 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Sentence Description of Complex Manipulation Action Videos
Nov 13, 2023



Automatic video description requires the generation of natural language statements about the actions, events, and objects in the video. An important human trait, when we describe a video, is that we are able to do this with variable levels of detail. Different from this, existing approaches for automatic video descriptions are mostly focused on single sentence generation at a fixed level of detail. Instead, here we address video description of manipulation actions where different levels of detail are required for being able to convey information about the hierarchical structure of these actions relevant also for modern approaches of robot learning. We propose one hybrid statistical and one end-to-end framework to address this problem. The hybrid method needs much less data for training, because it models statistically uncertainties within the video clips, while in the end-to-end method, which is more data-heavy, we are directly connecting the visual encoder to the language decoder without any intermediate (statistical) processing step. Both frameworks use LSTM stacks to allow for different levels of description granularity and videos can be described by simple single-sentences or complex multiple-sentence descriptions. In addition, quantitative results demonstrate that these methods produce more realistic descriptions than other competing approaches.
A Hierarchical Graph-based Approach for Recognition and Description Generation of Bimanual Actions in Videos
Oct 01, 2023



Nuanced understanding and the generation of detailed descriptive content for (bimanual) manipulation actions in videos is important for disciplines such as robotics, human-computer interaction, and video content analysis. This study describes a novel method, integrating graph based modeling with layered hierarchical attention mechanisms, resulting in higher precision and better comprehensiveness of video descriptions. To achieve this, we encode, first, the spatio-temporal inter dependencies between objects and actions with scene graphs and we combine this, in a second step, with a novel 3-level architecture creating a hierarchical attention mechanism using Graph Attention Networks (GATs). The 3-level GAT architecture allows recognizing local, but also global contextual elements. This way several descriptions with different semantic complexity can be generated in parallel for the same video clip, enhancing the discriminative accuracy of action recognition and action description. The performance of our approach is empirically tested using several 2D and 3D datasets. By comparing our method to the state of the art we consistently obtain better performance concerning accuracy, precision, and contextual relevance when evaluating action recognition as well as description generation. In a large set of ablation experiments we also assess the role of the different components of our model. With our multi-level approach the system obtains different semantic description depths, often observed in descriptions made by different people, too. Furthermore, better insight into bimanual hand-object interactions as achieved by our model may portend advancements in the field of robotics, enabling the emulation of intricate human actions with heightened precision.
Simulated Mental Imagery for Robotic Task Planning
Nov 23, 2022



Traditional AI-planning methods for task planning in robotics require symbolically encoded domain description. While powerful in well-defined scenarios, setting this up requires substantial effort. Different from this, most everyday planning tasks are solved by humans intuitively, using mental imagery of the different planning steps. Here we suggest that the same approach can be used for robots, too, in cases which require only limited execution accuracy. In the current study, we propose a novel sub-symbolic method called Simulated Mental Imagery for Planning (SiMIP), which consists of several steps: perception, simulated action, success-checking and re-planning performed on 'imagined' images. We show that it is possible this way to implement mental imagery-based planning in an algorithmically sound way by combining regular convolutional neural networks and generative adversarial networks. With this method, the robot acquires the capability to use the initially existing scene to generate action plans without symbolic domain descriptions, hence, without the need to define an explicit representation of the environment. We create a dataset from real scenes for a packing problem of having to correctly place different objects into different target slots. This way efficiency and success rate of this algorithm could be quantified.
Combining optimal path search with task-dependent learning in a neural network
Jan 27, 2022
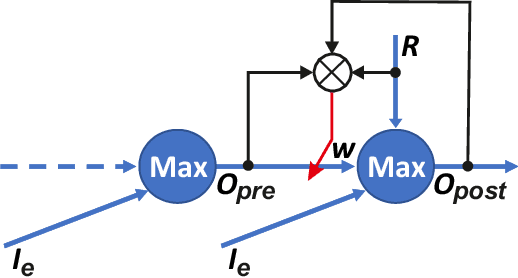


Finding optimal paths in connected graphs requires determining the smallest total cost for traveling along the graph's edges. This problem can be solved by several classical algorithms where, usually, costs are predefined for all edges. Conventional planning methods can, thus, normally not be used when wanting to change costs in an adaptive way following the requirements of some task. Here we show that one can define a neural network representation of path finding problems by transforming cost values into synaptic weights, which allows for online weight adaptation using network learning mechanisms. When starting with an initial activity value of one, activity propagation in this network will lead to solutions, which are identical to those found by the Bellman Ford algorithm. The neural network has the same algorithmic complexity as Bellman Ford and, in addition, we can show that network learning mechanisms (such as Hebbian learning) can adapt the weights in the network augmenting the resulting paths according to some task at hand. We demonstrate this by learning to navigate in an environment with obstacles as well as by learning to follow certain sequences of path nodes. Hence, the here-presented novel algorithm may open up a different regime of applications where path-augmentation (by learning) is directly coupled with path finding in a natural way.
Bootstrapping Concept Formation in Small Neural Networks
Oct 26, 2021


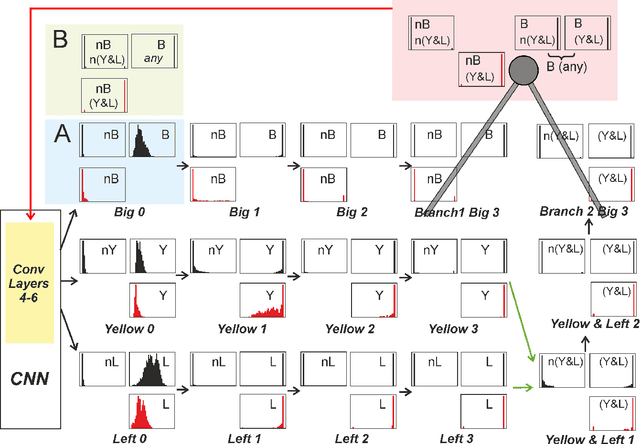
The question how neural systems (of humans) can perform reasoning is still far from being solved. We posit that the process of forming Concepts is a fundamental step required for this. We argue that, first, Concepts are formed as closed representations, which are then consolidated by relating them to each other. Here we present a model system (agent) with a small neural network that uses realistic learning rules and receives only feedback from the environment in which the agent performs virtual actions. First, the actions of the agent are reflexive. In the process of learning, statistical regularities in the input lead to the formation of neuronal pools representing relations between the entities observed by the agent from its artificial world. This information then influences the behavior of the agent via feedback connections replacing the initial reflex by an action driven by these relational representations. We hypothesize that the neuronal pools representing relational information can be considered as primordial Concepts, which may in a similar way be present in some pre-linguistic animals, too. We argue that systems such as this can help formalizing the discussion about what constitutes Concepts and serve as a starting point for constructing artificial cogitating systems.
Human and Machine Action Prediction Independent of Object Information
Apr 22, 2020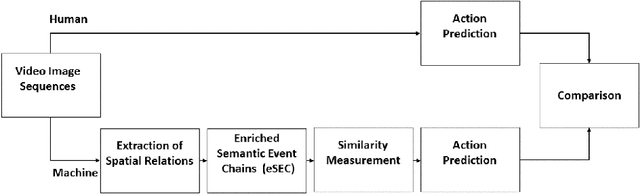
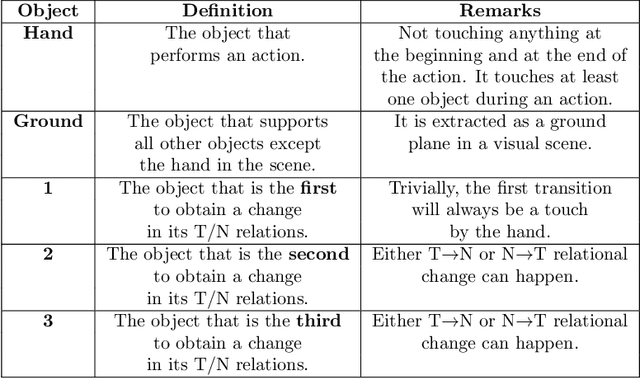

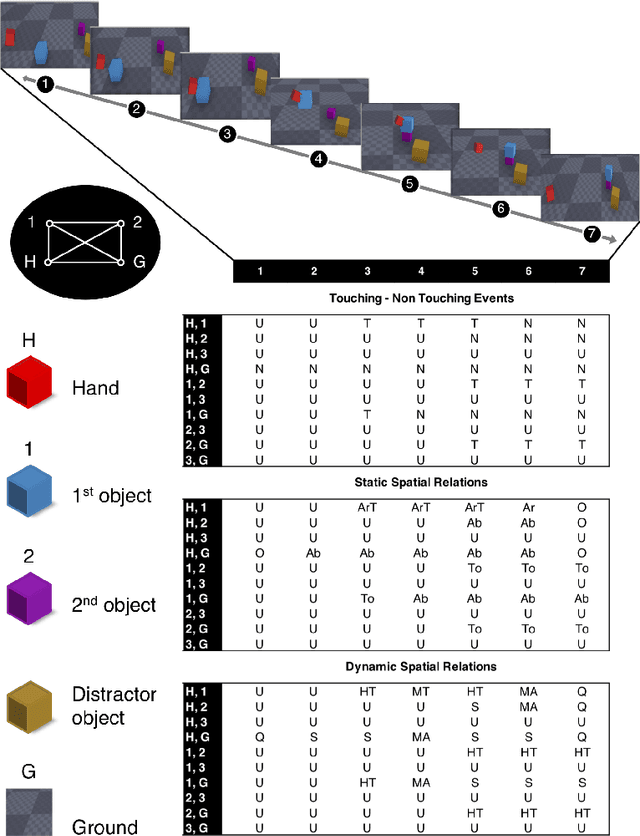
Predicting other people's action is key to successful social interactions, enabling us to adjust our own behavior to the consequence of the others' future actions. Studies on action recognition have focused on the importance of individual visual features of objects involved in an action and its context. Humans, however, recognize actions on unknown objects or even when objects are imagined (pantomime). Other cues must thus compensate the lack of recognizable visual object features. Here, we focus on the role of inter-object relations that change during an action. We designed a virtual reality setup and tested recognition speed for 10 different manipulation actions on 50 subjects. All objects were abstracted by emulated cubes so the actions could not be inferred using object information. Instead, subjects had to rely only on the information that comes from the changes in the spatial relations that occur between those cubes. In spite of these constraints, our results show the subjects were able to predict actions in, on average, less than 64% of the action's duration. We employed a computational model -an enriched Semantic Event Chain (eSEC)- incorporating the information of spatial relations, specifically (a) objects' touching/untouching, (b) static spatial relations between objects and (c) dynamic spatial relations between objects. Trained on the same actions as those observed by subjects, the model successfully predicted actions even better than humans. Information theoretical analysis shows that eSECs optimally use individual cues, whereas humans presumably mostly rely on a mixed-cue strategy, which takes longer until recognition. Providing a better cognitive basis of action recognition may, on one hand improve our understanding of related human pathologies and, on the other hand, also help to build robots for conflict-free human-robot cooperation. Our results open new avenues here.
Semantic Image Search for Robotic Applications
Apr 02, 2020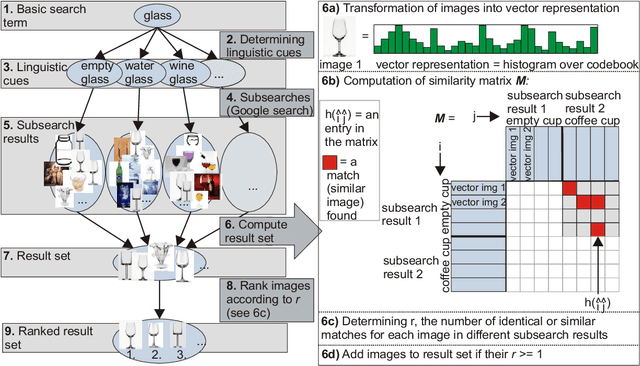
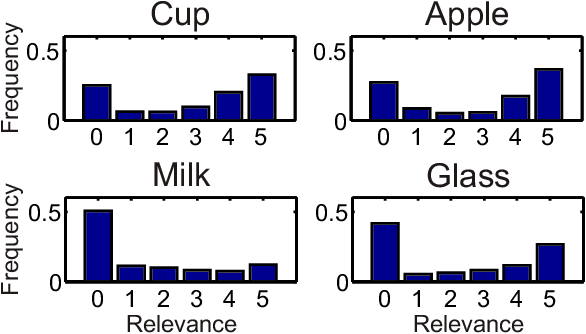


Generalization in robotics is one of the most important problems. New generalization approaches use internet databases in order to solve new tasks. Modern search engines can return a large amount of information according to a query within milliseconds. However, not all of the returned information is task relevant, partly due to the problem of polysemes. Here we specifically address the problem of object generalization by using image search. We suggest a bi-modal solution, combining visual and textual information, based on the observation that humans use additional linguistic cues to demarcate intended word meaning. We evaluate the quality of our approach by comparing it to human labelled data and find that, on average, our approach leads to improved results in comparison to Google searches, and that it can treat the problem of polysemes.
One-shot path planning for multi-agent systems using fully convolutional neural network
Apr 01, 2020

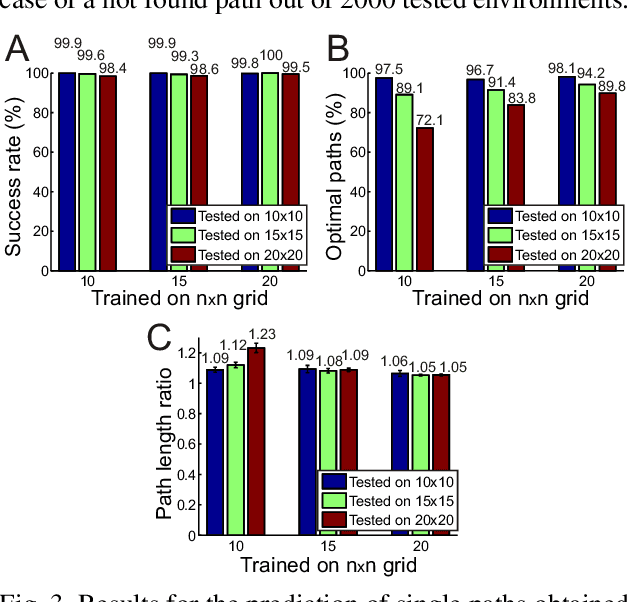
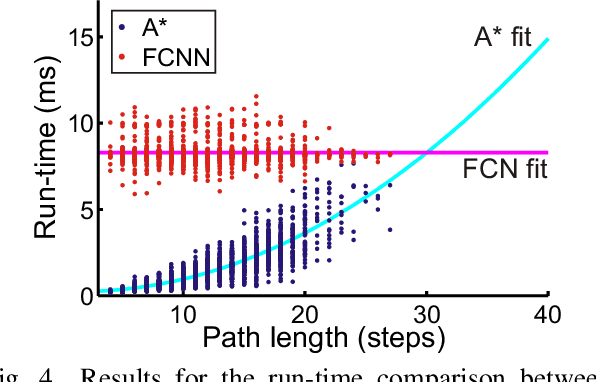
Path planning plays a crucial role in robot action execution, since a path or a motion trajectory for a particular action has to be defined first before the action can be executed. Most of the current approaches are iterative methods where the trajectory is generated iteratively by predicting the next state based on the current state. Moreover, in case of multi-agent systems, paths are planned for each agent separately. In contrast to that, we propose a novel method by utilising fully convolutional neural network, which allows generation of complete paths, even for more than one agent, in one-shot, i.e., with a single prediction step. We demonstrate that our method is able to successfully generate optimal or close to optimal paths in more than 98\% of the cases for single path predictions. Moreover, we show that although the network has never been trained on multi-path planning it is also able to generate optimal or close to optimal paths in 85.7\% and 65.4\% of the cases when generating two and three paths, respectively.
Generation of Paths in a Maze using a Deep Network without Learning
Apr 01, 2020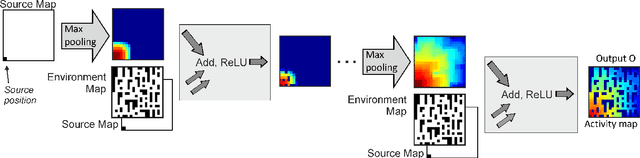
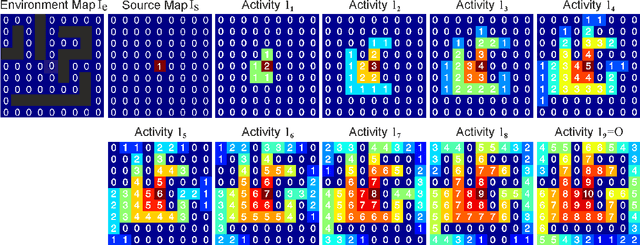
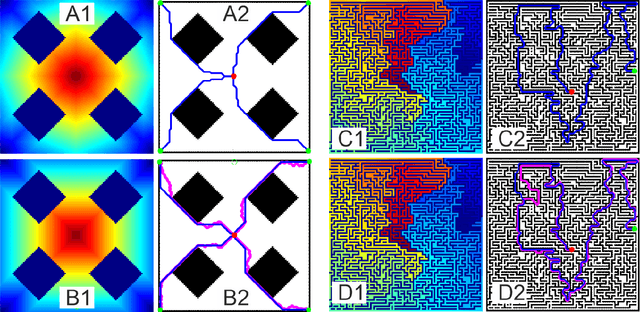
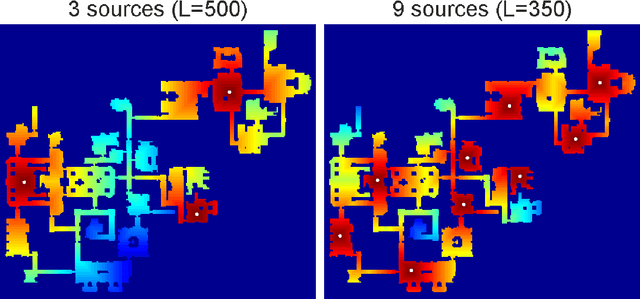
Trajectory- or path-planning is a fundamental issue in a wide variety of applications. Here we show that it is possible to solve path planning for multiple start- and end-points highly efficiently with a network that consists only of max pooling layers, for which no network training is needed. Different from competing approaches, very large mazes containing more than half a billion nodes with dense obstacle configuration and several thousand path end-points can this way be solved in very short time on parallel hardware.
Action Prediction in Humans and Robots
Jul 03, 2019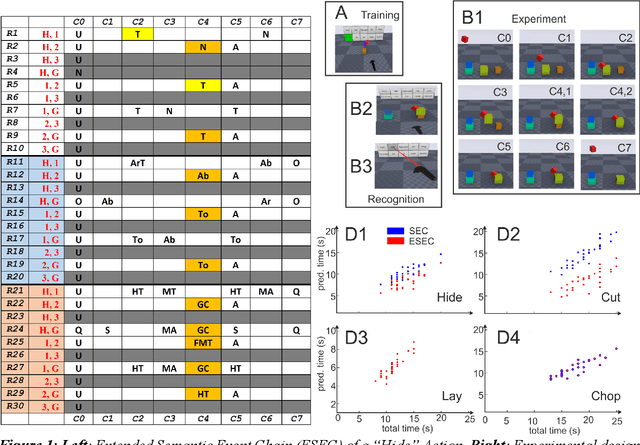
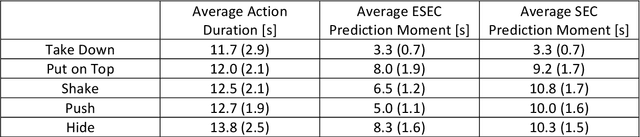
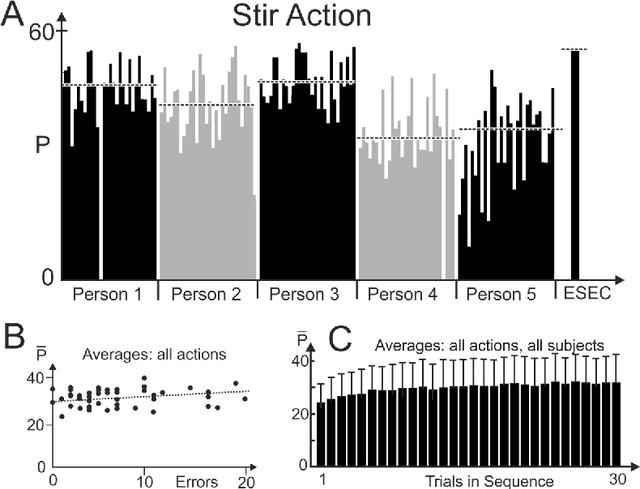
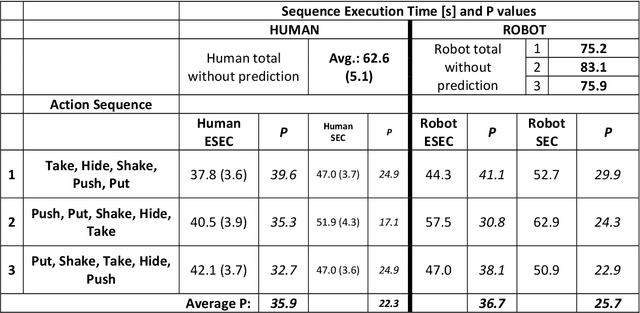
Efficient action prediction is of central importance for the fluent workflow between humans and equally so for human-robot interaction. To achieve prediction, actions can be encoded by a series of events, where every event corresponds to a change in a (static or dynamic) relation between some of the objects in a scene. Manipulation actions and others can be uniquely encoded this way and only, on average, less than 60% of the time series has to pass until an action can be predicted. Using a virtual reality setup and testing ten different manipulation actions, here we show that in most cases humans predict actions at the same event as the algorithm. In addition, we perform an in-depth analysis about the temporal gain resulting from such predictions when chaining actions and show in some robotic experiments that the percentage gain for humans and robots is approximately equal. Thus, if robots use this algorithm then their prediction-moments will be compatible to those of their human interaction partners, which should much benefit natural human-robot collaboration.