 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Taxonomy of Negation for NLP and Neural Retrievers
Jul 30, 2025Understanding and solving complex reasoning tasks is vital for addressing the information needs of a user. Although dense neural models learn contextualised embeddings, they still underperform on queries containing negation. To understand this phenomenon, we study negation in both traditional neural information retrieval and LLM-based models. We (1) introduce a taxonomy of negation that derives from philosophical, linguistic, and logical definitions; (2) generate two benchmark datasets that can be used to evaluate the performance of neural information retrieval models and to fine-tune models for a more robust performance on negation; and (3) propose a logic-based classification mechanism that can be used to analyze the performance of retrieval models on existing datasets. Our taxonomy produces a balanced data distribution over negation types, providing a better training setup that leads to faster convergence on the NevIR dataset. Moreover, we propose a classification schema that reveals the coverage of negation types in existing datasets, offering insights into the factors that might affect the generalization of fine-tuned models on negation.
Interpreting Multilingual and Document-Length Sensitive Relevance Computations in Neural Retrieval Models through Axiomatic Causal Interventions
May 04, 2025This reproducibility study analyzes and extends the paper "Axiomatic Causal Interventions for Reverse Engineering Relevance Computation in Neural Retrieval Models," which investigates how neural retrieval models encode task-relevant properties such as term frequency. We reproduce key experiments from the original paper, confirming that information on query terms is captured in the model encoding. We extend this work by applying activation patching to Spanish and Chinese datasets and by exploring whether document-length information is encoded in the model as well. Our results confirm that the designed activation patching method can isolate the behavior to specific components and tokens in neural retrieval models. Moreover, our findings indicate that the location of term frequency generalizes across languages and that in later layers, the information for sequence-level tasks is represented in the CLS token. The results highlight the need for further research into interpretability in information retrieval and reproducibility in machine learning research. Our code is available at https://github.com/OliverSavolainen/axiomatic-ir-reproduce.
Beyond Reproducibility: Advancing Zero-shot LLM Reranking Efficiency with Setwise Insertion
Apr 09, 2025This study presents a comprehensive reproducibility and extension analysis of the Setwise prompting methodology for zero-shot ranking with Large Language Models (LLMs), as proposed by Zhuang et al. We evaluate its effectiveness and efficiency compared to traditional Pointwise, Pairwise, and Listwise approaches in document ranking tasks. Our reproduction confirms the findings of Zhuang et al., highlighting the trade-offs between computational efficiency and ranking effectiveness in Setwise methods. Building on these insights, we introduce Setwise Insertion, a novel approach that leverages the initial document ranking as prior knowledge, reducing unnecessary comparisons and uncertainty by focusing on candidates more likely to improve the ranking results. Experimental results across multiple LLM architectures (Flan-T5, Vicuna, and Llama) show that Setwise Insertion yields a 31% reduction in query time, a 23% reduction in model inferences, and a slight improvement in reranking effectiveness compared to the original Setwise method. These findings highlight the practical advantage of incorporating prior ranking knowledge into Setwise prompting for efficient and accurate zero-shot document reranking.
Leveraging Graph Structures to Detect Hallucinations in Large Language Models
Jul 05, 2024



Large language models are extensively applied across a wide range of tasks, such as customer support, content creation, educational tutoring, and providing financial guidance. However, a well-known drawback is their predisposition to generate hallucinations. This damages the trustworthiness of the information these models provide, impacting decision-making and user confidence. We propose a method to detect hallucinations by looking at the structure of the latent space and finding associations within hallucinated and non-hallucinated generations. We create a graph structure that connects generations that lie closely in the embedding space. Moreover, we employ a Graph Attention Network which utilizes message passing to aggregate information from neighboring nodes and assigns varying degrees of importance to each neighbor based on their relevance. Our findings show that 1) there exists a structure in the latent space that differentiates between hallucinated and non-hallucinated generations, 2) Graph Attention Networks can learn this structure and generalize it to unseen generations, and 3) the robustness of our method is enhanced when incorporating contrastive learning. When evaluated against evidence-based benchmarks, our model performs similarly without access to search-based methods.
Efficient data selection employing Semantic Similarity-based Graph Structures for model training
Feb 22, 2024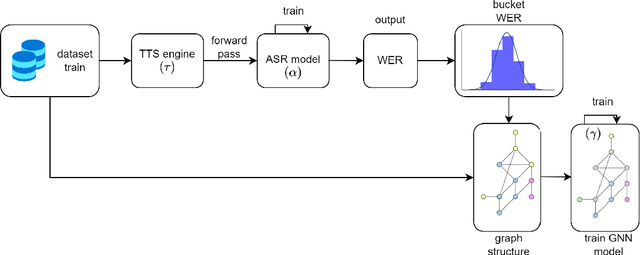
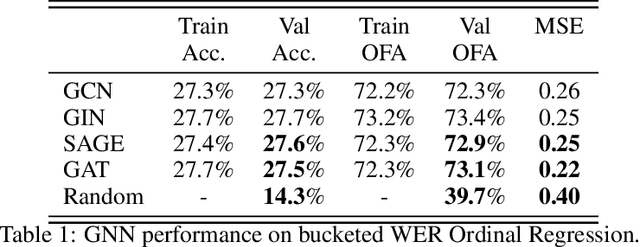
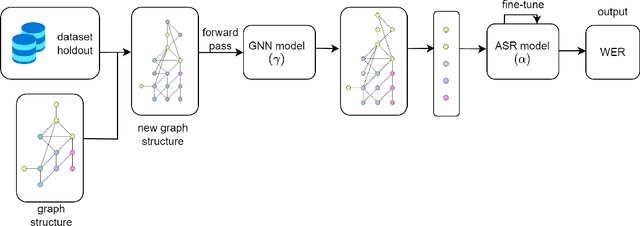
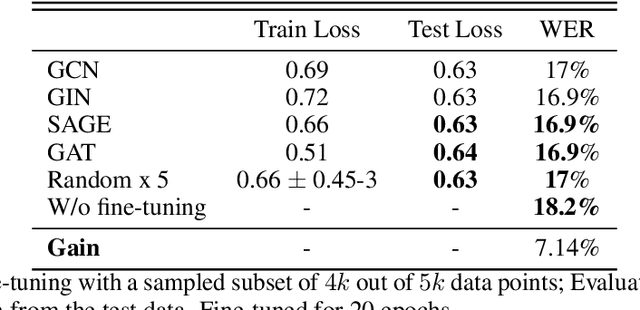
Recent developments in natural language processing (NLP) have highlighted the need for substantial amounts of data for models to capture textual information accurately. This raises concerns regarding the computational resources and time required for training such models. This paper introduces Semantics for data SAliency in Model performance Estimation (SeSaME). It is an efficient data sampling mechanism solely based on textual information without passing the data through a compute-heavy model or other intensive pre-processing transformations. The application of this approach is demonstrated in the use case of low-resource automated speech recognition (ASR) models, which excessively rely on text-to-speech (TTS) calls when using augmented data. SeSaME learns to categorize new incoming data points into speech recognition difficulty buckets by employing semantic similarity-based graph structures and discrete ASR information from homophilous neighbourhoods through message passing. The results indicate reliable projections of ASR performance, with a 93% accuracy increase when using the proposed method compared to random predictions, bringing non-trivial information on the impact of textual representations in speech models. Furthermore, a series of experiments show both the benefits and challenges of using the ASR information on incoming data to fine-tune the model. We report a 7% drop in validation loss compared to random sampling, 7% WER drop with non-local aggregation when evaluating against a highly difficult dataset, and 1.8% WER drop with local aggregation and high semantic similarity between datasets.
Self-seeding and Multi-intent Self-instructing LLMs for Generating Intent-aware Information-Seeking dialogs
Feb 18, 2024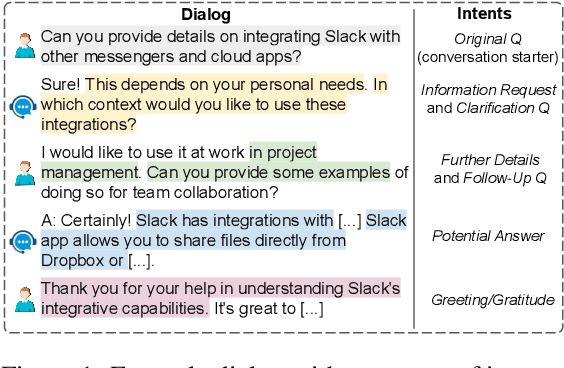
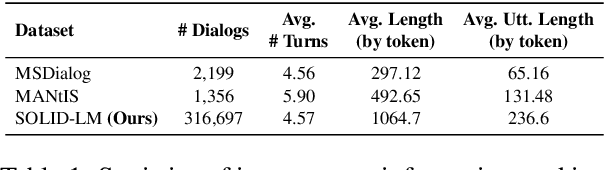

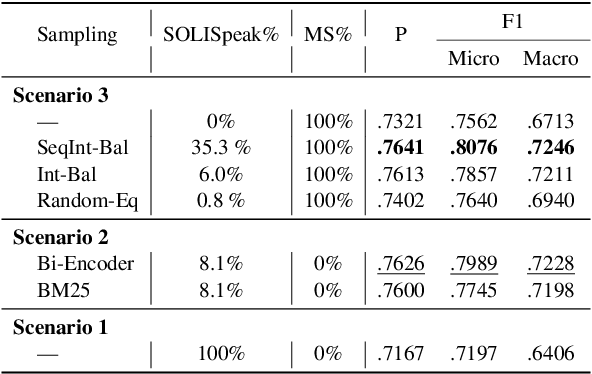
Identifying user intents in information-seeking dialogs is crucial for a system to meet user's information needs. Intent prediction (IP) is challenging and demands sufficient dialogs with human-labeled intents for training. However, manually annotating intents is resource-intensive. While large language models (LLMs) have been shown to be effective in generating synthetic data, there is no study on using LLMs to generate intent-aware information-seeking dialogs. In this paper, we focus on leveraging LLMs for zero-shot generation of large-scale, open-domain, and intent-aware information-seeking dialogs. We propose SOLID, which has novel self-seeding and multi-intent self-instructing schemes. The former improves the generation quality by using the LLM's own knowledge scope to initiate dialog generation; the latter prompts the LLM to generate utterances sequentially, and mitigates the need for manual prompt design by asking the LLM to autonomously adapt its prompt instruction when generating complex multi-intent utterances. Furthermore, we propose SOLID-RL, which is further trained to generate a dialog in one step on the data generated by SOLID. We propose a length-based quality estimation mechanism to assign varying weights to SOLID-generated dialogs based on their quality during the training process of SOLID-RL. We use SOLID and SOLID-RL to generate more than 300k intent-aware dialogs, surpassing the size of existing datasets. Experiments show that IP methods trained on dialogs generated by SOLID and SOLID-RL achieve better IP quality than ones trained on human-generated dialogs.