 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHotelMatch-LLM: Joint Multi-Task Training of Small and Large Language Models for Efficient Multimodal Hotel Retrieval
Jun 08, 2025
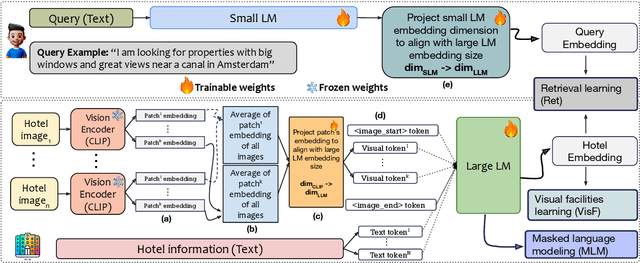

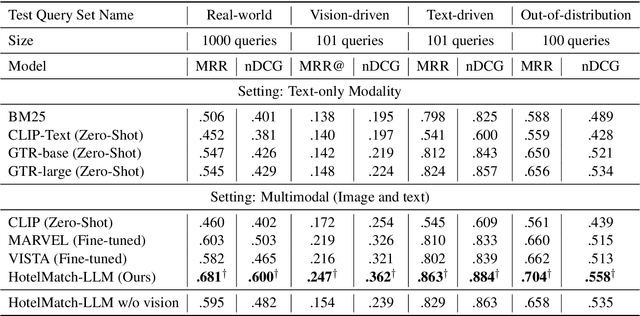
We present HotelMatch-LLM, a multimodal dense retrieval model for the travel domain that enables natural language property search, addressing the limitations of traditional travel search engines which require users to start with a destination and editing search parameters. HotelMatch-LLM features three key innovations: (1) Domain-specific multi-task optimization with three novel retrieval, visual, and language modeling objectives; (2) Asymmetrical dense retrieval architecture combining a small language model (SLM) for efficient online query processing and a large language model (LLM) for embedding hotel data; and (3) Extensive image processing to handle all property image galleries. Experiments on four diverse test sets show HotelMatch-LLM significantly outperforms state-of-the-art models, including VISTA and MARVEL. Specifically, on the test set -- main query type -- we achieve 0.681 for HotelMatch-LLM compared to 0.603 for the most effective baseline, MARVEL. Our analysis highlights the impact of our multi-task optimization, the generalizability of HotelMatch-LLM across LLM architectures, and its scalability for processing large image galleries.
Can Large Language Models Serve as Effective Classifiers for Hierarchical Multi-Label Classification of Scientific Documents at Industrial Scale?
Dec 06, 2024We address the task of hierarchical multi-label classification (HMC) of scientific documents at an industrial scale, where hundreds of thousands of documents must be classified across thousands of dynamic labels. The rapid growth of scientific publications necessitates scalable and efficient methods for classification, further complicated by the evolving nature of taxonomies--where new categories are introduced, existing ones are merged, and outdated ones are deprecated. Traditional machine learning approaches, which require costly retraining with each taxonomy update, become impractical due to the high overhead of labelled data collection and model adaptation. Large Language Models (LLMs) have demonstrated great potential in complex tasks such as multi-label classification. However, applying them to large and dynamic taxonomies presents unique challenges as the vast number of labels can exceed LLMs' input limits. In this paper, we present novel methods that combine the strengths of LLMs with dense retrieval techniques to overcome these challenges. Our approach avoids retraining by leveraging zero-shot HMC for real-time label assignment. We evaluate the effectiveness of our methods on SSRN, a large repository of preprints spanning multiple disciplines, and demonstrate significant improvements in both classification accuracy and cost-efficiency. By developing a tailored evaluation framework for dynamic taxonomies and publicly releasing our code, this research provides critical insights into applying LLMs for document classification, where the number of classes corresponds to the number of nodes in a large taxonomy, at an industrial scale.
Generative Retrieval with Few-shot Indexing
Aug 04, 2024



Existing generative retrieval (GR) approaches rely on training-based indexing, i.e., fine-tuning a model to memorise the associations between a query and the document identifier (docid) of a relevant document. Training-based indexing has three limitations: high training overhead, under-utilization of the pre-trained knowledge of large language models (LLMs), and challenges in adapting to a dynamic document corpus. To address the above issues, we propose a novel few-shot indexing-based GR framework (Few-Shot GR). It has a novel few-shot indexing process, where we prompt an LLM to generate docids for all documents in a corpus, ultimately creating a docid bank for the entire corpus. During retrieval, we feed a query to the same LLM and constrain it to generate a docid within the docid bank created during indexing, and then map the generated docid back to its corresponding document. Few-Shot GR relies solely on prompting an LLM without requiring any training, making it more efficient. Moreover, we devise few-shot indexing with one-to-many mapping to further enhance Few-Shot GR. Experiments show that Few-Shot GR achieves superior performance to state-of-the-art GR methods that require heavy training.
MAGIC: Generating Self-Correction Guideline for In-Context Text-to-SQL
Jun 18, 2024Self-correction in text-to-SQL is the process of prompting large language model (LLM) to revise its previously incorrectly generated SQL, and commonly relies on manually crafted self-correction guidelines by human experts that are not only labor-intensive to produce but also limited by the human ability in identifying all potential error patterns in LLM responses. We introduce MAGIC, a novel multi-agent method that automates the creation of the self-correction guideline. MAGIC uses three specialized agents: a manager, a correction, and a feedback agent. These agents collaborate on the failures of an LLM-based method on the training set to iteratively generate and refine a self-correction guideline tailored to LLM mistakes, mirroring human processes but without human involvement. Our extensive experiments show that MAGIC's guideline outperforms expert human's created ones. We empirically find out that the guideline produced by MAGIC enhance the interpretability of the corrections made, providing insights in analyzing the reason behind the failures and successes of LLMs in self-correction. We make all agent interactions publicly available to the research community, to foster further research in this area, offering a synthetic dataset for future explorations into automatic self-correction guideline generation.
Ranked List Truncation for Large Language Model-based Re-Ranking
Apr 28, 2024We study ranked list truncation (RLT) from a novel "retrieve-then-re-rank" perspective, where we optimize re-ranking by truncating the retrieved list (i.e., trim re-ranking candidates). RLT is crucial for re-ranking as it can improve re-ranking efficiency by sending variable-length candidate lists to a re-ranker on a per-query basis. It also has the potential to improve re-ranking effectiveness. Despite its importance, there is limited research into applying RLT methods to this new perspective. To address this research gap, we reproduce existing RLT methods in the context of re-ranking, especially newly emerged large language model (LLM)-based re-ranking. In particular, we examine to what extent established findings on RLT for retrieval are generalizable to the "retrieve-then-re-rank" setup from three perspectives: (i) assessing RLT methods in the context of LLM-based re-ranking with lexical first-stage retrieval, (ii) investigating the impact of different types of first-stage retrievers on RLT methods, and (iii) investigating the impact of different types of re-rankers on RLT methods. We perform experiments on the TREC 2019 and 2020 deep learning tracks, investigating 8 RLT methods for pipelines involving 3 retrievers and 2 re-rankers. We reach new insights into RLT methods in the context of re-ranking.
Query Performance Prediction using Relevance Judgments Generated by Large Language Models
Apr 01, 2024Query performance prediction (QPP) aims to estimate the retrieval quality of a search system for a query without human relevance judgments. Previous QPP methods typically return a single scalar value and do not require the predicted values to approximate a specific information retrieval (IR) evaluation measure, leading to certain drawbacks: (i) a single scalar is insufficient to accurately represent different IR evaluation measures, especially when metrics do not highly correlate, and (ii) a single scalar limits the interpretability of QPP methods because solely using a scalar is insufficient to explain QPP results. To address these issues, we propose a QPP framework using automatically generated relevance judgments (QPP-GenRE), which decomposes QPP into independent subtasks of judging the relevance of each item in a ranked list to a given query. This allows us to predict any IR evaluation measure using the generated relevance judgments as pseudo-labels; Also, this allows us to interpret predicted IR evaluation measures, and identify, track and rectify errors in generated relevance judgments to improve QPP quality. We judge relevance by leveraging a leading open-source large language model (LLM), LLaMA, to ensure scientific reproducibility. In doing so, we address two main challenges: (i) excessive computational costs of judging the entire corpus for predicting a recall-based metric, and (ii) poor performance in prompting LLaMA in a zero-/few-shot manner. We devise an approximation strategy to predict a recall-oriented IR measure and propose to fine-tune LLaMA using human-labeled relevance judgments. Experiments on the TREC 2019-2022 deep learning tracks show that QPP-GenRE achieves state-of-the-art QPP accuracy for both lexical and neural rankers in both precision- and recall-oriented metrics.
CAUSE: Counterfactual Assessment of User Satisfaction Estimation in Task-Oriented Dialogue Systems
Mar 27, 2024
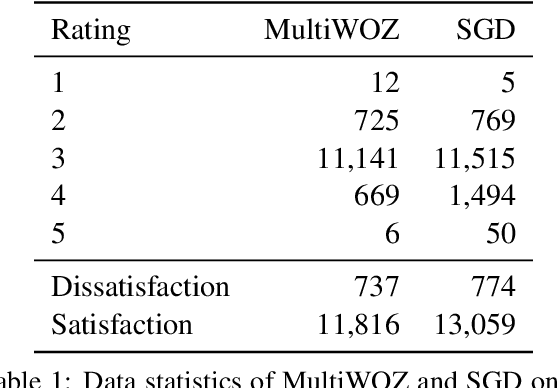
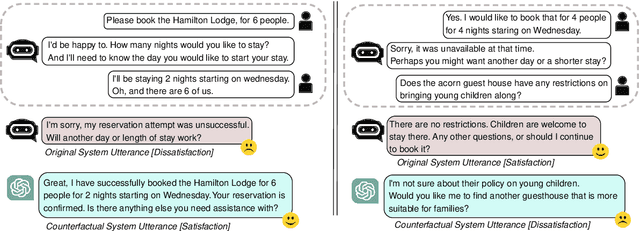
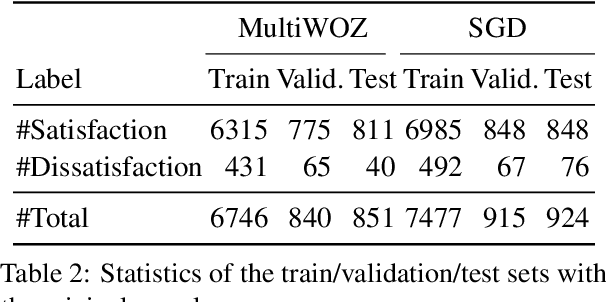
An important unexplored aspect in previous work on user satisfaction estimation for Task-Oriented Dialogue (TOD) systems is their evaluation in terms of robustness for the identification of user dissatisfaction: current benchmarks for user satisfaction estimation in TOD systems are highly skewed towards dialogues for which the user is satisfied. The effect of having a more balanced set of satisfaction labels on performance is unknown. However, balancing the data with more dissatisfactory dialogue samples requires further data collection and human annotation, which is costly and time-consuming. In this work, we leverage large language models (LLMs) and unlock their ability to generate satisfaction-aware counterfactual dialogues to augment the set of original dialogues of a test collection. We gather human annotations to ensure the reliability of the generated samples. We evaluate two open-source LLMs as user satisfaction estimators on our augmented collection against state-of-the-art fine-tuned models. Our experiments show that when used as few-shot user satisfaction estimators, open-source LLMs show higher robustness to the increase in the number of dissatisfaction labels in the test collection than the fine-tuned state-of-the-art models. Our results shed light on the need for data augmentation approaches for user satisfaction estimation in TOD systems. We release our aligned counterfactual dialogues, which are curated by human annotation, to facilitate further research on this topic.
Measuring Bias in a Ranked List using Term-based Representations
Mar 09, 2024In most recent studies, gender bias in document ranking is evaluated with the NFaiRR metric, which measures bias in a ranked list based on an aggregation over the unbiasedness scores of each ranked document. This perspective in measuring the bias of a ranked list has a key limitation: individual documents of a ranked list might be biased while the ranked list as a whole balances the groups' representations. To address this issue, we propose a novel metric called TExFAIR (term exposure-based fairness), which is based on two new extensions to a generic fairness evaluation framework, attention-weighted ranking fairness (AWRF). TExFAIR assesses fairness based on the term-based representation of groups in a ranked list: (i) an explicit definition of associating documents to groups based on probabilistic term-level associations, and (ii) a rank-biased discounting factor (RBDF) for counting non-representative documents towards the measurement of the fairness of a ranked list. We assess TExFAIR on the task of measuring gender bias in passage ranking, and study the relationship between TExFAIR and NFaiRR. Our experiments show that there is no strong correlation between TExFAIR and NFaiRR, which indicates that TExFAIR measures a different dimension of fairness than NFaiRR. With TExFAIR, we extend the AWRF framework to allow for the evaluation of fairness in settings with term-based representations of groups in documents in a ranked list.
Self-seeding and Multi-intent Self-instructing LLMs for Generating Intent-aware Information-Seeking dialogs
Feb 18, 2024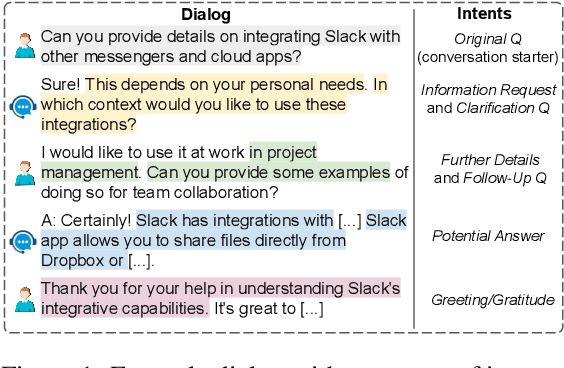
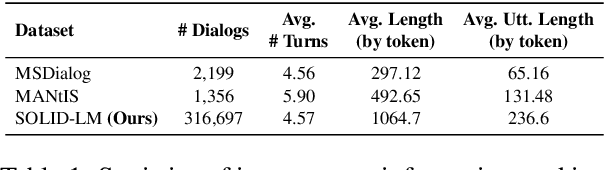

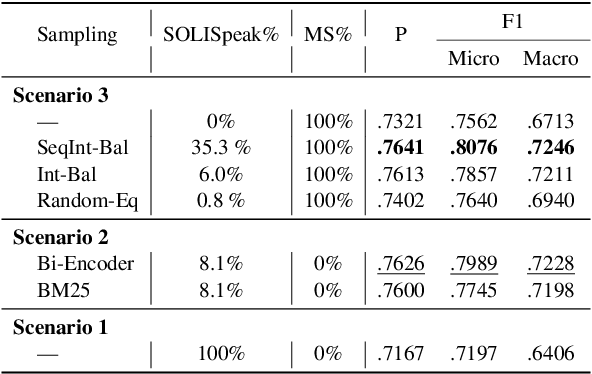
Identifying user intents in information-seeking dialogs is crucial for a system to meet user's information needs. Intent prediction (IP) is challenging and demands sufficient dialogs with human-labeled intents for training. However, manually annotating intents is resource-intensive. While large language models (LLMs) have been shown to be effective in generating synthetic data, there is no study on using LLMs to generate intent-aware information-seeking dialogs. In this paper, we focus on leveraging LLMs for zero-shot generation of large-scale, open-domain, and intent-aware information-seeking dialogs. We propose SOLID, which has novel self-seeding and multi-intent self-instructing schemes. The former improves the generation quality by using the LLM's own knowledge scope to initiate dialog generation; the latter prompts the LLM to generate utterances sequentially, and mitigates the need for manual prompt design by asking the LLM to autonomously adapt its prompt instruction when generating complex multi-intent utterances. Furthermore, we propose SOLID-RL, which is further trained to generate a dialog in one step on the data generated by SOLID. We propose a length-based quality estimation mechanism to assign varying weights to SOLID-generated dialogs based on their quality during the training process of SOLID-RL. We use SOLID and SOLID-RL to generate more than 300k intent-aware dialogs, surpassing the size of existing datasets. Experiments show that IP methods trained on dialogs generated by SOLID and SOLID-RL achieve better IP quality than ones trained on human-generated dialogs.
Answer Retrieval in Legal Community Question Answering
Jan 09, 2024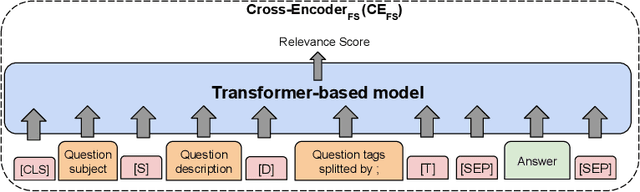
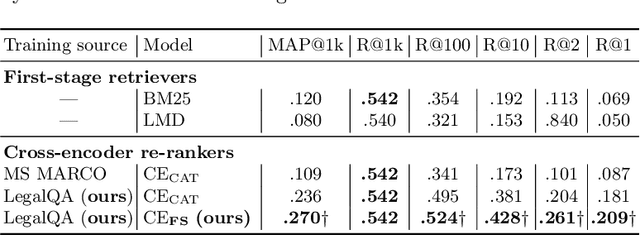

The task of answer retrieval in the legal domain aims to help users to seek relevant legal advice from massive amounts of professional responses. Two main challenges hinder applying existing answer retrieval approaches in other domains to the legal domain: (1) a huge knowledge gap between lawyers and non-professionals; and (2) a mix of informal and formal content on legal QA websites. To tackle these challenges, we propose CE_FS, a novel cross-encoder (CE) re-ranker based on the fine-grained structured inputs. CE_FS uses additional structured information in the CQA data to improve the effectiveness of cross-encoder re-rankers. Furthermore, we propose LegalQA: a real-world benchmark dataset for evaluating answer retrieval in the legal domain. Experiments conducted on LegalQA show that our proposed method significantly outperforms strong cross-encoder re-rankers fine-tuned on MS MARCO. Our novel finding is that adding the question tags of each question besides the question description and title into the input of cross-encoder re-rankers structurally boosts the rankers' effectiveness. While we study our proposed method in the legal domain, we believe that our method can be applied in similar applications in other domains.