 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Long Is a Piece of String? A Brief Empirical Analysis of Tokenizers
Jan 16, 2026Frontier LLMs are increasingly utilised across academia, society and industry. A commonly used unit for comparing models, their inputs and outputs, and estimating inference pricing is the token. In general, tokens are used as a stable currency, assumed to be broadly consistent across tokenizers and contexts, enabling direct comparisons. However, tokenization varies significantly across models and domains of text, making naive interpretation of token counts problematic. We quantify this variation by providing a comprehensive empirical analysis of tokenization, exploring the compression of sequences to tokens across different distributions of textual data. Our analysis challenges commonly held heuristics about token lengths, finding them to be overly simplistic. We hope the insights of our study add clarity and intuition toward tokenization in contemporary LLMs.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Beyond Outcomes: Transparent Assessment of LLM Reasoning in Games
Dec 18, 2024



Large Language Models (LLMs) are increasingly deployed in real-world applications that demand complex reasoning. To track progress, robust benchmarks are required to evaluate their capabilities beyond superficial pattern recognition. However, current LLM reasoning benchmarks often face challenges such as insufficient interpretability, performance saturation or data contamination. To address these challenges, we introduce GAMEBoT, a gaming arena designed for rigorous and transparent assessment of LLM reasoning capabilities. GAMEBoT decomposes complex reasoning in games into predefined modular subproblems. This decomposition allows us to design a suite of Chain-of-Thought (CoT) prompts that leverage domain knowledge to guide LLMs in addressing these subproblems before action selection. Furthermore, we develop a suite of rule-based algorithms to generate ground truth for these subproblems, enabling rigorous validation of the LLMs' intermediate reasoning steps. This approach facilitates evaluation of both the quality of final actions and the accuracy of the underlying reasoning process. GAMEBoT also naturally alleviates the risk of data contamination through dynamic games and head-to-head LLM competitions. We benchmark 17 prominent LLMs across eight games, encompassing various strategic abilities and game characteristics. Our results suggest that GAMEBoT presents a significant challenge, even when LLMs are provided with detailed CoT prompts. Project page: \url{https://visual-ai.github.io/gamebot}
Needle Threading: Can LLMs Follow Threads through Near-Million-Scale Haystacks?
Nov 07, 2024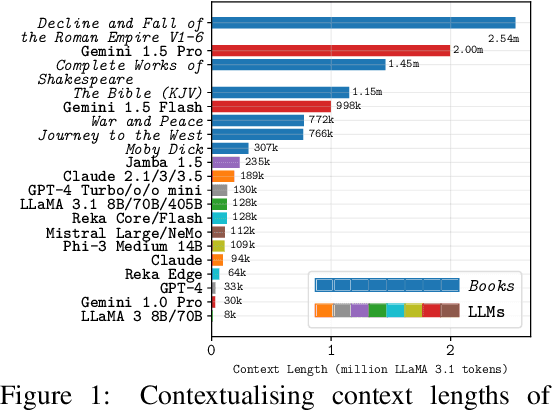
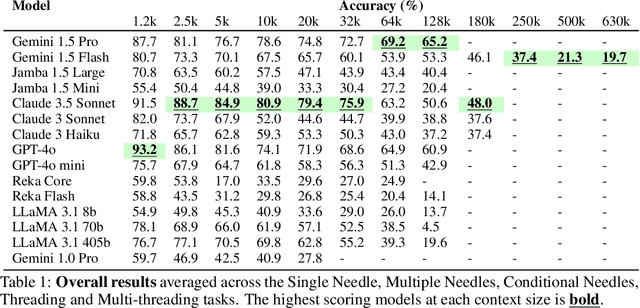
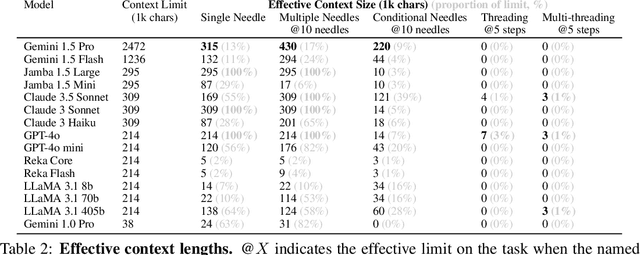
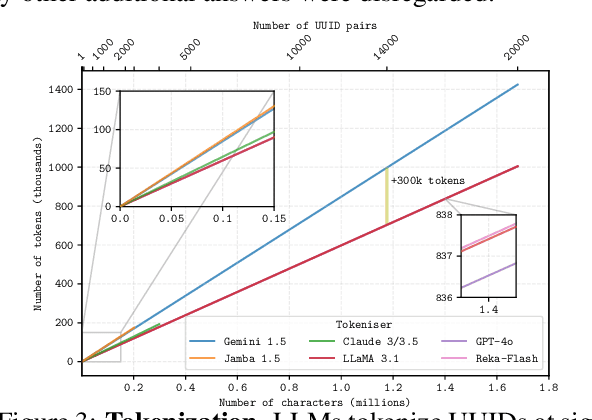
As the context limits of Large Language Models (LLMs) increase, the range of possible applications and downstream functions broadens. In many real-world tasks, decisions depend on details scattered across collections of often disparate documents containing mostly irrelevant information. Long-context LLMs appear well-suited to this form of complex information retrieval and reasoning, which has traditionally proven costly and time-consuming. However, although the development of longer context models has seen rapid gains in recent years, our understanding of how effectively LLMs use their context has not kept pace. To address this, we conduct a set of retrieval experiments designed to evaluate the capabilities of 17 leading LLMs, such as their ability to follow threads of information through the context window. Strikingly, we find that many models are remarkably threadsafe: capable of simultaneously following multiple threads without significant loss in performance. Still, for many models, we find the effective context limit is significantly shorter than the supported context length, with accuracy decreasing as the context window grows. Our study also highlights the important point that token counts from different tokenizers should not be directly compared -- they often correspond to substantially different numbers of written characters. We release our code and long-context experimental data.
GRAB: A Challenging GRaph Analysis Benchmark for Large Multimodal Models
Aug 21, 2024



Large multimodal models (LMMs) have exhibited proficiencies across many visual tasks. Although numerous well-known benchmarks exist to evaluate model performance, they increasingly have insufficient headroom. As such, there is a pressing need for a new generation of benchmarks challenging enough for the next generation of LMMs. One area that LMMs show potential is graph analysis, specifically, the tasks an analyst might typically perform when interpreting figures such as estimating the mean, intercepts or correlations of functions and data series. In this work, we introduce GRAB, a graph analysis benchmark, fit for current and future frontier LMMs. Our benchmark is entirely synthetic, ensuring high-quality, noise-free questions. GRAB is comprised of 2170 questions, covering four tasks and 23 graph properties. We evaluate 20 LMMs on GRAB, finding it to be a challenging benchmark, with the highest performing model attaining a score of just 21.7%. Finally, we conduct various ablations to investigate where the models succeed and struggle. We release GRAB to encourage progress in this important, growing domain.
SciFIBench: Benchmarking Large Multimodal Models for Scientific Figure Interpretation
May 14, 2024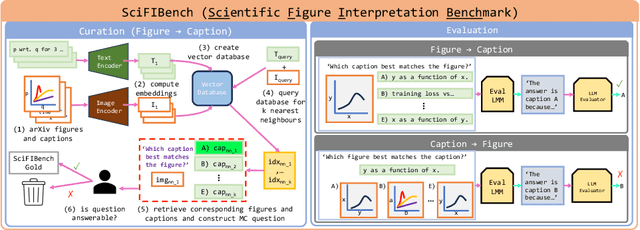
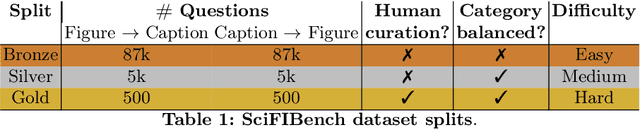
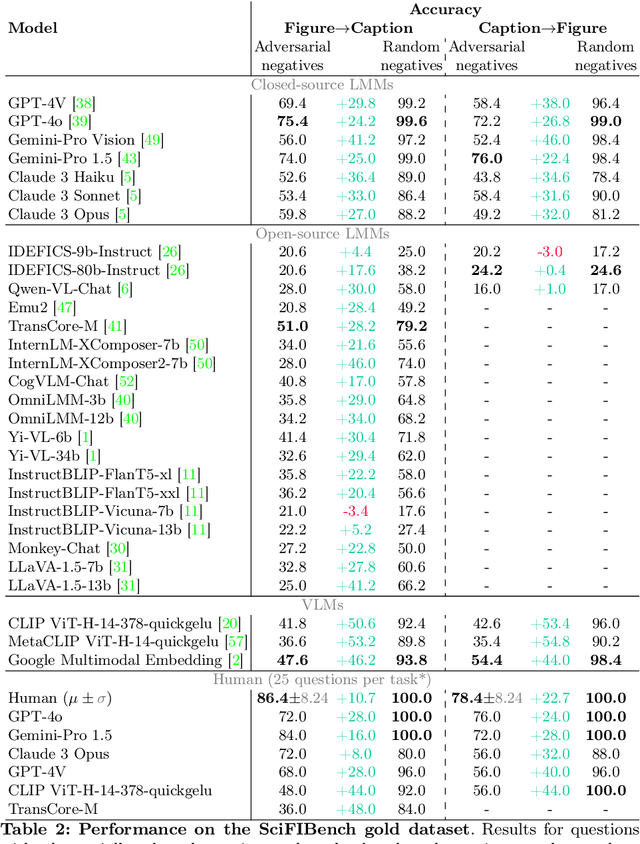
Large multimodal models (LMMs) have proven flexible and generalisable across many tasks and fields. Although they have strong potential to aid scientific research, their capabilities in this domain are not well characterised. A key aspect of scientific research is the ability to understand and interpret figures, which serve as a rich, compressed source of complex information. In this work, we present SciFIBench, a scientific figure interpretation benchmark. Our main benchmark consists of a 1000-question gold set of multiple-choice questions split between two tasks across 12 categories. The questions are curated from CS arXiv paper figures and captions, using adversarial filtering to find hard negatives and human verification for quality control. We evaluate 26 LMMs on SciFIBench, finding it to be a challenging benchmark. Finally, we investigate the alignment and reasoning faithfulness of the LMMs on augmented question sets from our benchmark. We release SciFIBench to encourage progress in this domain.
Charting New Territories: Exploring the Geographic and Geospatial Capabilities of Multimodal LLMs
Nov 30, 2023
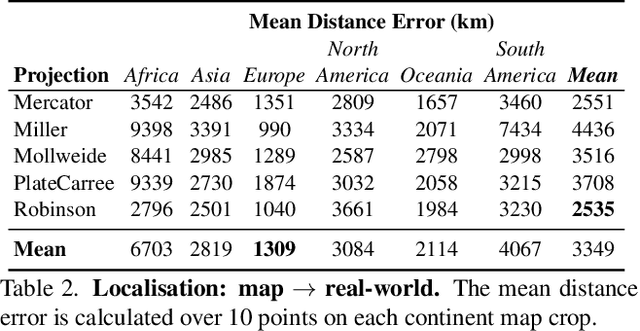


Multimodal large language models (MLLMs) have shown remarkable capabilities across a broad range of tasks but their knowledge and abilities in the geographic and geospatial domains are yet to be explored, despite potential wide-ranging benefits to navigation, environmental research, urban development, and disaster response. We conduct a series of experiments exploring various vision capabilities of MLLMs within these domains, particularly focusing on the frontier model GPT-4V, and benchmark its performance against open-source counterparts. Our methodology involves challenging these models with a small-scale geographic benchmark consisting of a suite of visual tasks, testing their abilities across a spectrum of complexity. The analysis uncovers not only where such models excel, including instances where they outperform humans, but also where they falter, providing a balanced view of their capabilities in the geographic domain. To enable the comparison and evaluation of future models, our benchmark will be publicly released.
GPT4GEO: How a Language Model Sees the World's Geography
May 30, 2023
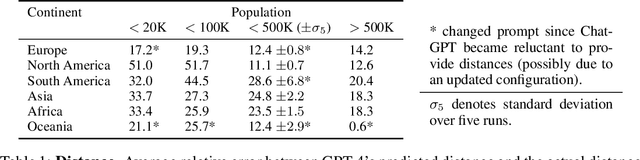
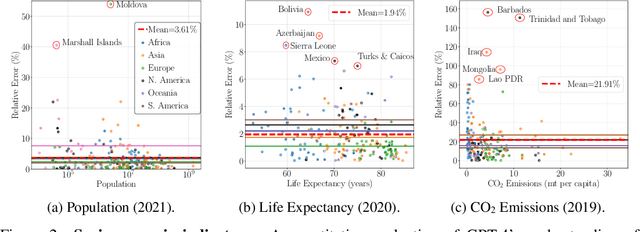
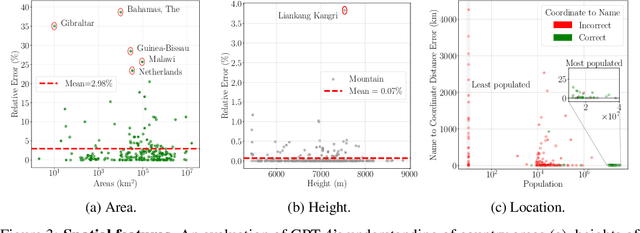
Large language models (LLMs) have shown remarkable capabilities across a broad range of tasks involving question answering and the generation of coherent text and code. Comprehensively understanding the strengths and weaknesses of LLMs is beneficial for safety, downstream applications and improving performance. In this work, we investigate the degree to which GPT-4 has acquired factual geographic knowledge and is capable of using this knowledge for interpretative reasoning, which is especially important for applications that involve geographic data, such as geospatial analysis, supply chain management, and disaster response. To this end, we design and conduct a series of diverse experiments, starting from factual tasks such as location, distance and elevation estimation to more complex questions such as generating country outlines and travel networks, route finding under constraints and supply chain analysis. We provide a broad characterisation of what GPT-4 (without plugins or Internet access) knows about the world, highlighting both potentially surprising capabilities but also limitations.
SATIN: A Multi-Task Metadataset for Classifying Satellite Imagery using Vision-Language Models
Apr 23, 2023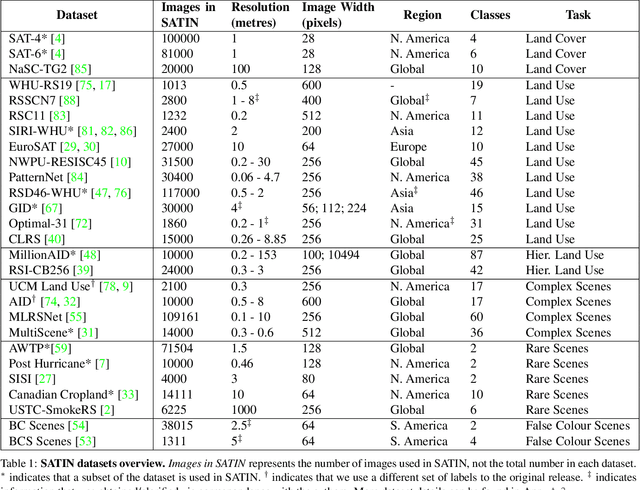
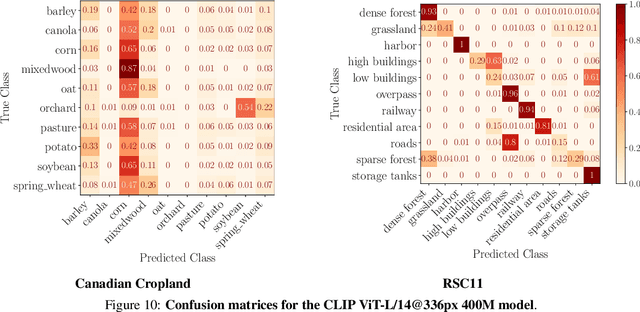
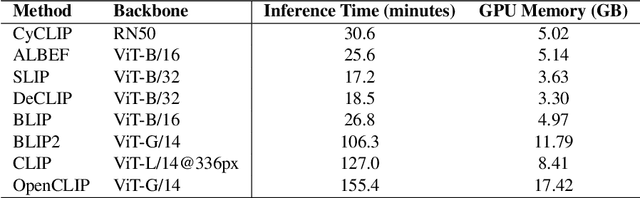
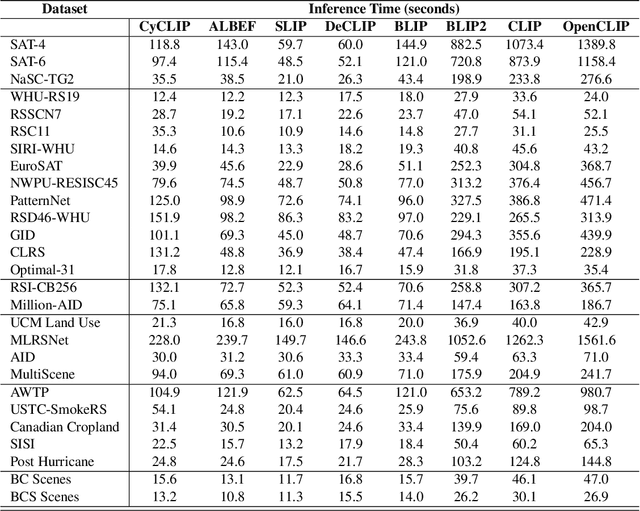
Interpreting remote sensing imagery enables numerous downstream applications ranging from land-use planning to deforestation monitoring. Robustly classifying this data is challenging due to the Earth's geographic diversity. While many distinct satellite and aerial image classification datasets exist, there is yet to be a benchmark curated that suitably covers this diversity. In this work, we introduce SATellite ImageNet (SATIN), a metadataset curated from 27 existing remotely sensed datasets, and comprehensively evaluate the zero-shot transfer classification capabilities of a broad range of vision-language (VL) models on SATIN. We find SATIN to be a challenging benchmark-the strongest method we evaluate achieves a classification accuracy of 52.0%. We provide a $\href{https://satinbenchmark.github.io}{\text{public leaderboard}}$ to guide and track the progress of VL models in this important domain.
3D Semantic Mapping from Arthroscopy using Out-of-distribution Pose and Depth and In-distribution Segmentation Training
Jun 10, 2021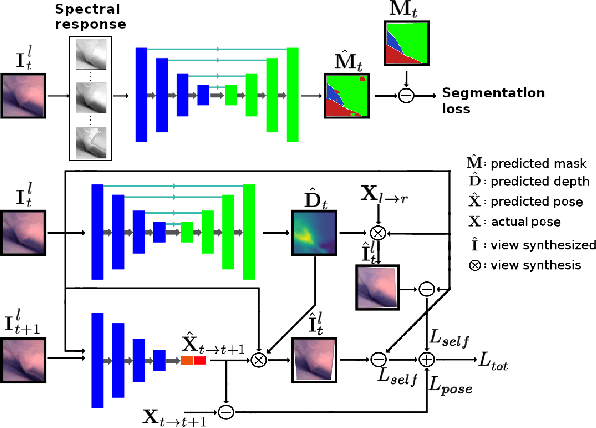
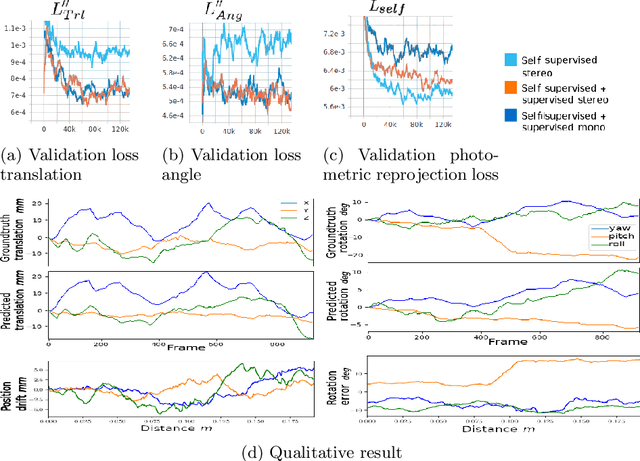
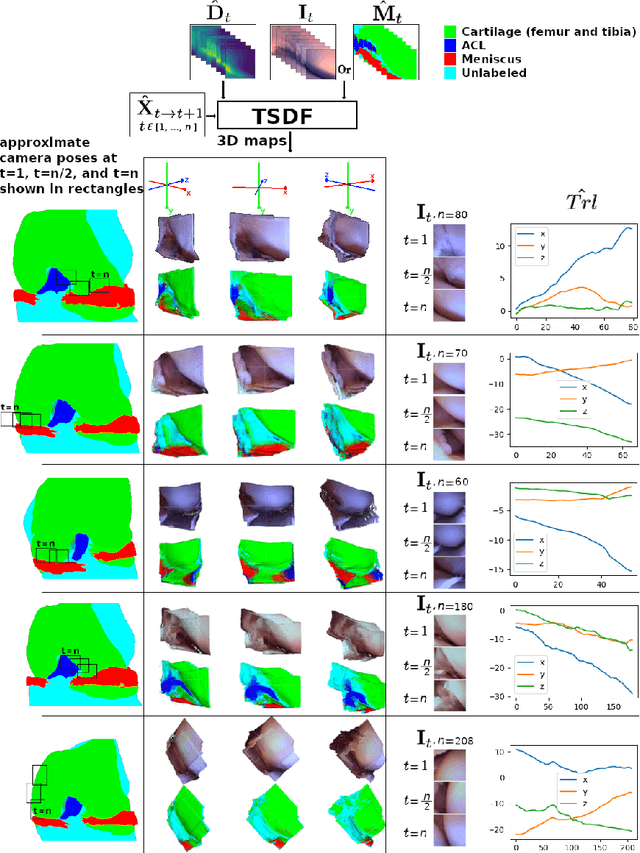
Minimally invasive surgery (MIS) has many documented advantages, but the surgeon's limited visual contact with the scene can be problematic. Hence, systems that can help surgeons navigate, such as a method that can produce a 3D semantic map, can compensate for the limitation above. In theory, we can borrow 3D semantic mapping techniques developed for robotics, but this requires finding solutions to the following challenges in MIS: 1) semantic segmentation, 2) depth estimation, and 3) pose estimation. In this paper, we propose the first 3D semantic mapping system from knee arthroscopy that solves the three challenges above. Using out-of-distribution non-human datasets, where pose could be labeled, we jointly train depth+pose estimators using selfsupervised and supervised losses. Using an in-distribution human knee dataset, we train a fully-supervised semantic segmentation system to label arthroscopic image pixels into femur, ACL, and meniscus. Taking testing images from human knees, we combine the results from these two systems to automatically create 3D semantic maps of the human knee. The result of this work opens the pathway to the generation of intraoperative 3D semantic mapping, registration with pre-operative data, and robotic-assisted arthroscopy