 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Interpolation of Contextualized Term-based Ranking with BM25 for Query-by-Example Retrieval
Paper and Code
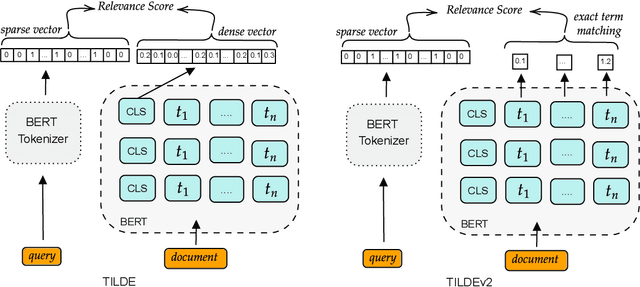
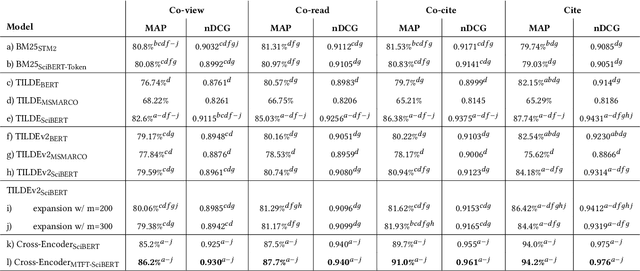
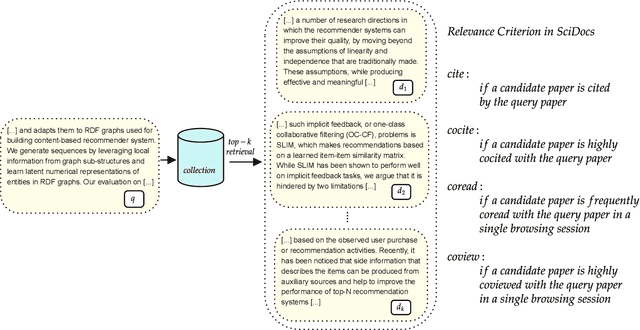
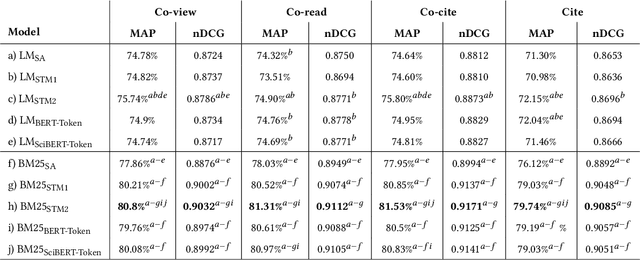
Term-based ranking with pre-trained transformer-based language models has recently gained attention as they bring the contextualization power of transformer models into the highly efficient term-based retrieval. In this work, we examine the generalizability of two of these deep contextualized term-based models in the context of query-by-example (QBE) retrieval in which a seed document acts as the query to find relevant documents. In this setting -- where queries are much longer than common keyword queries -- BERT inference at query time is problematic as it involves quadratic complexity. We investigate TILDE and TILDEv2, both of which leverage BERT tokenizer as their query encoder. With this approach, there is no need for BERT inference at query time, and also the query can be of any length. Our extensive evaluation on the four QBE tasks of SciDocs benchmark shows that in a query-by-example retrieval setting TILDE and TILDEv2 are still less effective than a cross-encoder BERT ranker. However, we observe that BM25 could show a competitive ranking quality compared to TILDE and TILDEv2 which is in contrast to the findings about the relative performance of these three models on retrieval for short queries reported in prior work. This result raises the question about the use of contextualized term-based ranking models being beneficial in QBE setting. We follow-up on our findings by studying the score interpolation between the relevance score from TILDE (TILDEv2) and BM25. We conclude that these two contextualized term-based ranking models capture different relevance signals than BM25 and combining the different term-based rankers results in statistically significant improvements in QBE retrieval. Our work sheds light on the challenges of retrieval settings different from the common evaluation benchmarks.