 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Efficiency/Effectiveness Trade-offs for Dense vs. Sparse Retrieval Strategy Selection
Paper and Code
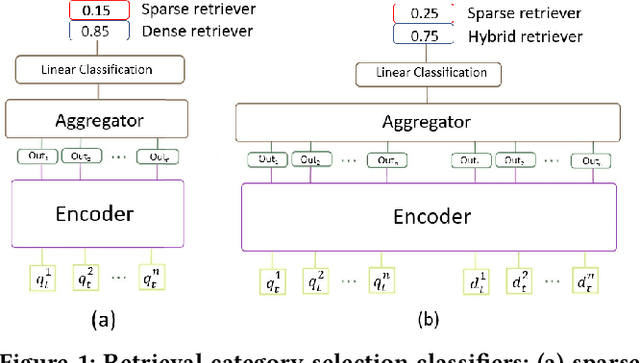
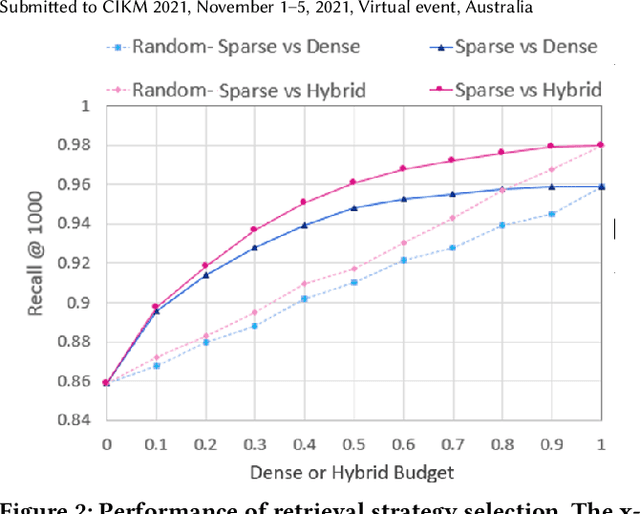
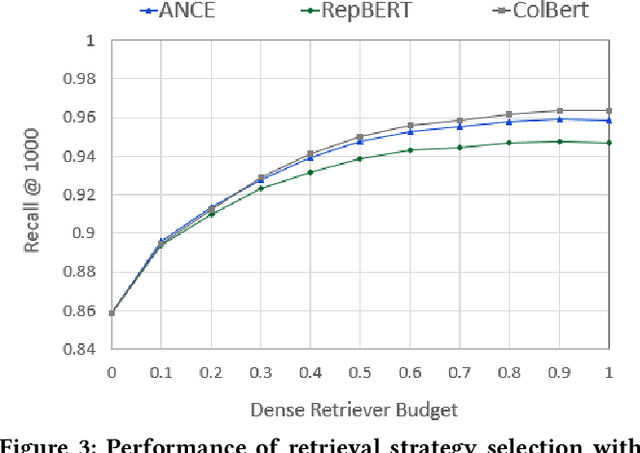
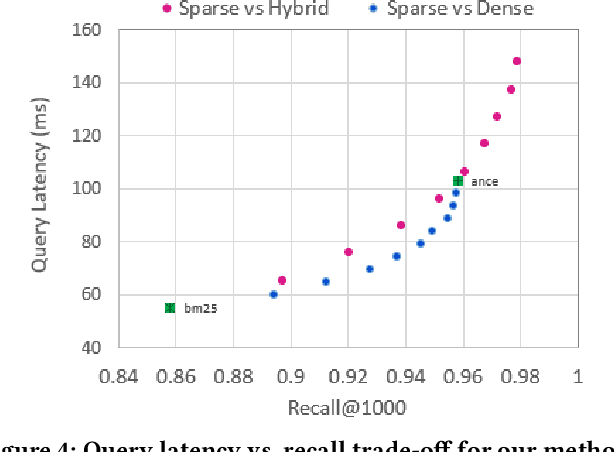
Over the last few years, contextualized pre-trained transformer models such as BERT have provided substantial improvements on information retrieval tasks. Recent approaches based on pre-trained transformer models such as BERT, fine-tune dense low-dimensional contextualized representations of queries and documents in embedding space. While these dense retrievers enjoy substantial retrieval effectiveness improvements compared to sparse retrievers, they are computationally intensive, requiring substantial GPU resources, and dense retrievers are known to be more expensive from both time and resource perspectives. In addition, sparse retrievers have been shown to retrieve complementary information with respect to dense retrievers, leading to proposals for hybrid retrievers. These hybrid retrievers leverage low-cost, exact-matching based sparse retrievers along with dense retrievers to bridge the semantic gaps between query and documents. In this work, we address this trade-off between the cost and utility of sparse vs dense retrievers by proposing a classifier to select a suitable retrieval strategy (i.e., sparse vs. dense vs. hybrid) for individual queries. Leveraging sparse retrievers for queries which can be answered with sparse retrievers decreases the number of calls to GPUs. Consequently, while utility is maintained, query latency decreases. Although we use less computational resources and spend less time, we still achieve improved performance. Our classifier can select between sparse and dense retrieval strategies based on the query alone. We conduct experiments on the MS MARCO passage dataset demonstrating an improved range of efficiency/effectiveness trade-offs between purely sparse, purely dense or hybrid retrieval strategies, allowing an appropriate strategy to be selected based on a target latency and resource budget.