 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgical Post-Training: Cutting Errors, Keeping Knowledge
Mar 02, 2026Enhancing the reasoning capabilities of Large Language Models (LLMs) via post-training is often constrained by the trade-off between efficiency and catastrophic forgetting. While prior research emphasizes the role of on-policy data in mitigating forgetting, we uncover--and validate both theoretically and empirically--an overlooked yet critical mechanism: the implicit regularization inherent in Direct Preference Optimization's (DPO) reward estimate. This motivates our Surgical Post-Training (SPoT), a new paradigm designed to optimize reasoning efficiently while preserving learned prior knowledge. SPoT consists of: (1) a data rectification pipeline that employs an Oracle to surgically correct erroneous steps via minimal edits, generating data proximal to the model's distribution; and (2) a reward-based binary cross-entropy objective. Unlike the relative ranking in DPO, this objective treats reasoning correctness as a binary classification problem, enforcing decoupled supervision signals. Empirically, with only 4k rectified math data pairs, SPoT improves Qwen3-8B's accuracy by 6.2% on average across in-domain and OOD tasks, requiring merely 28 minutes of training on 8x H800 GPUs. Code: https://github.com/Visual-AI/SPoT
Beyond Outcomes: Transparent Assessment of LLM Reasoning in Games
Dec 18, 2024



Large Language Models (LLMs) are increasingly deployed in real-world applications that demand complex reasoning. To track progress, robust benchmarks are required to evaluate their capabilities beyond superficial pattern recognition. However, current LLM reasoning benchmarks often face challenges such as insufficient interpretability, performance saturation or data contamination. To address these challenges, we introduce GAMEBoT, a gaming arena designed for rigorous and transparent assessment of LLM reasoning capabilities. GAMEBoT decomposes complex reasoning in games into predefined modular subproblems. This decomposition allows us to design a suite of Chain-of-Thought (CoT) prompts that leverage domain knowledge to guide LLMs in addressing these subproblems before action selection. Furthermore, we develop a suite of rule-based algorithms to generate ground truth for these subproblems, enabling rigorous validation of the LLMs' intermediate reasoning steps. This approach facilitates evaluation of both the quality of final actions and the accuracy of the underlying reasoning process. GAMEBoT also naturally alleviates the risk of data contamination through dynamic games and head-to-head LLM competitions. We benchmark 17 prominent LLMs across eight games, encompassing various strategic abilities and game characteristics. Our results suggest that GAMEBoT presents a significant challenge, even when LLMs are provided with detailed CoT prompts. Project page: \url{https://visual-ai.github.io/gamebot}
Establishing a stronger baseline for lightweight contrastive models
Dec 14, 2022



Recent research has reported a performance degradation in self-supervised contrastive learning for specially designed efficient networks, such as MobileNet and EfficientNet. A common practice to address this problem is to introduce a pretrained contrastive teacher model and train the lightweight networks with distillation signals generated by the teacher. However, it is time and resource consuming to pretrain a teacher model when it is not available. In this work, we aim to establish a stronger baseline for lightweight contrastive models without using a pretrained teacher model. Specifically, we show that the optimal recipe for efficient models is different from that of larger models, and using the same training settings as ResNet50, as previous research does, is inappropriate. Additionally, we observe a common issu e in contrastive learning where either the positive or negative views can be noisy, and propose a smoothed version of InfoNCE loss to alleviate this problem. As a result, we successfully improve the linear evaluation results from 36.3\% to 62.3\% for MobileNet-V3-Large and from 42.2\% to 65.8\% for EfficientNet-B0 on ImageNet, closing the accuracy gap to ResNet50 with $5\times$ fewer parameters. We hope our research will facilitate the usage of lightweight contrastive models.
Efficient Sub-structured Knowledge Distillation
Mar 09, 2022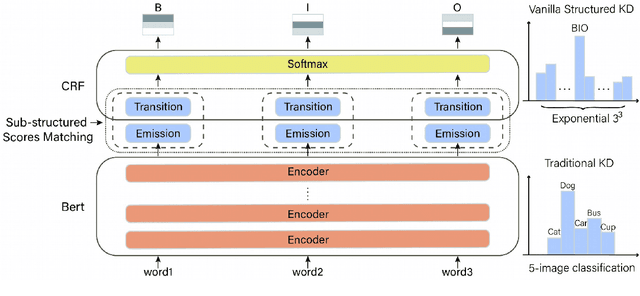
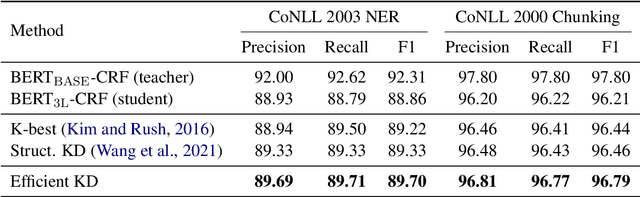

Structured prediction models aim at solving a type of problem where the output is a complex structure, rather than a single variable. Performing knowledge distillation for such models is not trivial due to their exponentially large output space. In this work, we propose an approach that is much simpler in its formulation and far more efficient for training than existing approaches. Specifically, we transfer the knowledge from a teacher model to its student model by locally matching their predictions on all sub-structures, instead of the whole output space. In this manner, we avoid adopting some time-consuming techniques like dynamic programming (DP) for decoding output structures, which permits parallel computation and makes the training process even faster in practice. Besides, it encourages the student model to better mimic the internal behavior of the teacher model. Experiments on two structured prediction tasks demonstrate that our approach outperforms previous methods and halves the time cost for one training epoch.