 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Isomorphic Fields: A Transformer-based Algebraic Numerical Embedding
Jan 17, 2026Neural network models often face challenges when processing very small or very large numbers due to issues such as overflow, underflow, and unstable output variations. To mitigate these problems, we propose using embedding vectors for numbers instead of directly using their raw values. These embeddings aim to retain essential algebraic properties while preventing numerical instabilities. In this paper, we introduce, for the first time, a fixed-length number embedding vector that preserves algebraic operations, including addition, multiplication, and comparison, within the field of rational numbers. We propose a novel Neural Isomorphic Field, a neural abstraction of algebraic structures such as groups and fields. The elements of this neural field are embedding vectors that maintain algebraic structure during computations. Our experiments demonstrate that addition performs exceptionally well, achieving over 95 percent accuracy on key algebraic tests such as identity, closure, and associativity. In contrast, multiplication exhibits challenges, with accuracy ranging from 53 percent to 73 percent across various algebraic properties. These findings highlight the model's strengths in preserving algebraic properties under addition while identifying avenues for further improvement in handling multiplication.
Multi Sentence Description of Complex Manipulation Action Videos
Nov 13, 2023



Automatic video description requires the generation of natural language statements about the actions, events, and objects in the video. An important human trait, when we describe a video, is that we are able to do this with variable levels of detail. Different from this, existing approaches for automatic video descriptions are mostly focused on single sentence generation at a fixed level of detail. Instead, here we address video description of manipulation actions where different levels of detail are required for being able to convey information about the hierarchical structure of these actions relevant also for modern approaches of robot learning. We propose one hybrid statistical and one end-to-end framework to address this problem. The hybrid method needs much less data for training, because it models statistically uncertainties within the video clips, while in the end-to-end method, which is more data-heavy, we are directly connecting the visual encoder to the language decoder without any intermediate (statistical) processing step. Both frameworks use LSTM stacks to allow for different levels of description granularity and videos can be described by simple single-sentences or complex multiple-sentence descriptions. In addition, quantitative results demonstrate that these methods produce more realistic descriptions than other competing approaches.
A Hierarchical Graph-based Approach for Recognition and Description Generation of Bimanual Actions in Videos
Oct 01, 2023



Nuanced understanding and the generation of detailed descriptive content for (bimanual) manipulation actions in videos is important for disciplines such as robotics, human-computer interaction, and video content analysis. This study describes a novel method, integrating graph based modeling with layered hierarchical attention mechanisms, resulting in higher precision and better comprehensiveness of video descriptions. To achieve this, we encode, first, the spatio-temporal inter dependencies between objects and actions with scene graphs and we combine this, in a second step, with a novel 3-level architecture creating a hierarchical attention mechanism using Graph Attention Networks (GATs). The 3-level GAT architecture allows recognizing local, but also global contextual elements. This way several descriptions with different semantic complexity can be generated in parallel for the same video clip, enhancing the discriminative accuracy of action recognition and action description. The performance of our approach is empirically tested using several 2D and 3D datasets. By comparing our method to the state of the art we consistently obtain better performance concerning accuracy, precision, and contextual relevance when evaluating action recognition as well as description generation. In a large set of ablation experiments we also assess the role of the different components of our model. With our multi-level approach the system obtains different semantic description depths, often observed in descriptions made by different people, too. Furthermore, better insight into bimanual hand-object interactions as achieved by our model may portend advancements in the field of robotics, enabling the emulation of intricate human actions with heightened precision.
On Continuity of Robust and Accurate Classifiers
Sep 29, 2023



The reliability of a learning model is key to the successful deployment of machine learning in various applications. Creating a robust model, particularly one unaffected by adversarial attacks, requires a comprehensive understanding of the adversarial examples phenomenon. However, it is difficult to describe the phenomenon due to the complicated nature of the problems in machine learning. It has been shown that adversarial training can improve the robustness of the hypothesis. However, this improvement comes at the cost of decreased performance on natural samples. Hence, it has been suggested that robustness and accuracy of a hypothesis are at odds with each other. In this paper, we put forth the alternative proposal that it is the continuity of a hypothesis that is incompatible with its robustness and accuracy. In other words, a continuous function cannot effectively learn the optimal robust hypothesis. To this end, we will introduce a framework for a rigorous study of harmonic and holomorphic hypothesis in learning theory terms and provide empirical evidence that continuous hypotheses does not perform as well as discontinuous hypotheses in some common machine learning tasks. From a practical point of view, our results suggests that a robust and accurate learning rule would train different continuous hypotheses for different regions of the domain. From a theoretical perspective, our analysis explains the adversarial examples phenomenon as a conflict between the continuity of a sequence of functions and its uniform convergence to a discontinuous function.
Identity-preserving Editing of Multiple Facial Attributes by Learning Global Edit Directions and Local Adjustments
Sep 25, 2023



Semantic facial attribute editing using pre-trained Generative Adversarial Networks (GANs) has attracted a great deal of attention and effort from researchers in recent years. Due to the high quality of face images generated by StyleGANs, much work has focused on the StyleGANs' latent space and the proposed methods for facial image editing. Although these methods have achieved satisfying results for manipulating user-intended attributes, they have not fulfilled the goal of preserving the identity, which is an important challenge. We present ID-Style, a new architecture capable of addressing the problem of identity loss during attribute manipulation. The key components of ID-Style include Learnable Global Direction (LGD), which finds a shared and semi-sparse direction for each attribute, and an Instance-Aware Intensity Predictor (IAIP) network, which finetunes the global direction according to the input instance. Furthermore, we introduce two losses during training to enforce the LGD to find semi-sparse semantic directions, which along with the IAIP, preserve the identity of the input instance. Despite reducing the size of the network by roughly 95% as compared to similar state-of-the-art works, it outperforms baselines by 10% and 7% in Identity preserving metric (FRS) and average accuracy of manipulation (mACC), respectively.
X-CapsNet For Fake News Detection
Jul 23, 2023



News consumption has significantly increased with the growing popularity and use of web-based forums and social media. This sets the stage for misinforming and confusing people. To help reduce the impact of misinformation on users' potential health-related decisions and other intents, it is desired to have machine learning models to detect and combat fake news automatically. This paper proposes a novel transformer-based model using Capsule neural Networks(CapsNet) called X-CapsNet. This model includes a CapsNet with dynamic routing algorithm paralyzed with a size-based classifier for detecting short and long fake news statements. We use two size-based classifiers, a Deep Convolutional Neural Network (DCNN) for detecting long fake news statements and a Multi-Layer Perceptron (MLP) for detecting short news statements. To resolve the problem of representing short news statements, we use indirect features of news created by concatenating the vector of news speaker profiles and a vector of polarity, sentiment, and counting words of news statements. For evaluating the proposed architecture, we use the Covid-19 and the Liar datasets. The results in terms of the F1-score for the Covid-19 dataset and accuracy for the Liar dataset show that models perform better than the state-of-the-art baselines.
An Analytic Framework for Robust Training of Artificial Neural Networks
May 26, 2022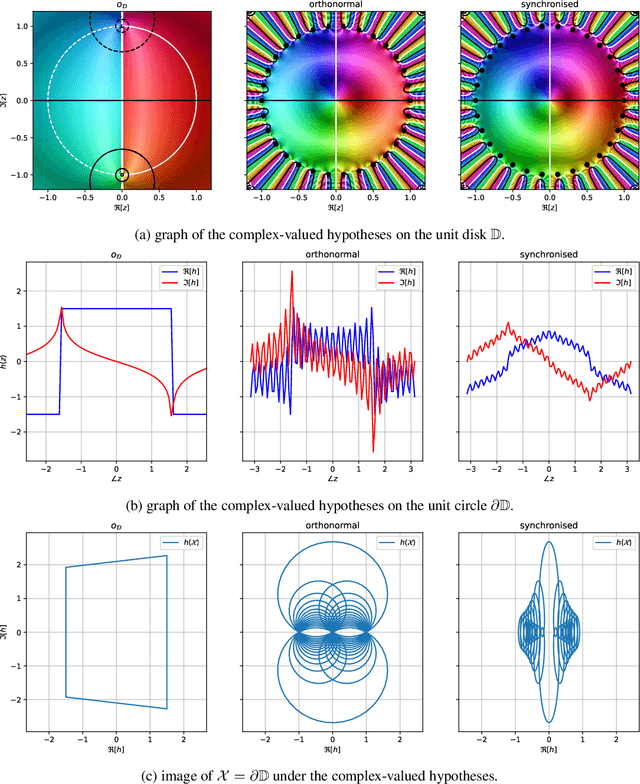
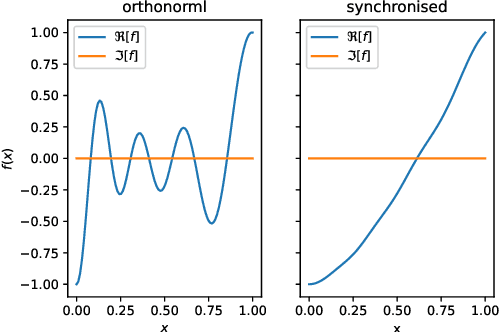
The reliability of a learning model is key to the successful deployment of machine learning in various industries. Creating a robust model, particularly one unaffected by adversarial attacks, requires a comprehensive understanding of the adversarial examples phenomenon. However, it is difficult to describe the phenomenon due to the complicated nature of the problems in machine learning. Consequently, many studies investigate the phenomenon by proposing a simplified model of how adversarial examples occur and validate it by predicting some aspect of the phenomenon. While these studies cover many different characteristics of the adversarial examples, they have not reached a holistic approach to the geometric and analytic modeling of the phenomenon. This paper propose a formal framework to study the phenomenon in learning theory and make use of complex analysis and holomorphicity to offer a robust learning rule for artificial neural networks. With the help of complex analysis, we can effortlessly move between geometric and analytic perspectives of the phenomenon and offer further insights on the phenomenon by revealing its connection with harmonic functions. Using our model, we can explain some of the most intriguing characteristics of adversarial examples, including transferability of adversarial examples, and pave the way for novel approaches to mitigate the effects of the phenomenon.
Using Decision Tree as Local Interpretable Model in Autoencoder-based LIME
Apr 07, 2022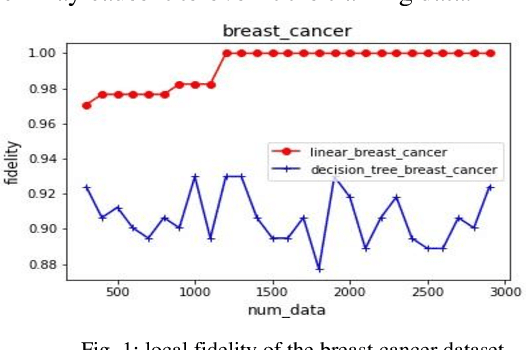
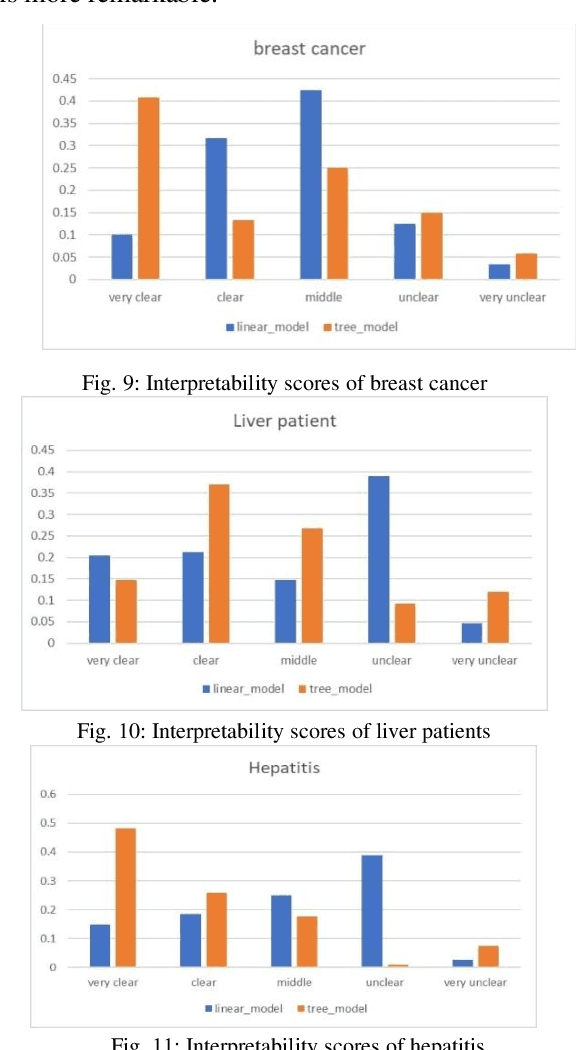
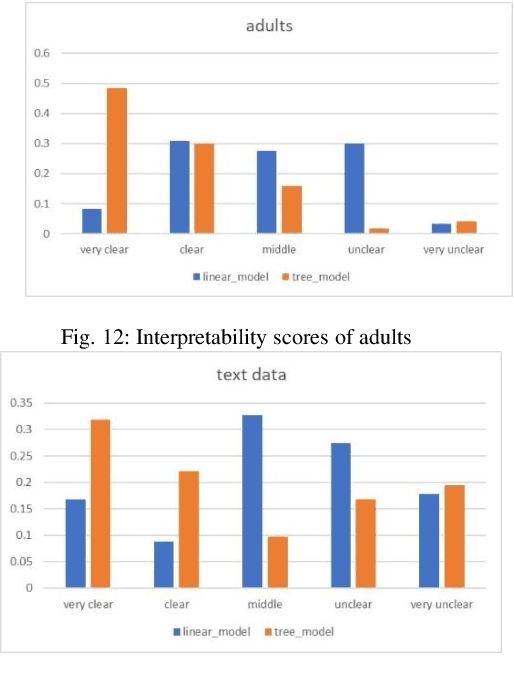
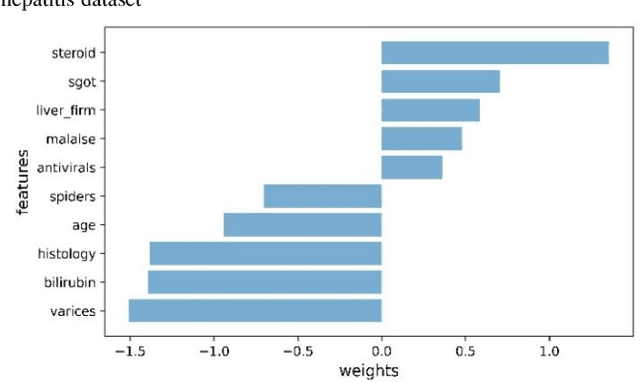
Nowadays, deep neural networks are being used in many domains because of their high accuracy results. However, they are considered as "black box", means that they are not explainable for humans. On the other hand, in some tasks such as medical, economic, and self-driving cars, users want the model to be interpretable to decide if they can trust these results or not. In this work, we present a modified version of an autoencoder-based approach for local interpretability called ALIME. The ALIME itself is inspired by a famous method called Local Interpretable Model-agnostic Explanations (LIME). LIME generates a single instance level explanation by generating new data around the instance and training a local linear interpretable model. ALIME uses an autoencoder to weigh the new data around the sample. Nevertheless, the ALIME uses a linear model as the interpretable model to be trained locally, just like the LIME. This work proposes a new approach, which uses a decision tree instead of the linear model, as the interpretable model. We evaluate the proposed model in case of stability, local fidelity, and interpretability on different datasets. Compared to ALIME, the experiments show significant results on stability and local fidelity and improved results on interpretability.
Towards Explaining Adversarial Examples Phenomenon in Artificial Neural Networks
Jul 22, 2021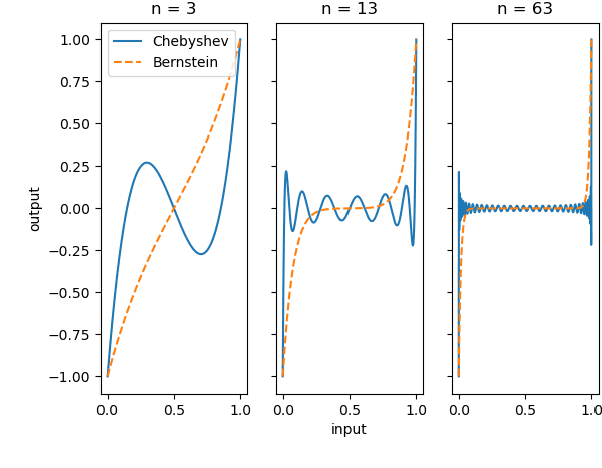
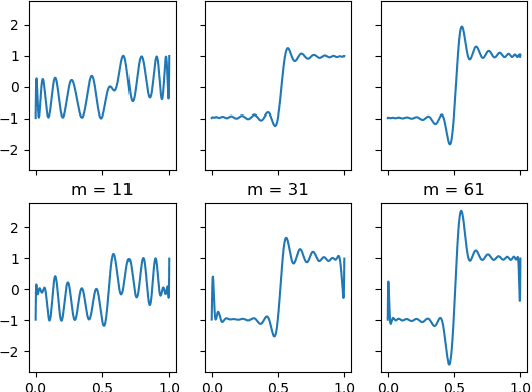
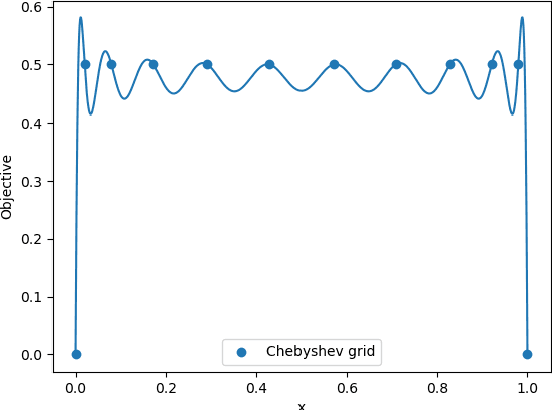
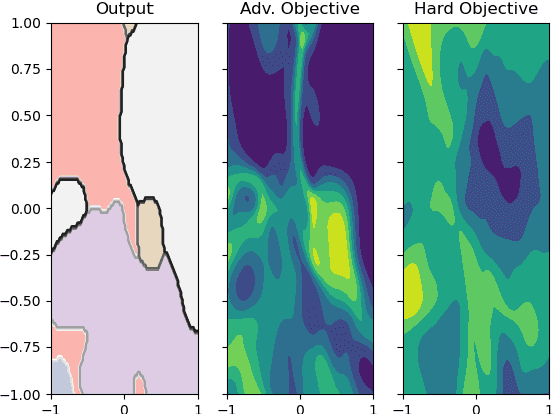
In this paper, we study the adversarial examples existence and adversarial training from the standpoint of convergence and provide evidence that pointwise convergence in ANNs can explain these observations. The main contribution of our proposal is that it relates the objective of the evasion attacks and adversarial training with concepts already defined in learning theory. Also, we extend and unify some of the other proposals in the literature and provide alternative explanations on the observations made in those proposals. Through different experiments, we demonstrate that the framework is valuable in the study of the phenomenon and is applicable to real-world problems.
Maximum Entropy Weighted Independent Set Pooling for Graph Neural Networks
Jul 03, 2021
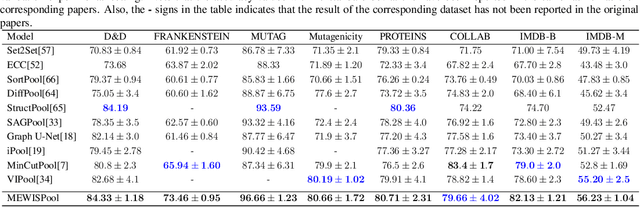
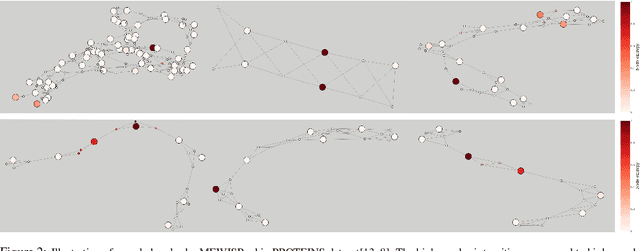
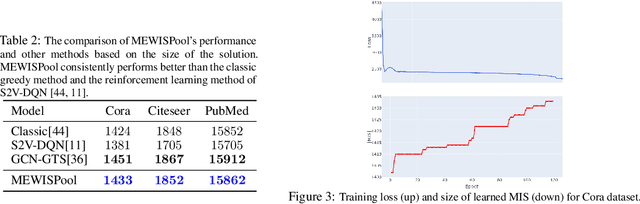
In this paper, we propose a novel pooling layer for graph neural networks based on maximizing the mutual information between the pooled graph and the input graph. Since the maximum mutual information is difficult to compute, we employ the Shannon capacity of a graph as an inductive bias to our pooling method. More precisely, we show that the input graph to the pooling layer can be viewed as a representation of a noisy communication channel. For such a channel, sending the symbols belonging to an independent set of the graph yields a reliable and error-free transmission of information. We show that reaching the maximum mutual information is equivalent to finding a maximum weight independent set of the graph where the weights convey entropy contents. Through this communication theoretic standpoint, we provide a distinct perspective for posing the problem of graph pooling as maximizing the information transmission rate across a noisy communication channel, implemented by a graph neural network. We evaluate our method, referred to as Maximum Entropy Weighted Independent Set Pooling (MEWISPool), on graph classification tasks and the combinatorial optimization problem of the maximum independent set. Empirical results demonstrate that our method achieves the state-of-the-art and competitive results on graph classification tasks and the maximum independent set problem in several benchmark datasets.