 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Rankers as Relevance Judges
Jan 08, 2026Using large language models (LLMs) to predict relevance judgments has shown promising results. Most studies treat this task as a distinct research line, e.g., focusing on prompt design for predicting relevance labels given a query and passage. However, predicting relevance judgments is essentially a form of relevance prediction, a problem extensively studied in tasks such as re-ranking. Despite this potential overlap, little research has explored reusing or adapting established re-ranking methods to predict relevance judgments, leading to potential resource waste and redundant development. To bridge this gap, we reproduce re-rankers in a re-ranker-as-relevance-judge setup. We design two adaptation strategies: (i) using binary tokens (e.g., "true" and "false") generated by a re-ranker as direct judgments, and (ii) converting continuous re-ranking scores into binary labels via thresholding. We perform extensive experiments on TREC-DL 2019 to 2023 with 8 re-rankers from 3 families, ranging from 220M to 32B, and analyse the evaluation bias exhibited by re-ranker-based judges. Results show that re-ranker-based relevance judges, under both strategies, can outperform UMBRELA, a state-of-the-art LLM-based relevance judge, in around 40% to 50% of the cases; they also exhibit strong self-preference towards their own and same-family re-rankers, as well as cross-family bias.
Adaptive Personalized Conversational Information Retrieval
Aug 12, 2025Personalized conversational information retrieval (CIR) systems aim to satisfy users' complex information needs through multi-turn interactions by considering user profiles. However, not all search queries require personalization. The challenge lies in appropriately incorporating personalization elements into search when needed. Most existing studies implicitly incorporate users' personal information and conversational context using large language models without distinguishing the specific requirements for each query turn. Such a ``one-size-fits-all'' personalization strategy might lead to sub-optimal results. In this paper, we propose an adaptive personalization method, in which we first identify the required personalization level for a query and integrate personalized queries with other query reformulations to produce various enhanced queries. Then, we design a personalization-aware ranking fusion approach to assign fusion weights dynamically to different reformulated queries, depending on the required personalization level. The proposed adaptive personalized conversational information retrieval framework APCIR is evaluated on two TREC iKAT datasets. The results confirm the effectiveness of adaptive personalization of APCIR by outperforming state-of-the-art methods.
UniConv: Unifying Retrieval and Response Generation for Large Language Models in Conversations
Jul 09, 2025
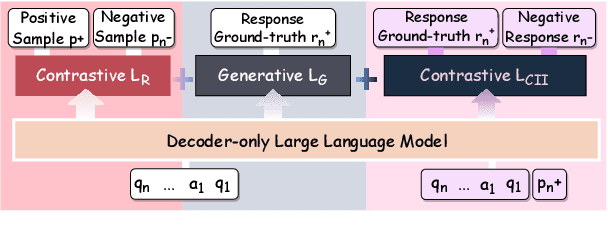
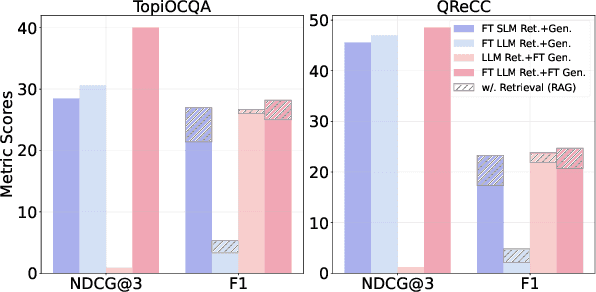
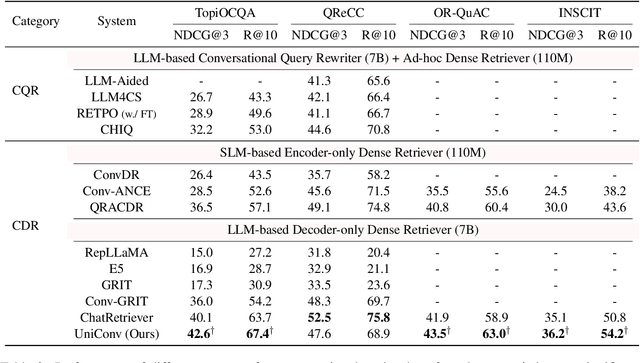
The rapid advancement of conversational search systems revolutionizes how information is accessed by enabling the multi-turn interaction between the user and the system. Existing conversational search systems are usually built with two different models. This separation restricts the system from leveraging the intrinsic knowledge of the models simultaneously, which cannot ensure the effectiveness of retrieval benefiting the generation. The existing studies for developing unified models cannot fully address the aspects of understanding conversational context, managing retrieval independently, and generating responses. In this paper, we explore how to unify dense retrieval and response generation for large language models in conversation. We conduct joint fine-tuning with different objectives and design two mechanisms to reduce the inconsistency risks while mitigating data discrepancy. The evaluations on five conversational search datasets demonstrate that our unified model can mutually improve both tasks and outperform the existing baselines.
Conversational Search: From Fundamentals to Frontiers in the LLM Era
Jun 12, 2025Conversational search enables multi-turn interactions between users and systems to fulfill users' complex information needs. During this interaction, the system should understand the users' search intent within the conversational context and then return the relevant information through a flexible, dialogue-based interface. The recent powerful large language models (LLMs) with capacities of instruction following, content generation, and reasoning, attract significant attention and advancements, providing new opportunities and challenges for building up intelligent conversational search systems. This tutorial aims to introduce the connection between fundamentals and the emerging topics revolutionized by LLMs in the context of conversational search. It is designed for students, researchers, and practitioners from both academia and industry. Participants will gain a comprehensive understanding of both the core principles and cutting-edge developments driven by LLMs in conversational search, equipping them with the knowledge needed to contribute to the development of next-generation conversational search systems.
Improving the Reusability of Conversational Search Test Collections
Mar 12, 2025Incomplete relevance judgments limit the reusability of test collections. When new systems are compared to previous systems that contributed to the pool, they often face a disadvantage. This is due to pockets of unjudged documents (called holes) in the test collection that the new systems return. The very nature of Conversational Search (CS) means that these holes are potentially larger and more problematic when evaluating systems. In this paper, we aim to extend CS test collections by employing Large Language Models (LLMs) to fill holes by leveraging existing judgments. We explore this problem using TREC iKAT 23 and TREC CAsT 22 collections, where information needs are highly dynamic and the responses are much more varied, leaving bigger holes to fill. Our experiments reveal that CS collections show a trend towards less reusability in deeper turns. Also, fine-tuning the Llama 3.1 model leads to high agreement with human assessors, while few-shot prompting the ChatGPT results in low agreement with humans. Consequently, filling the holes of a new system using ChatGPT leads to a higher change in the location of the new system. While regenerating the assessment pool with few-shot prompting the ChatGPT model and using it for evaluation achieves a high rank correlation with human-assessed pools. We show that filling the holes using few-shot training the Llama 3.1 model enables a fairer comparison between the new system and the systems contributed to the pool. Our hole-filling model based on few-shot training of the Llama 3.1 model can improve the reusability of test collections.
Generative Retrieval with Few-shot Indexing
Aug 04, 2024



Existing generative retrieval (GR) approaches rely on training-based indexing, i.e., fine-tuning a model to memorise the associations between a query and the document identifier (docid) of a relevant document. Training-based indexing has three limitations: high training overhead, under-utilization of the pre-trained knowledge of large language models (LLMs), and challenges in adapting to a dynamic document corpus. To address the above issues, we propose a novel few-shot indexing-based GR framework (Few-Shot GR). It has a novel few-shot indexing process, where we prompt an LLM to generate docids for all documents in a corpus, ultimately creating a docid bank for the entire corpus. During retrieval, we feed a query to the same LLM and constrain it to generate a docid within the docid bank created during indexing, and then map the generated docid back to its corresponding document. Few-Shot GR relies solely on prompting an LLM without requiring any training, making it more efficient. Moreover, we devise few-shot indexing with one-to-many mapping to further enhance Few-Shot GR. Experiments show that Few-Shot GR achieves superior performance to state-of-the-art GR methods that require heavy training.
Can We Use Large Language Models to Fill Relevance Judgment Holes?
May 09, 2024Incomplete relevance judgments limit the re-usability of test collections. When new systems are compared against previous systems used to build the pool of judged documents, they often do so at a disadvantage due to the ``holes'' in test collection (i.e., pockets of un-assessed documents returned by the new system). In this paper, we take initial steps towards extending existing test collections by employing Large Language Models (LLM) to fill the holes by leveraging and grounding the method using existing human judgments. We explore this problem in the context of Conversational Search using TREC iKAT, where information needs are highly dynamic and the responses (and, the results retrieved) are much more varied (leaving bigger holes). While previous work has shown that automatic judgments from LLMs result in highly correlated rankings, we find substantially lower correlates when human plus automatic judgments are used (regardless of LLM, one/two/few shot, or fine-tuned). We further find that, depending on the LLM employed, new runs will be highly favored (or penalized), and this effect is magnified proportionally to the size of the holes. Instead, one should generate the LLM annotations on the whole document pool to achieve more consistent rankings with human-generated labels. Future work is required to prompt engineering and fine-tuning LLMs to reflect and represent the human annotations, in order to ground and align the models, such that they are more fit for purpose.
Ranked List Truncation for Large Language Model-based Re-Ranking
Apr 28, 2024We study ranked list truncation (RLT) from a novel "retrieve-then-re-rank" perspective, where we optimize re-ranking by truncating the retrieved list (i.e., trim re-ranking candidates). RLT is crucial for re-ranking as it can improve re-ranking efficiency by sending variable-length candidate lists to a re-ranker on a per-query basis. It also has the potential to improve re-ranking effectiveness. Despite its importance, there is limited research into applying RLT methods to this new perspective. To address this research gap, we reproduce existing RLT methods in the context of re-ranking, especially newly emerged large language model (LLM)-based re-ranking. In particular, we examine to what extent established findings on RLT for retrieval are generalizable to the "retrieve-then-re-rank" setup from three perspectives: (i) assessing RLT methods in the context of LLM-based re-ranking with lexical first-stage retrieval, (ii) investigating the impact of different types of first-stage retrievers on RLT methods, and (iii) investigating the impact of different types of re-rankers on RLT methods. We perform experiments on the TREC 2019 and 2020 deep learning tracks, investigating 8 RLT methods for pipelines involving 3 retrievers and 2 re-rankers. We reach new insights into RLT methods in the context of re-ranking.
Query Performance Prediction using Relevance Judgments Generated by Large Language Models
Apr 01, 2024Query performance prediction (QPP) aims to estimate the retrieval quality of a search system for a query without human relevance judgments. Previous QPP methods typically return a single scalar value and do not require the predicted values to approximate a specific information retrieval (IR) evaluation measure, leading to certain drawbacks: (i) a single scalar is insufficient to accurately represent different IR evaluation measures, especially when metrics do not highly correlate, and (ii) a single scalar limits the interpretability of QPP methods because solely using a scalar is insufficient to explain QPP results. To address these issues, we propose a QPP framework using automatically generated relevance judgments (QPP-GenRE), which decomposes QPP into independent subtasks of judging the relevance of each item in a ranked list to a given query. This allows us to predict any IR evaluation measure using the generated relevance judgments as pseudo-labels; Also, this allows us to interpret predicted IR evaluation measures, and identify, track and rectify errors in generated relevance judgments to improve QPP quality. We judge relevance by leveraging a leading open-source large language model (LLM), LLaMA, to ensure scientific reproducibility. In doing so, we address two main challenges: (i) excessive computational costs of judging the entire corpus for predicting a recall-based metric, and (ii) poor performance in prompting LLaMA in a zero-/few-shot manner. We devise an approximation strategy to predict a recall-oriented IR measure and propose to fine-tune LLaMA using human-labeled relevance judgments. Experiments on the TREC 2019-2022 deep learning tracks show that QPP-GenRE achieves state-of-the-art QPP accuracy for both lexical and neural rankers in both precision- and recall-oriented metrics.
Self-seeding and Multi-intent Self-instructing LLMs for Generating Intent-aware Information-Seeking dialogs
Feb 18, 2024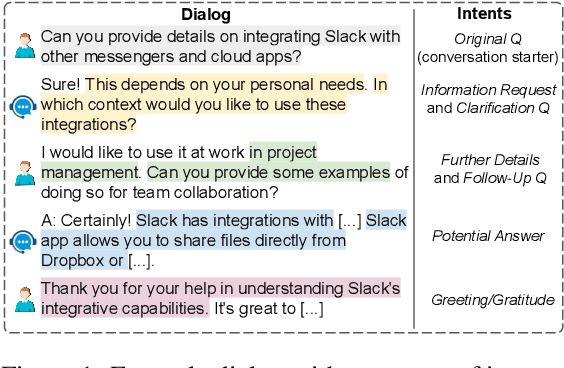
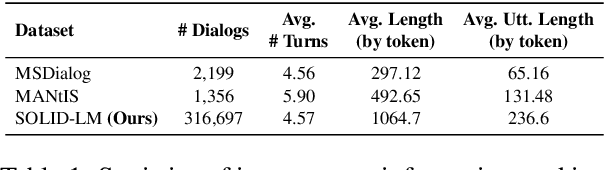

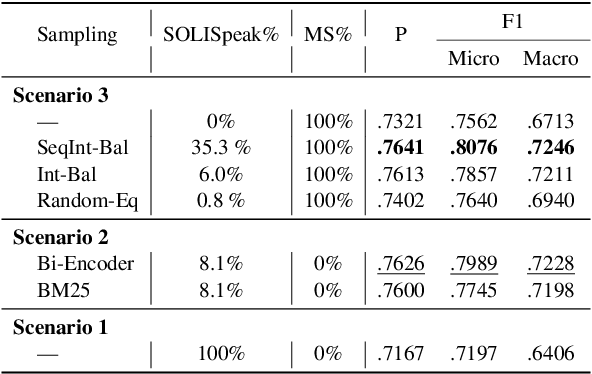
Identifying user intents in information-seeking dialogs is crucial for a system to meet user's information needs. Intent prediction (IP) is challenging and demands sufficient dialogs with human-labeled intents for training. However, manually annotating intents is resource-intensive. While large language models (LLMs) have been shown to be effective in generating synthetic data, there is no study on using LLMs to generate intent-aware information-seeking dialogs. In this paper, we focus on leveraging LLMs for zero-shot generation of large-scale, open-domain, and intent-aware information-seeking dialogs. We propose SOLID, which has novel self-seeding and multi-intent self-instructing schemes. The former improves the generation quality by using the LLM's own knowledge scope to initiate dialog generation; the latter prompts the LLM to generate utterances sequentially, and mitigates the need for manual prompt design by asking the LLM to autonomously adapt its prompt instruction when generating complex multi-intent utterances. Furthermore, we propose SOLID-RL, which is further trained to generate a dialog in one step on the data generated by SOLID. We propose a length-based quality estimation mechanism to assign varying weights to SOLID-generated dialogs based on their quality during the training process of SOLID-RL. We use SOLID and SOLID-RL to generate more than 300k intent-aware dialogs, surpassing the size of existing datasets. Experiments show that IP methods trained on dialogs generated by SOLID and SOLID-RL achieve better IP quality than ones trained on human-generated dialogs.