 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInjecting the BM25 Score as Text Improves BERT-Based Re-rankers
Paper and Code
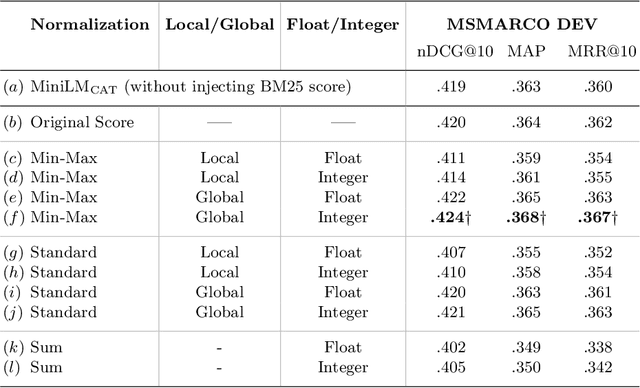
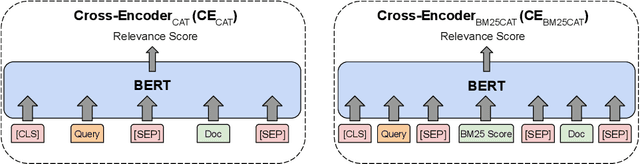
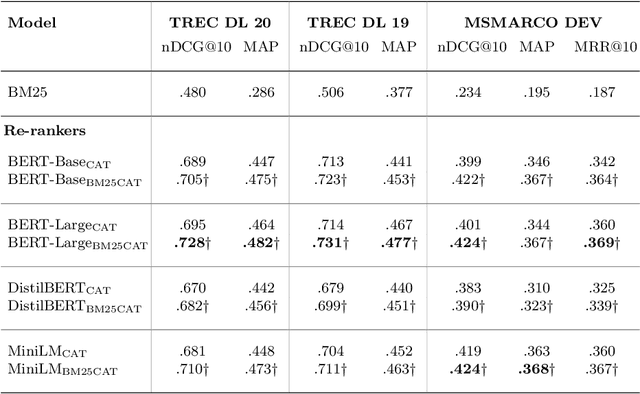
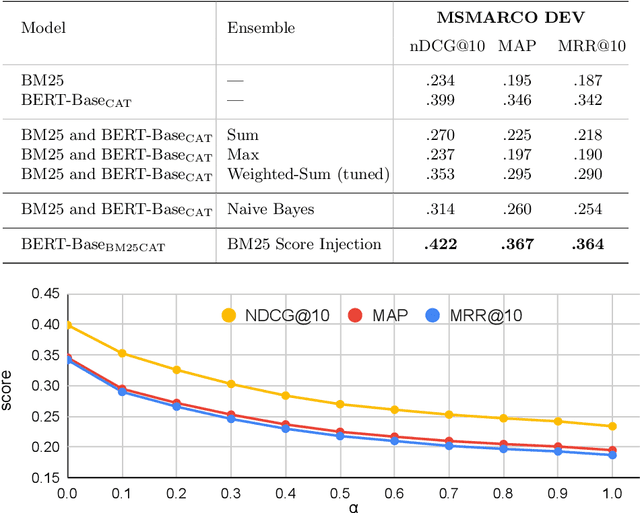
In this paper we propose a novel approach for combining first-stage lexical retrieval models and Transformer-based re-rankers: we inject the relevance score of the lexical model as a token in the middle of the input of the cross-encoder re-ranker. It was shown in prior work that interpolation between the relevance score of lexical and BERT-based re-rankers may not consistently result in higher effectiveness. Our idea is motivated by the finding that BERT models can capture numeric information. We compare several representations of the BM25 score and inject them as text in the input of four different cross-encoders. We additionally analyze the effect for different query types, and investigate the effectiveness of our method for capturing exact matching relevance. Evaluation on the MSMARCO Passage collection and the TREC DL collections shows that the proposed method significantly improves over all cross-encoder re-rankers as well as the common interpolation methods. We show that the improvement is consistent for all query types. We also find an improvement in exact matching capabilities over both BM25 and the cross-encoders. Our findings indicate that cross-encoder re-rankers can efficiently be improved without additional computational burden and extra steps in the pipeline by explicitly adding the output of the first-stage ranker to the model input, and this effect is robust for different models and query types.