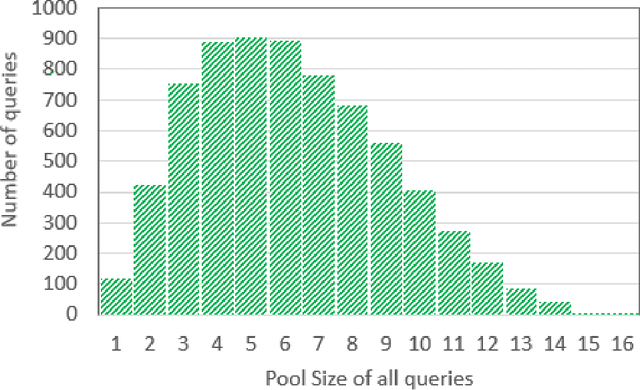
Recent years have seen enormous gains in core IR tasks, including document and passage ranking. Datasets and leaderboards, and in particular the MS MARCO datasets, illustrate the dramatic improvements achieved by modern neural rankers. When compared with traditional test collections, the MS MARCO datasets employ substantially more queries with substantially fewer known relevant items per query. Given the sparsity of these relevance labels, the MS MARCO leaderboards track improvements with mean reciprocal rank (MRR). In essence, a relevant item is treated as the "right answer", with rankers scored on their ability to place this item high in the ranking. In working with these sparse labels, we have observed that the top items returned by a ranker often appear superior to judged relevant items. To test this observation, we employed crowdsourced workers to make preference judgments between the top item returned by a modern neural ranking stack and a judged relevant item. The results support our observation. If we imagine a perfect ranker under MRR, with a score of 1 on all queries, our preference judgments indicate that a searcher would prefer the top result from a modern neural ranking stack more frequently than the top result from the imaginary perfect ranker, making our neural ranker "better than perfect". To understand the implications for the leaderboard, we pooled the top document from available runs near the top of the passage ranking leaderboard for over 500 queries. We employed crowdsourced workers to make preference judgments over these pools and re-evaluated the runs. Our results support our concerns that current MS MARCO datasets may no longer be able to recognize genuine improvements in rankers. In future, if rankers are measured against a single "right answer", this answer should be the best answer or most preferred answer, and maintained with ongoing judgments.