 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Attribution Bias in Retrieval-Augmented Large Language Models
Oct 16, 2024
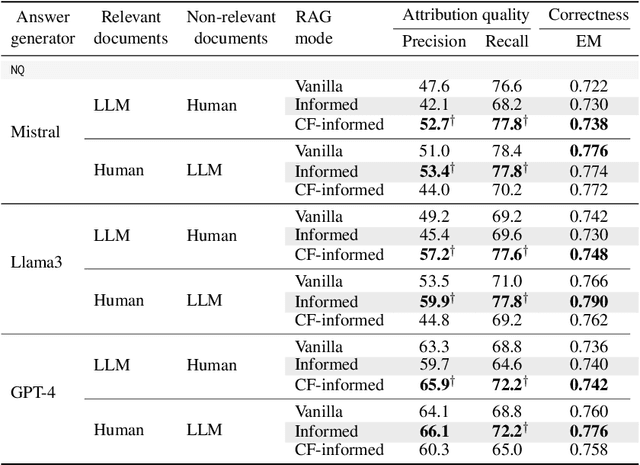
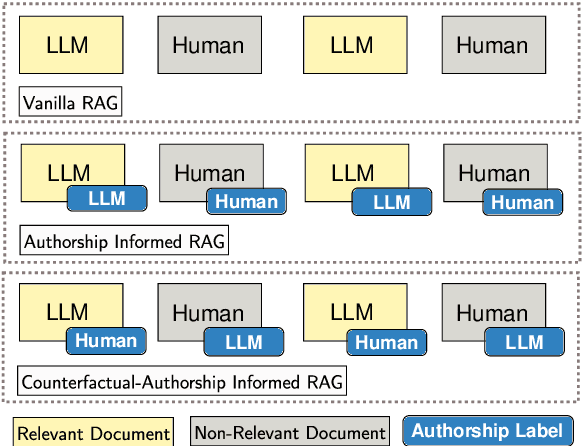

Attributing answers to source documents is an approach used to enhance the verifiability of a model's output in retrieval augmented generation (RAG). Prior work has mainly focused on improving and evaluating the attribution quality of large language models (LLMs) in RAG, but this may come at the expense of inducing biases in the attribution of answers. We define and examine two aspects in the evaluation of LLMs in RAG pipelines, namely attribution sensitivity and bias with respect to authorship information. We explicitly inform an LLM about the authors of source documents, instruct it to attribute its answers, and analyze (i) how sensitive the LLM's output is to the author of source documents, and (ii) whether the LLM exhibits a bias towards human-written or AI-generated source documents. We design an experimental setup in which we use counterfactual evaluation to study three LLMs in terms of their attribution sensitivity and bias in RAG pipelines. Our results show that adding authorship information to source documents can significantly change the attribution quality of LLMs by 3% to 18%. Moreover, we show that LLMs can have an attribution bias towards explicit human authorship, which can serve as a competing hypothesis for findings of prior work that shows that LLM-generated content may be preferred over human-written contents. Our findings indicate that metadata of source documents can influence LLMs' trust, and how they attribute their answers. Furthermore, our research highlights attribution bias and sensitivity as a novel aspect of brittleness in LLMs.
CAUSE: Counterfactual Assessment of User Satisfaction Estimation in Task-Oriented Dialogue Systems
Mar 27, 2024
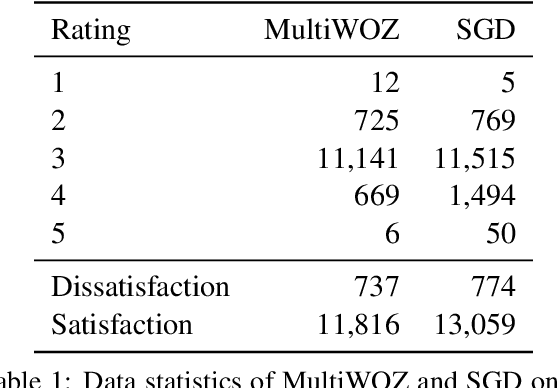
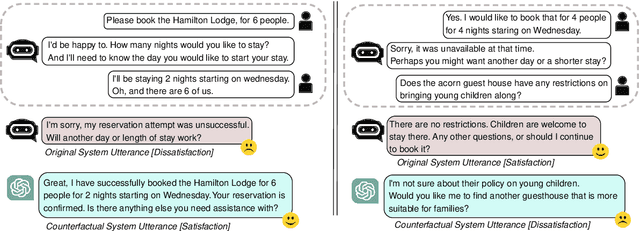
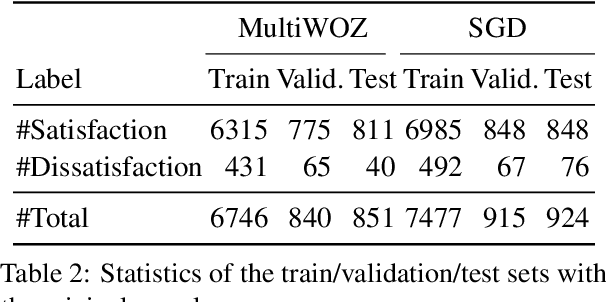
An important unexplored aspect in previous work on user satisfaction estimation for Task-Oriented Dialogue (TOD) systems is their evaluation in terms of robustness for the identification of user dissatisfaction: current benchmarks for user satisfaction estimation in TOD systems are highly skewed towards dialogues for which the user is satisfied. The effect of having a more balanced set of satisfaction labels on performance is unknown. However, balancing the data with more dissatisfactory dialogue samples requires further data collection and human annotation, which is costly and time-consuming. In this work, we leverage large language models (LLMs) and unlock their ability to generate satisfaction-aware counterfactual dialogues to augment the set of original dialogues of a test collection. We gather human annotations to ensure the reliability of the generated samples. We evaluate two open-source LLMs as user satisfaction estimators on our augmented collection against state-of-the-art fine-tuned models. Our experiments show that when used as few-shot user satisfaction estimators, open-source LLMs show higher robustness to the increase in the number of dissatisfaction labels in the test collection than the fine-tuned state-of-the-art models. Our results shed light on the need for data augmentation approaches for user satisfaction estimation in TOD systems. We release our aligned counterfactual dialogues, which are curated by human annotation, to facilitate further research on this topic.
Measuring Bias in a Ranked List using Term-based Representations
Mar 09, 2024In most recent studies, gender bias in document ranking is evaluated with the NFaiRR metric, which measures bias in a ranked list based on an aggregation over the unbiasedness scores of each ranked document. This perspective in measuring the bias of a ranked list has a key limitation: individual documents of a ranked list might be biased while the ranked list as a whole balances the groups' representations. To address this issue, we propose a novel metric called TExFAIR (term exposure-based fairness), which is based on two new extensions to a generic fairness evaluation framework, attention-weighted ranking fairness (AWRF). TExFAIR assesses fairness based on the term-based representation of groups in a ranked list: (i) an explicit definition of associating documents to groups based on probabilistic term-level associations, and (ii) a rank-biased discounting factor (RBDF) for counting non-representative documents towards the measurement of the fairness of a ranked list. We assess TExFAIR on the task of measuring gender bias in passage ranking, and study the relationship between TExFAIR and NFaiRR. Our experiments show that there is no strong correlation between TExFAIR and NFaiRR, which indicates that TExFAIR measures a different dimension of fairness than NFaiRR. With TExFAIR, we extend the AWRF framework to allow for the evaluation of fairness in settings with term-based representations of groups in documents in a ranked list.
Self-seeding and Multi-intent Self-instructing LLMs for Generating Intent-aware Information-Seeking dialogs
Feb 18, 2024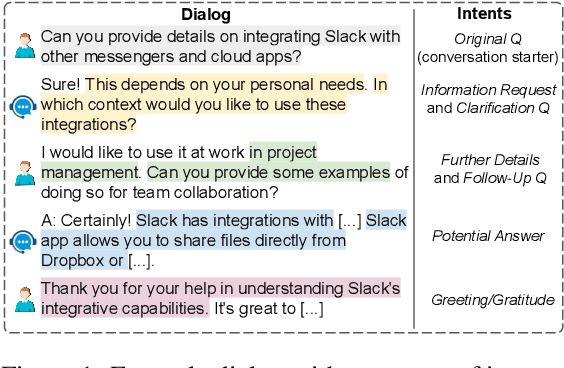
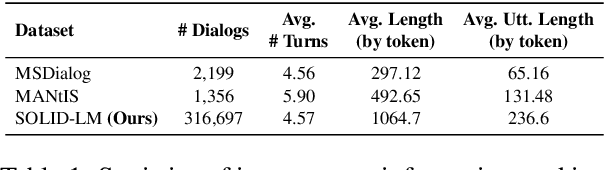

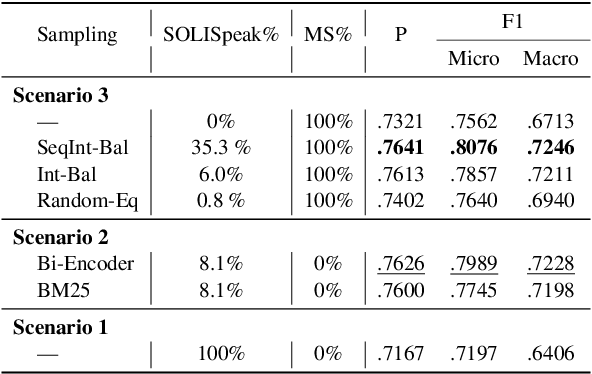
Identifying user intents in information-seeking dialogs is crucial for a system to meet user's information needs. Intent prediction (IP) is challenging and demands sufficient dialogs with human-labeled intents for training. However, manually annotating intents is resource-intensive. While large language models (LLMs) have been shown to be effective in generating synthetic data, there is no study on using LLMs to generate intent-aware information-seeking dialogs. In this paper, we focus on leveraging LLMs for zero-shot generation of large-scale, open-domain, and intent-aware information-seeking dialogs. We propose SOLID, which has novel self-seeding and multi-intent self-instructing schemes. The former improves the generation quality by using the LLM's own knowledge scope to initiate dialog generation; the latter prompts the LLM to generate utterances sequentially, and mitigates the need for manual prompt design by asking the LLM to autonomously adapt its prompt instruction when generating complex multi-intent utterances. Furthermore, we propose SOLID-RL, which is further trained to generate a dialog in one step on the data generated by SOLID. We propose a length-based quality estimation mechanism to assign varying weights to SOLID-generated dialogs based on their quality during the training process of SOLID-RL. We use SOLID and SOLID-RL to generate more than 300k intent-aware dialogs, surpassing the size of existing datasets. Experiments show that IP methods trained on dialogs generated by SOLID and SOLID-RL achieve better IP quality than ones trained on human-generated dialogs.
Retrieval for Extremely Long Queries and Documents with RPRS: a Highly Efficient and Effective Transformer-based Re-Ranker
Mar 02, 2023



Retrieval with extremely long queries and documents is a well-known and challenging task in information retrieval and is commonly known as Query-by-Document (QBD) retrieval. Specifically designed Transformer models that can handle long input sequences have not shown high effectiveness in QBD tasks in previous work. We propose a Re-Ranker based on the novel Proportional Relevance Score (RPRS) to compute the relevance score between a query and the top-k candidate documents. Our extensive evaluation shows RPRS obtains significantly better results than the state-of-the-art models on five different datasets. Furthermore, RPRS is highly efficient since all documents can be pre-processed, embedded, and indexed before query time which gives our re-ranker the advantage of having a complexity of O(N) where N is the total number of sentences in the query and candidate documents. Furthermore, our method solves the problem of the low-resource training in QBD retrieval tasks as it does not need large amounts of training data, and has only three parameters with a limited range that can be optimized with a grid search even if a small amount of labeled data is available. Our detailed analysis shows that RPRS benefits from covering the full length of candidate documents and queries.
Injecting the BM25 Score as Text Improves BERT-Based Re-rankers
Jan 23, 2023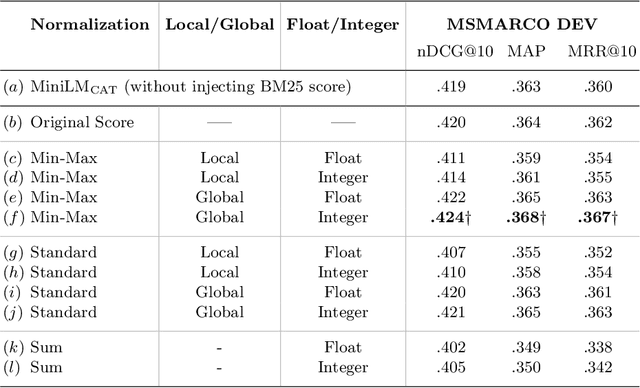
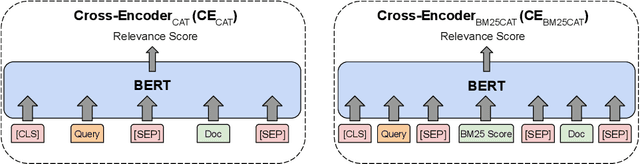
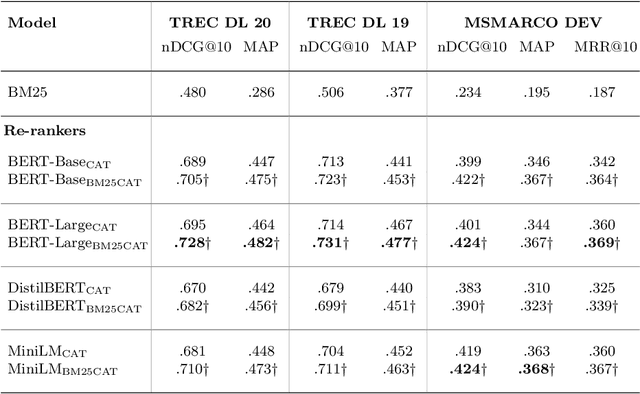
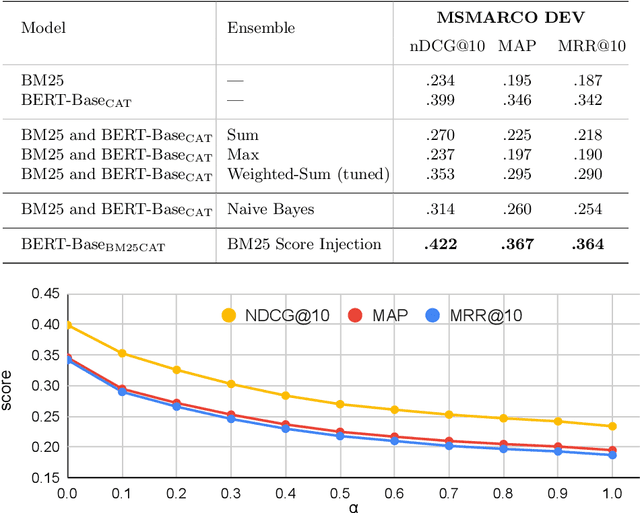
In this paper we propose a novel approach for combining first-stage lexical retrieval models and Transformer-based re-rankers: we inject the relevance score of the lexical model as a token in the middle of the input of the cross-encoder re-ranker. It was shown in prior work that interpolation between the relevance score of lexical and BERT-based re-rankers may not consistently result in higher effectiveness. Our idea is motivated by the finding that BERT models can capture numeric information. We compare several representations of the BM25 score and inject them as text in the input of four different cross-encoders. We additionally analyze the effect for different query types, and investigate the effectiveness of our method for capturing exact matching relevance. Evaluation on the MSMARCO Passage collection and the TREC DL collections shows that the proposed method significantly improves over all cross-encoder re-rankers as well as the common interpolation methods. We show that the improvement is consistent for all query types. We also find an improvement in exact matching capabilities over both BM25 and the cross-encoders. Our findings indicate that cross-encoder re-rankers can efficiently be improved without additional computational burden and extra steps in the pipeline by explicitly adding the output of the first-stage ranker to the model input, and this effect is robust for different models and query types.
On the Interpolation of Contextualized Term-based Ranking with BM25 for Query-by-Example Retrieval
Oct 11, 2022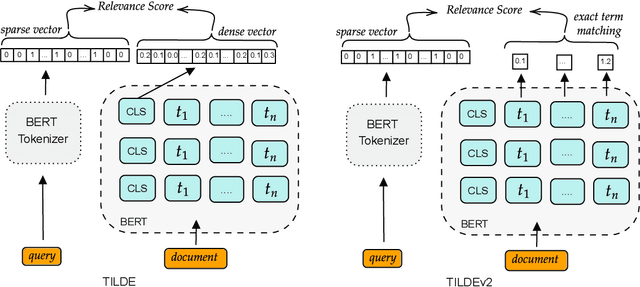
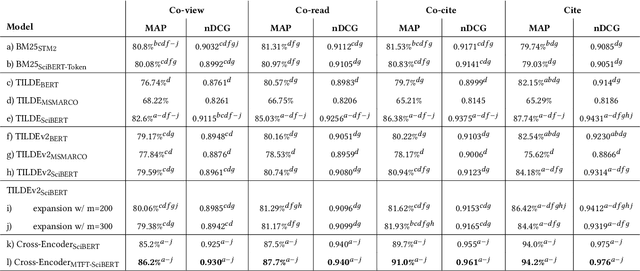
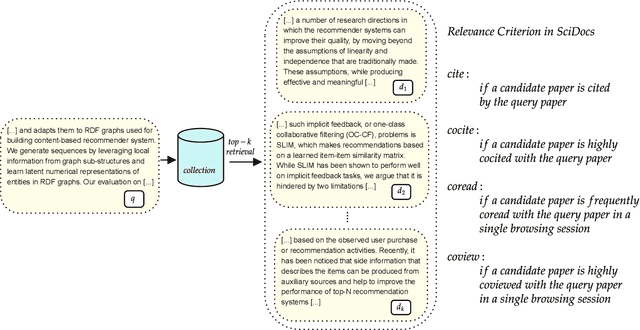
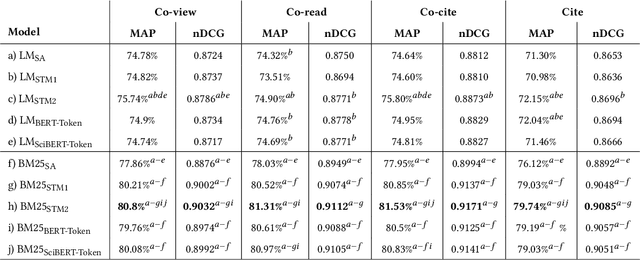
Term-based ranking with pre-trained transformer-based language models has recently gained attention as they bring the contextualization power of transformer models into the highly efficient term-based retrieval. In this work, we examine the generalizability of two of these deep contextualized term-based models in the context of query-by-example (QBE) retrieval in which a seed document acts as the query to find relevant documents. In this setting -- where queries are much longer than common keyword queries -- BERT inference at query time is problematic as it involves quadratic complexity. We investigate TILDE and TILDEv2, both of which leverage BERT tokenizer as their query encoder. With this approach, there is no need for BERT inference at query time, and also the query can be of any length. Our extensive evaluation on the four QBE tasks of SciDocs benchmark shows that in a query-by-example retrieval setting TILDE and TILDEv2 are still less effective than a cross-encoder BERT ranker. However, we observe that BM25 could show a competitive ranking quality compared to TILDE and TILDEv2 which is in contrast to the findings about the relative performance of these three models on retrieval for short queries reported in prior work. This result raises the question about the use of contextualized term-based ranking models being beneficial in QBE setting. We follow-up on our findings by studying the score interpolation between the relevance score from TILDE (TILDEv2) and BM25. We conclude that these two contextualized term-based ranking models capture different relevance signals than BM25 and combining the different term-based rankers results in statistically significant improvements in QBE retrieval. Our work sheds light on the challenges of retrieval settings different from the common evaluation benchmarks.
Improving BERT-based Query-by-Document Retrieval with Multi-Task Optimization
Feb 01, 2022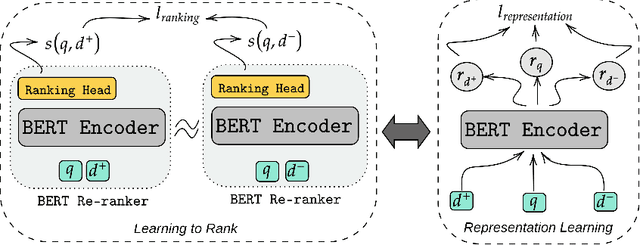
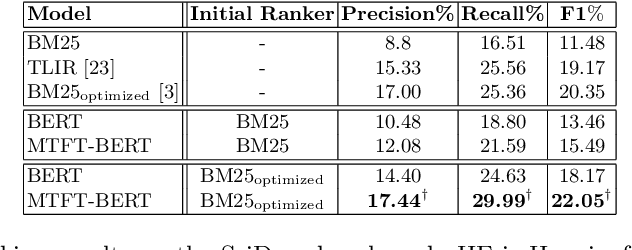
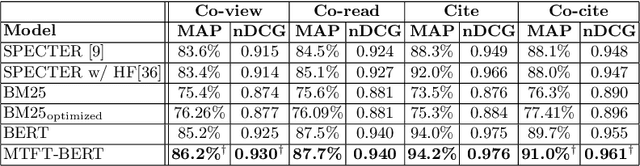
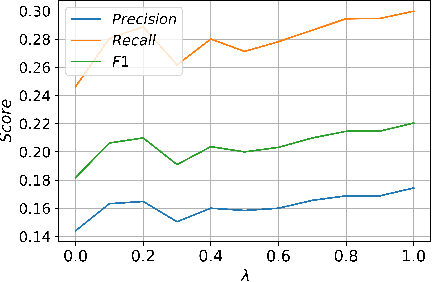
Query-by-document (QBD) retrieval is an Information Retrieval task in which a seed document acts as the query and the goal is to retrieve related documents -- it is particular common in professional search tasks. In this work we improve the retrieval effectiveness of the BERT re-ranker, proposing an extension to its fine-tuning step to better exploit the context of queries. To this end, we use an additional document-level representation learning objective besides the ranking objective when fine-tuning the BERT re-ranker. Our experiments on two QBD retrieval benchmarks show that the proposed multi-task optimization significantly improves the ranking effectiveness without changing the BERT re-ranker or using additional training samples. In future work, the generalizability of our approach to other retrieval tasks should be further investigated.
Neural Relation Prediction for Simple Question Answering over Knowledge Graph
Feb 18, 2020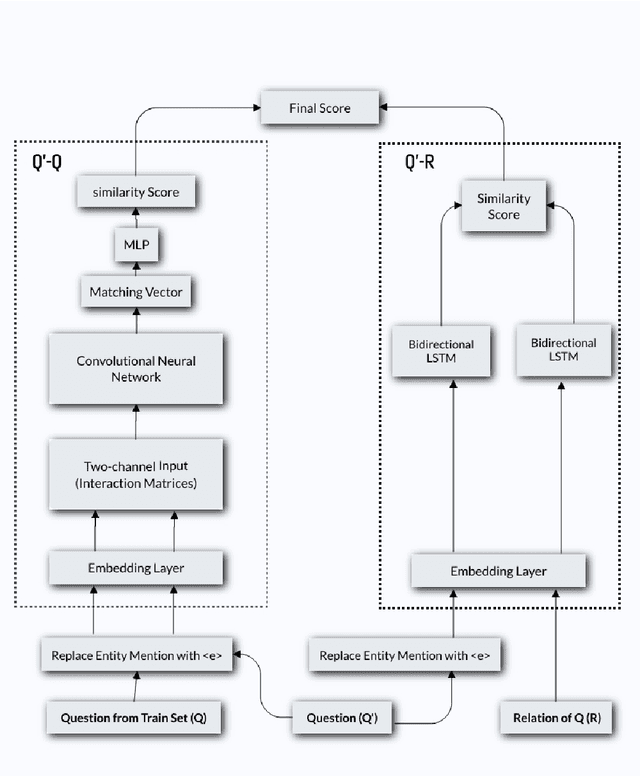
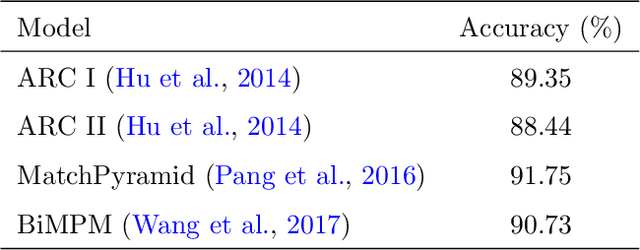


Relation extraction from simple questions aims to capture the relation of a factoid question with one underlying relation from a set of predefined ones ina knowledge base. Most recent methods take advantage of neural networks for matching a question with all relations in order to find the best relation that is expressed by that question. In this paper, we propose an instance-based method to find similar questions of a new question, in the sense of their relations, to predict its mentioned relation. The motivation roots in the fact that a relation can be expressed with different forms of question and these forms mostly share similar terms or concepts. Our experiments on the SimpleQuestions dataset show that the proposed model achieved better accuracy compared to the state-of-the-art relation extraction models.