 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Query to Configuration for Retrieval Agents
May 26, 2026Modern retrieval agents expose many configuration choices -- LLM, retriever, number of documents, number of hops, and synthesis strategy -- each shaping both answer quality and serving cost. Today, these pipelines are typically hand-tuned once per workload, leaving substantial per-query optimization untapped. We formulate the problem: given a natural-language query and either an accuracy or a budget target, select from a predefined pipeline catalog the configuration that minimizes cost or maximizes accuracy at inference time. We propose **BRANE**, which uses an LLM to convert each query into workload-specific characteristics, then trains a lightweight per-configuration predictor that estimates whether the pipeline will answer the query correctly. At inference time, **BRANE** selects the configuration that maximizes predicted correctness penalized by cost, exposing a tunable cost-quality tradeoff without retraining. Across MuSiQue, BrowseComp-Plus, and FinanceBench, **BRANE** consistently pushes the cost-quality Pareto frontier, matches the best fixed configuration's accuracy at up to 89% lower cost, and outperforms LLM-routing, rule-based, and fine-tuned Qwen3-4B baselines. These results show that per-query configuration of the full retrieval pipeline is a practical alternative to static workload-level tuning.
RAG over Thinking Traces Can Improve Reasoning Tasks
May 05, 2026Retrieval-augmented generation (RAG) has proven effective for knowledge-intensive tasks, but is widely believed to offer limited benefit for reasoning-intensive problems such as math and code generation. We challenge this assumption by showing that the limitation lies not in RAG itself, but in the choice of corpus. Instead of retrieving documents, we propose retrieving thinking traces, i.e., intermediate thinking trajectories generated during problem solving attempts. We show that thinking traces are already a strong retrieval source, and further introduce T3, an offline method that transforms them into structured, retrieval-friendly representations, to improve usability. Using these traces as a corpus, a simple retrieve-then-generate pipeline consistently improves reasoning performance across strong models and benchmarks such as AIME 2025--2026, LiveCodeBench, and GPQA-Diamond, outperforming both non-RAG baselines and retrieval over standard web corpora. For instance, on AIME, RAG with traces generated by Gemini-2-thinking achieves relative gains of +56.3%, +8.6%, and +7.6% for Gemini-2.5-Flash, GPT-OSS-120B, and GPT-5, respectively, even though these are more recent models. Interestingly, RAG on T3 also incurs little or no extra inference cost, and can even reduce inference cost by up to $15%$. Overall, our results suggest that thinking traces are an effective retrieval corpus for reasoning tasks, and transforming them into structured, compact, or diagnostic representations unlocks even stronger gains. Code available at https://github.com/Narabzad/t3.
PeeriScope: A Multi-Faceted Framework for Evaluating Peer Review Quality
Apr 27, 2026The increasing scale and variability of peer review in scholarly venues has created an urgent need for systematic, interpretable, and extensible tools to assess review quality. We present PeeriScope, a modular platform that integrates structured features, rubric-guided large language model assessments, and supervised prediction to evaluate peer review quality along multiple dimensions. Designed for openness and integration, PeeriScope provides both a public interface and a documented API, supporting practical deployment and research extensibility. The demonstration illustrates its use for reviewer self-assessment, editorial triage, and large-scale auditing, and it enables the continued development of quality evaluation methods within scientific peer review. PeeriScope is available both as a live demo at https://app.reviewer.ly/app/peeriscope and via API services at https://github.com/Reviewerly-Inc/Peeriscope.
Can QPP Choose the Right Query Variant? Evaluating Query Variant Selection for RAG Pipelines
Apr 24, 2026Large Language Models (LLMs) have made query reformulation ubiquitous in modern retrieval and Retrieval-Augmented Generation (RAG) pipelines, enabling the generation of multiple semantically equivalent query variants. However, executing the full pipeline for every reformulation is computationally expensive, motivating selective execution: can we identify the best query variant before incurring downstream retrieval and generation costs? We investigate Query Performance Prediction (QPP) as a mechanism for variant selection across ad-hoc retrieval and end-to-end RAG. Unlike traditional QPP, which estimates query difficulty across topics, we study intra-topic discrimination - selecting the optimal reformulation among competing variants of the same information need. Through large-scale experiments on TREC-RAG using both sparse and dense retrievers, we evaluate pre- and post-retrieval predictors under correlation- and decision-based metrics. Our results reveal a systematic divergence between retrieval and generation objectives: variants that maximize ranking metrics such as nDCG often fail to produce the best generated answers, exposing a "utility gap" between retrieval relevance and generation fidelity. Nevertheless, QPP can reliably identify variants that improve end-to-end quality over the original query. Notably, lightweight pre-retrieval predictors frequently match or outperform more expensive post-retrieval methods, offering a latency-efficient approach to robust RAG.
Peerispect: Claim Verification in Scientific Peer Reviews
Apr 19, 2026Peer review is central to scientific publishing, yet reviewers frequently include claims that are subjective, rhetorical, or misaligned with the submitted work. Assessing whether review statements are factual and verifiable is crucial for fairness and accountability. At the scale of modern conferences and journals, manually inspecting the grounding of such claims is infeasible. We present Peerispect, an interactive system that operationalizes claim-level verification in peer reviews by extracting check-worthy claims from peer reviews, retrieving relevant evidence from the manuscript, and verifying the claims through natural language inference. Results are presented through a visual interface that highlights evidence directly in the paper, enabling rapid inspection and interpretation. Peerispect is designed as a modular Information Retrieval (IR) pipeline, supporting alternative retrievers, rerankers, and verifiers, and is intended for use by reviewers, authors, and program committees. We demonstrate Peerispect through a live, publicly available demo (https://app.reviewer.ly/app/peerispect) and API services (https://github.com/Reviewerly-Inc/Peerispect), accompanied by a video tutorial (https://www.youtube.com/watch?v=pc9RkvkUh14).
PeerPrism: Peer Evaluation Expertise vs Review-writing AI
Apr 16, 2026Large Language Models (LLMs) are increasingly used in scientific peer review, assisting with drafting, rewriting, expansion, and refinement. However, existing peer-review LLM detection methods largely treat authorship as a binary problem-human vs. AI-without accounting for the hybrid nature of modern review workflows. In practice, evaluative ideas and surface realization may originate from different sources, creating a spectrum of human-AI collaboration. In this work, we introduce PeerPrism, a large-scale benchmark of 20,690 peer reviews explicitly designed to disentangle idea provenance from text provenance. We construct controlled generation regimes spanning fully human, fully synthetic, and multiple hybrid transformations. This design enables systematic evaluation of whether detectors identify the origin of the surface text or the origin of the evaluative reasoning. We benchmark state-of-the-art LLM text detection methods on PeerPrism. While several methods achieve high accuracy on the standard binary task (human vs. fully synthetic), their predictions diverge sharply under hybrid regimes. In particular, when ideas originate from humans but the surface text is AI-generated, detectors frequently disagree and produce contradictory classifications. Accompanied by stylometric and semantic analyses, our results show that current detection methods conflate surface realization with intellectual contribution. Overall, we demonstrate that LLM detection in peer review cannot be reduced to a binary attribution problem. Instead, authorship must be modeled as a multidimensional construct spanning semantic reasoning and stylistic realization. PeerPrism is the first benchmark evaluating human-AI collaboration in these settings. We release all code, data, prompts, and evaluation scripts to facilitate reproducible research at https://github.com/Reviewerly-Inc/PeerPrism.
ReFormeR: Learning and Applying Explicit Query Reformulation Patterns
Apr 01, 2026We present ReFormeR, a pattern-guided approach for query reformulation. Instead of prompting a language model to generate reformulations of a query directly, ReFormeR first elicits short reformulation patterns from pairs of initial queries and empirically stronger reformulations, consolidates them into a compact library of transferable reformulation patterns, and then selects an appropriate reformulation pattern for a new query given its retrieval context. The selected pattern constrains query reformulation to controlled operations such as sense disambiguation, vocabulary grounding, or discriminative facet addition, to name a few. As such, our proposed approach makes the reformulation policy explicit through these reformulation patterns, guiding the LLM towards targeted and effective query reformulations. Our extensive experiments on TREC DL 2019, DL 2020, and DL Hard show consistent improvements over classical feedback methods and recent LLM-based query reformulation and expansion approaches.
From Noise to Order: Learning to Rank via Denoising Diffusion
Feb 12, 2026In information retrieval (IR), learning-to-rank (LTR) methods have traditionally limited themselves to discriminative machine learning approaches that model the probability of the document being relevant to the query given some feature representation of the query-document pair. In this work, we propose an alternative denoising diffusion-based deep generative approach to LTR that instead models the full joint distribution over feature vectors and relevance labels. While in the discriminative setting, an over-parameterized ranking model may find different ways to fit the training data, we hypothesize that candidate solutions that can explain the full data distribution under the generative setting produce more robust ranking models. With this motivation, we propose DiffusionRank that extends TabDiff, an existing denoising diffusion-based generative model for tabular datasets, to create generative equivalents of classical discriminative pointwise and pairwise LTR objectives. Our empirical results demonstrate significant improvements from DiffusionRank models over their discriminative counterparts. Our work points to a rich space for future research exploration on how we can leverage ongoing advancements in deep generative modeling approaches, such as diffusion, for learning-to-rank in IR.
DeepScholar-Bench: A Live Benchmark and Automated Evaluation for Generative Research Synthesis
Aug 27, 2025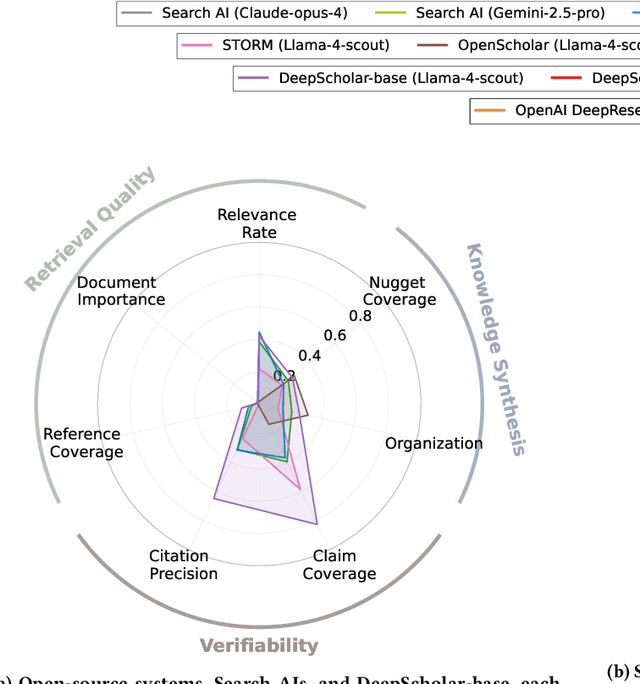
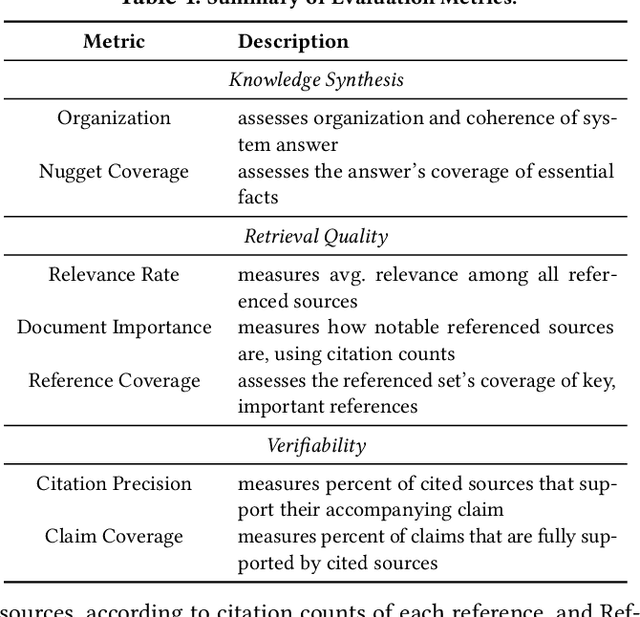
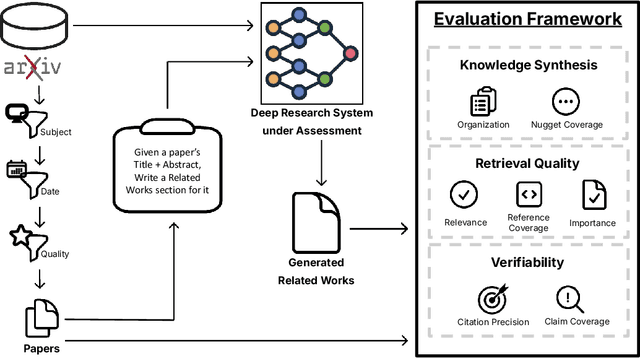
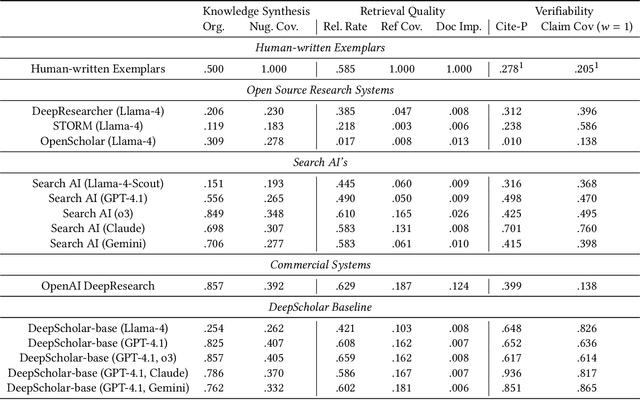
The ability to research and synthesize knowledge is central to human expertise and progress. An emerging class of systems promises these exciting capabilities through generative research synthesis, performing retrieval over the live web and synthesizing discovered sources into long-form, cited summaries. However, evaluating such systems remains an open challenge: existing question-answering benchmarks focus on short-form factual responses, while expert-curated datasets risk staleness and data contamination. Both fail to capture the complexity and evolving nature of real research synthesis tasks. In this work, we introduce DeepScholar-bench, a live benchmark and holistic, automated evaluation framework designed to evaluate generative research synthesis. DeepScholar-bench draws queries from recent, high-quality ArXiv papers and focuses on a real research synthesis task: generating the related work sections of a paper by retrieving, synthesizing, and citing prior research. Our evaluation framework holistically assesses performance across three key dimensions, knowledge synthesis, retrieval quality, and verifiability. We also develop DeepScholar-base, a reference pipeline implemented efficiently using the LOTUS API. Using the DeepScholar-bench framework, we perform a systematic evaluation of prior open-source systems, search AI's, OpenAI's DeepResearch, and DeepScholar-base. We find that DeepScholar-base establishes a strong baseline, attaining competitive or higher performance than each other method. We also find that DeepScholar-bench remains far from saturated, with no system exceeding a score of $19\%$ across all metrics. These results underscore the difficulty of DeepScholar-bench, as well as its importance for progress towards AI systems capable of generative research synthesis. We make our code available at https://github.com/guestrin-lab/deepscholar-bench.
Benchmarking LLM-based Relevance Judgment Methods
Apr 17, 2025Large Language Models (LLMs) are increasingly deployed in both academic and industry settings to automate the evaluation of information seeking systems, particularly by generating graded relevance judgments. Previous work on LLM-based relevance assessment has primarily focused on replicating graded human relevance judgments through various prompting strategies. However, there has been limited exploration of alternative assessment methods or comprehensive comparative studies. In this paper, we systematically compare multiple LLM-based relevance assessment methods, including binary relevance judgments, graded relevance assessments, pairwise preference-based methods, and two nugget-based evaluation methods~--~document-agnostic and document-dependent. In addition to a traditional comparison based on system rankings using Kendall correlations, we also examine how well LLM judgments align with human preferences, as inferred from relevance grades. We conduct extensive experiments on datasets from three TREC Deep Learning tracks 2019, 2020 and 2021 as well as the ANTIQUE dataset, which focuses on non-factoid open-domain question answering. As part of our data release, we include relevance judgments generated by both an open-source (Llama3.2b) and a commercial (gpt-4o) model. Our goal is to \textit{reproduce} various LLM-based relevance judgment methods to provide a comprehensive comparison. All code, data, and resources are publicly available in our GitHub Repository at https://github.com/Narabzad/llm-relevance-judgement-comparison.