 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Isomorphic Fields: A Transformer-based Algebraic Numerical Embedding
Jan 17, 2026Neural network models often face challenges when processing very small or very large numbers due to issues such as overflow, underflow, and unstable output variations. To mitigate these problems, we propose using embedding vectors for numbers instead of directly using their raw values. These embeddings aim to retain essential algebraic properties while preventing numerical instabilities. In this paper, we introduce, for the first time, a fixed-length number embedding vector that preserves algebraic operations, including addition, multiplication, and comparison, within the field of rational numbers. We propose a novel Neural Isomorphic Field, a neural abstraction of algebraic structures such as groups and fields. The elements of this neural field are embedding vectors that maintain algebraic structure during computations. Our experiments demonstrate that addition performs exceptionally well, achieving over 95 percent accuracy on key algebraic tests such as identity, closure, and associativity. In contrast, multiplication exhibits challenges, with accuracy ranging from 53 percent to 73 percent across various algebraic properties. These findings highlight the model's strengths in preserving algebraic properties under addition while identifying avenues for further improvement in handling multiplication.
MELAC: Massive Evaluation of Large Language Models with Alignment of Culture in Persian Language
Aug 01, 2025As large language models (LLMs) become increasingly embedded in our daily lives, evaluating their quality and reliability across diverse contexts has become essential. While comprehensive benchmarks exist for assessing LLM performance in English, there remains a significant gap in evaluation resources for other languages. Moreover, because most LLMs are trained primarily on data rooted in European and American cultures, they often lack familiarity with non-Western cultural contexts. To address this limitation, our study focuses on the Persian language and Iranian culture. We introduce 19 new evaluation datasets specifically designed to assess LLMs on topics such as Iranian law, Persian grammar, Persian idioms, and university entrance exams. Using these datasets, we benchmarked 41 prominent LLMs, aiming to bridge the existing cultural and linguistic evaluation gap in the field.
E2TP: Element to Tuple Prompting Improves Aspect Sentiment Tuple Prediction
May 10, 2024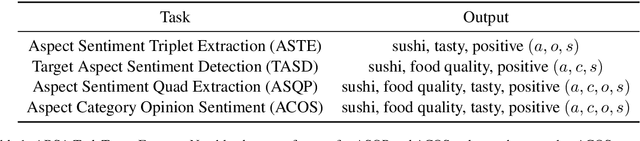


Generative approaches have significantly influenced Aspect-Based Sentiment Analysis (ABSA), garnering considerable attention. However, existing studies often predict target text components monolithically, neglecting the benefits of utilizing single elements for tuple prediction. In this paper, we introduce Element to Tuple Prompting (E2TP), employing a two-step architecture. The former step focuses on predicting single elements, while the latter step completes the process by mapping these predicted elements to their corresponding tuples. E2TP is inspired by human problem-solving, breaking down tasks into manageable parts, using the first step's output as a guide in the second step. Within this strategy, three types of paradigms, namely E2TP($diet$), E2TP($f_1$), and E2TP($f_2$), are designed to facilitate the training process. Beyond in-domain task-specific experiments, our paper addresses cross-domain scenarios, demonstrating the effectiveness and generalizability of the approach. By conducting a comprehensive analysis on various benchmarks, we show that E2TP achieves new state-of-the-art results in nearly all cases.
Multi Sentence Description of Complex Manipulation Action Videos
Nov 13, 2023



Automatic video description requires the generation of natural language statements about the actions, events, and objects in the video. An important human trait, when we describe a video, is that we are able to do this with variable levels of detail. Different from this, existing approaches for automatic video descriptions are mostly focused on single sentence generation at a fixed level of detail. Instead, here we address video description of manipulation actions where different levels of detail are required for being able to convey information about the hierarchical structure of these actions relevant also for modern approaches of robot learning. We propose one hybrid statistical and one end-to-end framework to address this problem. The hybrid method needs much less data for training, because it models statistically uncertainties within the video clips, while in the end-to-end method, which is more data-heavy, we are directly connecting the visual encoder to the language decoder without any intermediate (statistical) processing step. Both frameworks use LSTM stacks to allow for different levels of description granularity and videos can be described by simple single-sentences or complex multiple-sentence descriptions. In addition, quantitative results demonstrate that these methods produce more realistic descriptions than other competing approaches.
A Hierarchical Graph-based Approach for Recognition and Description Generation of Bimanual Actions in Videos
Oct 01, 2023



Nuanced understanding and the generation of detailed descriptive content for (bimanual) manipulation actions in videos is important for disciplines such as robotics, human-computer interaction, and video content analysis. This study describes a novel method, integrating graph based modeling with layered hierarchical attention mechanisms, resulting in higher precision and better comprehensiveness of video descriptions. To achieve this, we encode, first, the spatio-temporal inter dependencies between objects and actions with scene graphs and we combine this, in a second step, with a novel 3-level architecture creating a hierarchical attention mechanism using Graph Attention Networks (GATs). The 3-level GAT architecture allows recognizing local, but also global contextual elements. This way several descriptions with different semantic complexity can be generated in parallel for the same video clip, enhancing the discriminative accuracy of action recognition and action description. The performance of our approach is empirically tested using several 2D and 3D datasets. By comparing our method to the state of the art we consistently obtain better performance concerning accuracy, precision, and contextual relevance when evaluating action recognition as well as description generation. In a large set of ablation experiments we also assess the role of the different components of our model. With our multi-level approach the system obtains different semantic description depths, often observed in descriptions made by different people, too. Furthermore, better insight into bimanual hand-object interactions as achieved by our model may portend advancements in the field of robotics, enabling the emulation of intricate human actions with heightened precision.
X-CapsNet For Fake News Detection
Jul 23, 2023



News consumption has significantly increased with the growing popularity and use of web-based forums and social media. This sets the stage for misinforming and confusing people. To help reduce the impact of misinformation on users' potential health-related decisions and other intents, it is desired to have machine learning models to detect and combat fake news automatically. This paper proposes a novel transformer-based model using Capsule neural Networks(CapsNet) called X-CapsNet. This model includes a CapsNet with dynamic routing algorithm paralyzed with a size-based classifier for detecting short and long fake news statements. We use two size-based classifiers, a Deep Convolutional Neural Network (DCNN) for detecting long fake news statements and a Multi-Layer Perceptron (MLP) for detecting short news statements. To resolve the problem of representing short news statements, we use indirect features of news created by concatenating the vector of news speaker profiles and a vector of polarity, sentiment, and counting words of news statements. For evaluating the proposed architecture, we use the Covid-19 and the Liar datasets. The results in terms of the F1-score for the Covid-19 dataset and accuracy for the Liar dataset show that models perform better than the state-of-the-art baselines.
Explaining Recommendation System Using Counterfactual Textual Explanations
Mar 14, 2023Currently, there is a significant amount of research being conducted in the field of artificial intelligence to improve the explainability and interpretability of deep learning models. It is found that if end-users understand the reason for the production of some output, it is easier to trust the system. Recommender systems are one example of systems that great efforts have been conducted to make their output more explainable. One method for producing a more explainable output is using counterfactual reasoning, which involves altering minimal features to generate a counterfactual item that results in changing the output of the system. This process allows the identification of input features that have a significant impact on the desired output, leading to effective explanations. In this paper, we present a method for generating counterfactual explanations for both tabular and textual features. We evaluated the performance of our proposed method on three real-world datasets and demonstrated a +5\% improvement on finding effective features (based on model-based measures) compared to the baseline method.
A Semantic Modular Framework for Events Topic Modeling in Social Media
Jan 21, 2023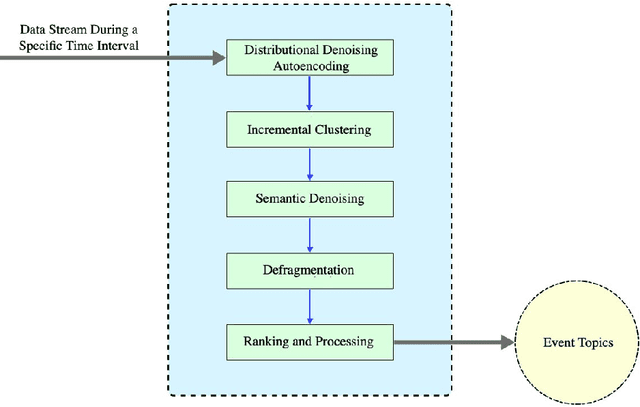

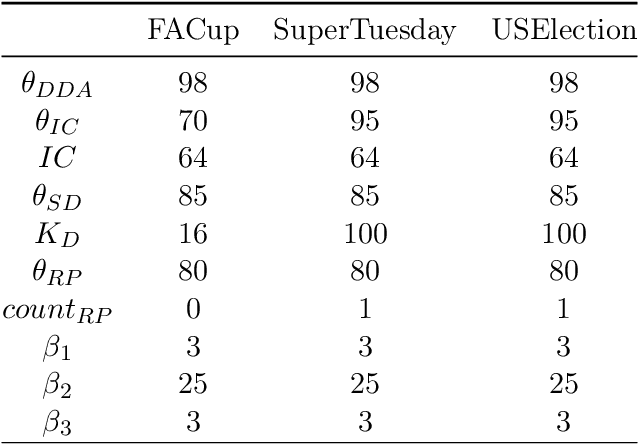
The advancement of social media contributes to the growing amount of content they share frequently. This framework provides a sophisticated place for people to report various real-life events. Detecting these events with the help of natural language processing has received researchers' attention, and various algorithms have been developed for this goal. In this paper, we propose a Semantic Modular Model (SMM) consisting of 5 different modules, namely Distributional Denoising Autoencoder, Incremental Clustering, Semantic Denoising, Defragmentation, and Ranking and Processing. The proposed model aims to (1) cluster various documents and ignore the documents that might not contribute to the identification of events, (2) identify more important and descriptive keywords. Compared to the state-of-the-art methods, the results show that the proposed model has a higher performance in identifying events with lower ranks and extracting keywords for more important events in three English Twitter datasets: FACup, SuperTuesday, and USElection. The proposed method outperformed the best reported results in the mean keyword-precision metric by 7.9\%.
PQuAD: A Persian Question Answering Dataset
Feb 13, 2022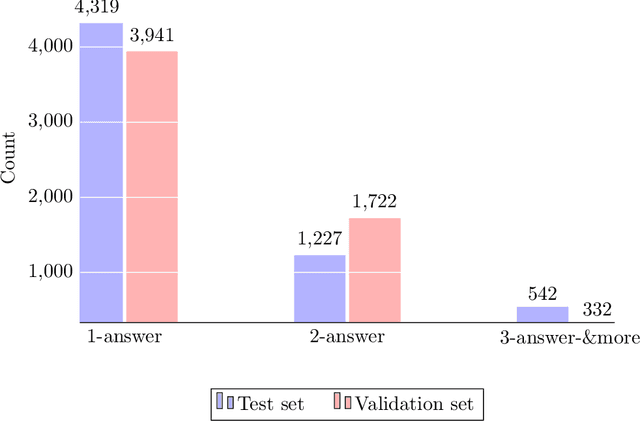
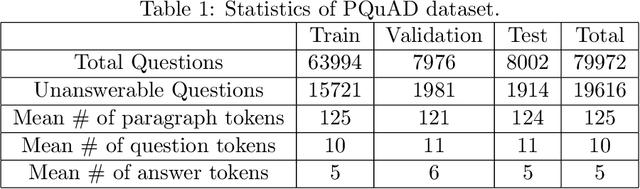
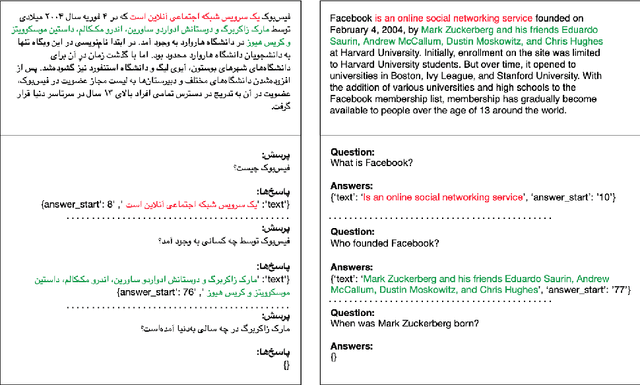
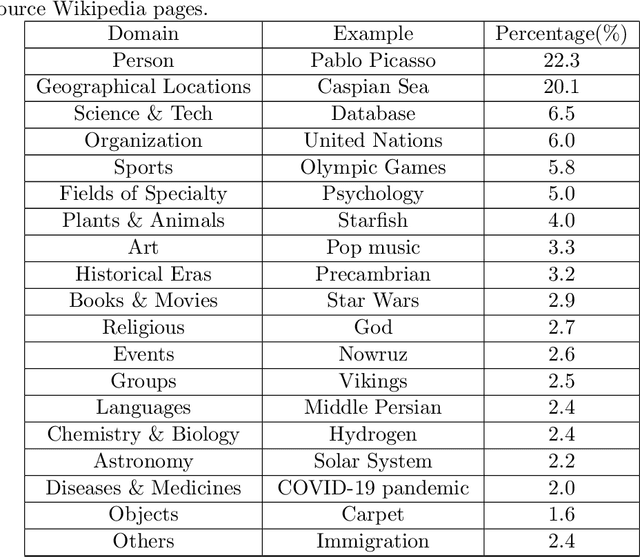
We present Persian Question Answering Dataset (PQuAD), a crowdsourced reading comprehension dataset on Persian Wikipedia articles. It includes 80,000 questions along with their answers, with 25% of the questions being adversarially unanswerable. We examine various properties of the dataset to show the diversity and the level of its difficulty as an MRC benchmark. By releasing this dataset, we aim to ease research on Persian reading comprehension and development of Persian question answering systems. Our experiments on different state-of-the-art pre-trained contextualized language models show 74.8% Exact Match (EM) and 87.6% F1-score that can be used as the baseline results for further research on Persian QA.
Neural Relation Prediction for Simple Question Answering over Knowledge Graph
Feb 18, 2020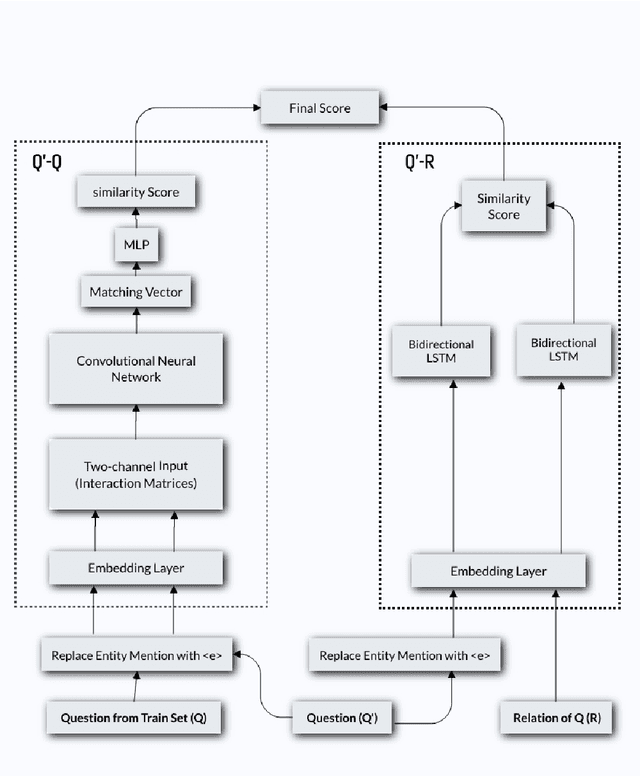
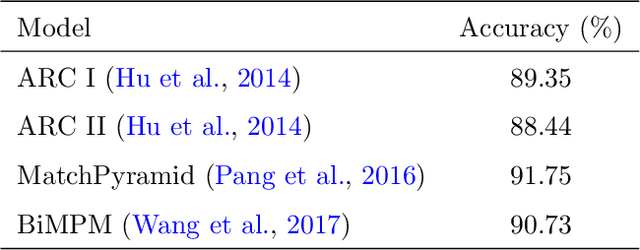


Relation extraction from simple questions aims to capture the relation of a factoid question with one underlying relation from a set of predefined ones ina knowledge base. Most recent methods take advantage of neural networks for matching a question with all relations in order to find the best relation that is expressed by that question. In this paper, we propose an instance-based method to find similar questions of a new question, in the sense of their relations, to predict its mentioned relation. The motivation roots in the fact that a relation can be expressed with different forms of question and these forms mostly share similar terms or concepts. Our experiments on the SimpleQuestions dataset show that the proposed model achieved better accuracy compared to the state-of-the-art relation extraction models.