 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrAction: Action Recognition with Sparse Trajectories
Jun 02, 2026Modern action recognition models operate on memory- and compute-intensive dense RGB video volumes and frequently exploit appearance and background shortcuts, for example, predicting actions from objects or scenes instead of characteristic motion. We investigate an efficient alternative input modality that is largely free of such biases by construction: sparse point trajectories. To this end, we develop a simple transformer architecture for 2.5D trajectory-based recognition together with a masked-trajectory pretraining, which we show to substantially improve downstream action recognition accuracy. Despite using only a fraction of the dense RGB input, our method reaches 45% top-1 on Something-Something V2 and 54% on EPIC-Kitchens-100, and surpasses V-JEPA on time-reversal sensitivity. More importantly, we find trajectory features to be complementary to state-of-the-art appearance-based features. Fusing our pretrained model with DINOv2 and V-JEPA 2 improves top-1 accuracy on Something-Something V2 by 8.7 and 1.6 points, respectively. Code: https://github.com/ecker-lab/TrAction
A Circular Argument : Does RoPE need to be Equivariant for Vision?
Nov 11, 2025Rotary Positional Encodings (RoPE) have emerged as a highly effective technique for one-dimensional sequences in Natural Language Processing spurring recent progress towards generalizing RoPE to higher-dimensional data such as images and videos. The success of RoPE has been thought to be due to its positional equivariance, i.e. its status as a relative positional encoding. In this paper, we mathematically show RoPE to be one of the most general solutions for equivariant positional embedding in one-dimensional data. Moreover, we show Mixed RoPE to be the analogously general solution for M-dimensional data, if we require commutative generators -- a property necessary for RoPE's equivariance. However, we question whether strict equivariance plays a large role in RoPE's performance. We propose Spherical RoPE, a method analogous to Mixed RoPE, but assumes non-commutative generators. Empirically, we find Spherical RoPE to have the equivalent or better learning behavior compared to its equivariant analogues. This suggests that relative positional embeddings are not as important as is commonly believed, at least within computer vision. We expect this discovery to facilitate future work in positional encodings for vision that can be faster and generalize better by removing the preconception that they must be relative.
Do traveling waves make good positional encodings?
Nov 11, 2025
Transformers rely on positional encoding to compensate for the inherent permutation invariance of self-attention. Traditional approaches use absolute sinusoidal embeddings or learned positional vectors, while more recent methods emphasize relative encodings to better capture translation equivariances. In this work, we propose RollPE, a novel positional encoding mechanism based on traveling waves, implemented by applying a circular roll operation to the query and key tensors in self-attention. This operation induces a relative shift in phase across positions, allowing the model to compute attention as a function of positional differences rather than absolute indices. We show this simple method significantly outperforms traditional absolute positional embeddings and is comparable to RoPE. We derive a continuous case of RollPE which implicitly imposes a topographic structure on the query and key space. We further derive a mathematical equivalence of RollPE to a particular configuration of RoPE. Viewing RollPE through the lens of traveling waves may allow us to simplify RoPE and relate it to processes of information flow in the brain.
Minimizing Structural Vibrations via Guided Flow Matching Design Optimization
Jun 18, 2025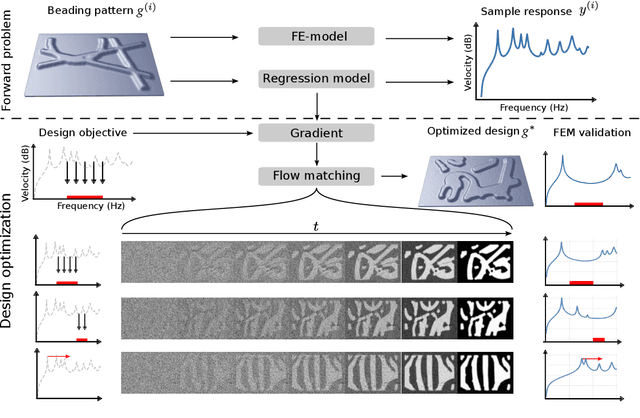



Structural vibrations are a source of unwanted noise in engineering systems like cars, trains or airplanes. Minimizing these vibrations is crucial for improving passenger comfort. This work presents a novel design optimization approach based on guided flow matching for reducing vibrations by placing beadings (indentations) in plate-like structures. Our method integrates a generative flow matching model and a surrogate model trained to predict structural vibrations. During the generation process, the flow matching model pushes towards manufacturability while the surrogate model pushes to low-vibration solutions. The flow matching model and its training data implicitly define the design space, enabling a broader exploration of potential solutions as no optimization of manually-defined design parameters is required. We apply our method to a range of differentiable optimization objectives, including direct optimization of specific eigenfrequencies through careful construction of the objective function. Results demonstrate that our method generates diverse and manufacturable plate designs with reduced structural vibrations compared to designs from random search, a criterion-based design heuristic and genetic optimization. The code and data are available from https://github.com/ecker-lab/Optimizing_Vibrating_Plates.
The impact of AI on engineering design procedures for dynamical systems
Dec 16, 2024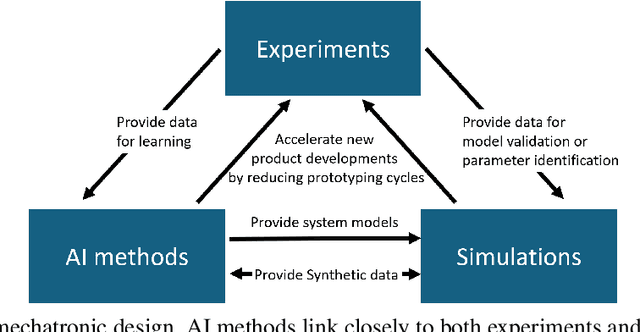



Artificial intelligence (AI) is driving transformative changes across numerous fields, revolutionizing conventional processes and creating new opportunities for innovation. The development of mechatronic systems is undergoing a similar transformation. Over the past decade, modeling, simulation, and optimization techniques have become integral to the design process, paving the way for the adoption of AI-based methods. In this paper, we examine the potential for integrating AI into the engineering design process, using the V-model from the VDI guideline 2206, considered the state-of-the-art in product design, as a foundation. We identify and classify AI methods based on their suitability for specific stages within the engineering product design workflow. Furthermore, we present a series of application examples where AI-assisted design has been successfully implemented by the authors. These examples, drawn from research projects within the DFG Priority Program \emph{SPP~2353: Daring More Intelligence - Design Assistants in Mechanics and Dynamics}, showcase a diverse range of applications across mechanics and mechatronics, including areas such as acoustics and robotics.
Computer Vision for Primate Behavior Analysis in the Wild
Jan 29, 2024Advances in computer vision as well as increasingly widespread video-based behavioral monitoring have great potential for transforming how we study animal cognition and behavior. However, there is still a fairly large gap between the exciting prospects and what can actually be achieved in practice today, especially in videos from the wild. With this perspective paper, we want to contribute towards closing this gap, by guiding behavioral scientists in what can be expected from current methods and steering computer vision researchers towards problems that are relevant to advance research in animal behavior. We start with a survey of the state-of-the-art methods for computer vision problems that are directly relevant to the video-based study of animal behavior, including object detection, multi-individual tracking, (inter)action recognition and individual identification. We then review methods for effort-efficient learning, which is one of the biggest challenges from a practical perspective. Finally, we close with an outlook into the future of the emerging field of computer vision for animal behavior, where we argue that the field should move fast beyond the common frame-by-frame processing and treat video as a first-class citizen.
Charting New Territories: Exploring the Geographic and Geospatial Capabilities of Multimodal LLMs
Nov 30, 2023
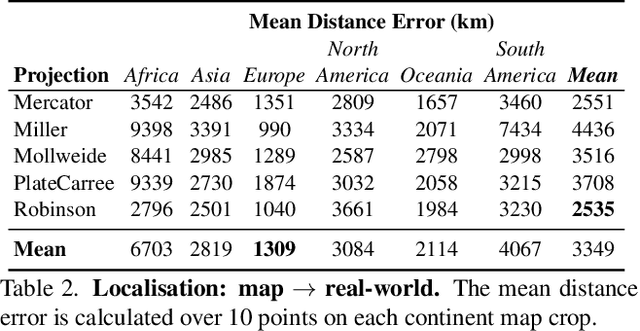


Multimodal large language models (MLLMs) have shown remarkable capabilities across a broad range of tasks but their knowledge and abilities in the geographic and geospatial domains are yet to be explored, despite potential wide-ranging benefits to navigation, environmental research, urban development, and disaster response. We conduct a series of experiments exploring various vision capabilities of MLLMs within these domains, particularly focusing on the frontier model GPT-4V, and benchmark its performance against open-source counterparts. Our methodology involves challenging these models with a small-scale geographic benchmark consisting of a suite of visual tasks, testing their abilities across a spectrum of complexity. The analysis uncovers not only where such models excel, including instances where they outperform humans, but also where they falter, providing a balanced view of their capabilities in the geographic domain. To enable the comparison and evaluation of future models, our benchmark will be publicly released.
Vibroacoustic Frequency Response Prediction with Query-based Operator Networks
Oct 11, 2023



Understanding vibroacoustic wave propagation in mechanical structures like airplanes, cars and houses is crucial to ensure health and comfort of their users. To analyze such systems, designers and engineers primarily consider the dynamic response in the frequency domain, which is computed through expensive numerical simulations like the finite element method. In contrast, data-driven surrogate models offer the promise of speeding up these simulations, thereby facilitating tasks like design optimization, uncertainty quantification, and design space exploration. We present a structured benchmark for a representative vibroacoustic problem: Predicting the frequency response for vibrating plates with varying forms of beadings. The benchmark features a total of 12,000 plate geometries with an associated numerical solution and introduces evaluation metrics to quantify the prediction quality. To address the frequency response prediction task, we propose a novel frequency query operator model, which is trained to map plate geometries to frequency response functions. By integrating principles from operator learning and implicit models for shape encoding, our approach effectively addresses the prediction of resonance peaks of frequency responses. We evaluate the method on our vibrating-plates benchmark and find that it outperforms DeepONets, Fourier Neural Operators and more traditional neural network architectures. The code and dataset are available from https://eckerlab.org/code/delden2023_plate.
GPT4GEO: How a Language Model Sees the World's Geography
May 30, 2023
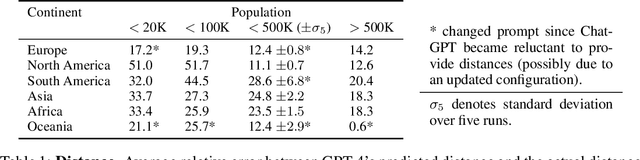
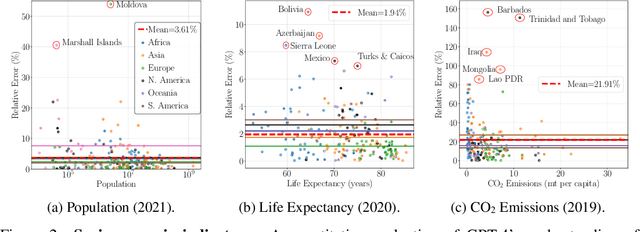
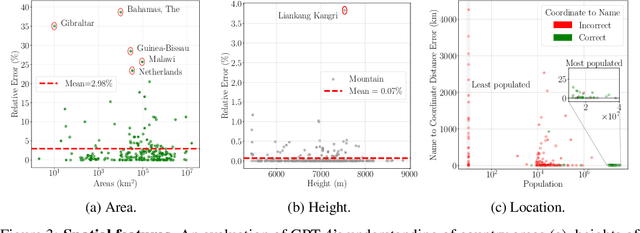
Large language models (LLMs) have shown remarkable capabilities across a broad range of tasks involving question answering and the generation of coherent text and code. Comprehensively understanding the strengths and weaknesses of LLMs is beneficial for safety, downstream applications and improving performance. In this work, we investigate the degree to which GPT-4 has acquired factual geographic knowledge and is capable of using this knowledge for interpretative reasoning, which is especially important for applications that involve geographic data, such as geospatial analysis, supply chain management, and disaster response. To this end, we design and conduct a series of diverse experiments, starting from factual tasks such as location, distance and elevation estimation to more complex questions such as generating country outlines and travel networks, route finding under constraints and supply chain analysis. We provide a broad characterisation of what GPT-4 (without plugins or Internet access) knows about the world, highlighting both potentially surprising capabilities but also limitations.
Self-supervised Representation Learning of Neuronal Morphologies
Jan 18, 2022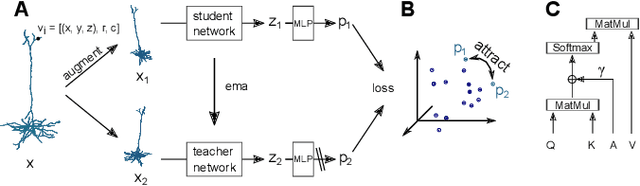
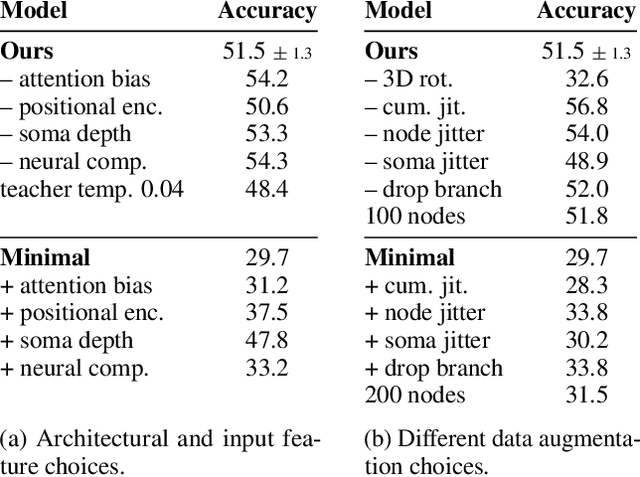
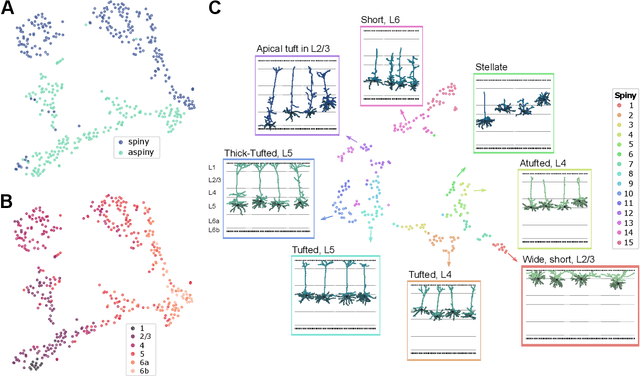
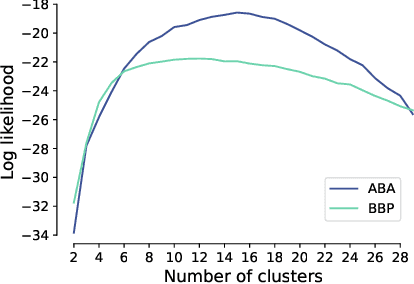
Understanding the diversity of cell types and their function in the brain is one of the key challenges in neuroscience. The advent of large-scale datasets has given rise to the need of unbiased and quantitative approaches to cell type classification. We present GraphDINO, a purely data-driven approach to learning a low dimensional representation of the 3D morphology of neurons. GraphDINO is a novel graph representation learning method for spatial graphs utilizing self-supervised learning on transformer models. It combines attention-based global interaction between nodes and classic graph convolutional processing. We show, in two different species and cortical areas, that this method is able to yield morphological cell type clustering that is comparable to manual feature-based classification and shows a good correspondence to expert-labeled cell types. Our method is applicable beyond neuroscience in settings where samples in a dataset are graphs and graph-level embeddings are desired.