 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSplat: A Deep Dive into Geometry-Constrained Gaussian Splatting
Sep 05, 2025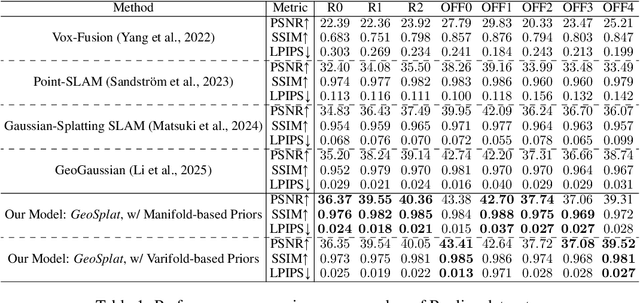
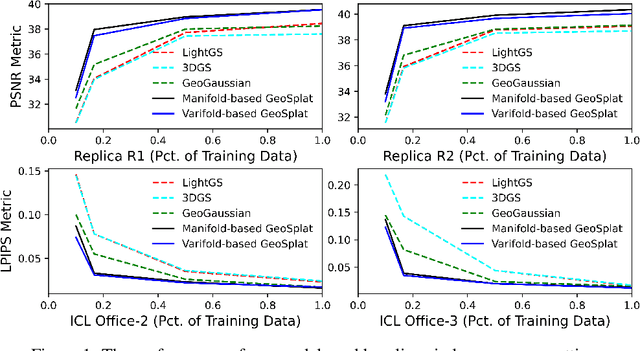
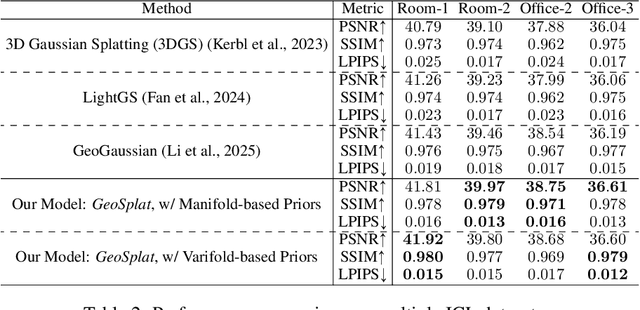

A few recent works explored incorporating geometric priors to regularize the optimization of Gaussian splatting, further improving its performance. However, those early studies mainly focused on the use of low-order geometric priors (e.g., normal vector), and they are also unreliably estimated by noise-sensitive methods, like local principal component analysis. To address their limitations, we first present GeoSplat, a general geometry-constrained optimization framework that exploits both first-order and second-order geometric quantities to improve the entire training pipeline of Gaussian splatting, including Gaussian initialization, gradient update, and densification. As an example, we initialize the scales of 3D Gaussian primitives in terms of principal curvatures, leading to a better coverage of the object surface than random initialization. Secondly, based on certain geometric structures (e.g., local manifold), we introduce efficient and noise-robust estimation methods that provide dynamic geometric priors for our framework. We conduct extensive experiments on multiple datasets for novel view synthesis, showing that our framework: GeoSplat, significantly improves the performance of Gaussian splatting and outperforms previous baselines.
Conservation-preserved Fourier Neural Operator through Adaptive Correction
May 30, 2025



Fourier Neural Operators (FNOs) have recently emerged as a promising and efficient approach for learning the numerical solutions to partial differential equations (PDEs) from data. However, standard FNO often fails to preserve key conservation laws, such as mass conservation, momentum conservation, norm conservation, etc., which are crucial for accurately modeling physical systems. Existing methods for incorporating these conservation laws into Fourier neural operators are achieved by designing related loss function or incorporating post-processing method at the training time. None of them can both exactly and adaptively correct the outputs to satisfy conservation laws, and our experiments show that these methods can lead to inferior performance while preserving conservation laws. In this work, we propose a novel adaptive correction approach to ensure the conservation of fundamental quantities. Our method introduces a learnable matrix to adaptively adjust the solution to satisfy the conservation law during training. It ensures that the outputs exactly satisfy the goal conservation law and allow for more flexibility and adaptivity for the model to correct the outputs. We theoretically show that applying our adaptive correction to an unconstrained FNO yields a solution with data loss no worse than that of the best conservation-satisfying FNO. We compare our approach with existing methods on a range of representative PDEs. Experiment results show that our method consistently outperform other methods.
Revealing Weaknesses in Text Watermarking Through Self-Information Rewrite Attacks
May 08, 2025Text watermarking aims to subtly embed statistical signals into text by controlling the Large Language Model (LLM)'s sampling process, enabling watermark detectors to verify that the output was generated by the specified model. The robustness of these watermarking algorithms has become a key factor in evaluating their effectiveness. Current text watermarking algorithms embed watermarks in high-entropy tokens to ensure text quality. In this paper, we reveal that this seemingly benign design can be exploited by attackers, posing a significant risk to the robustness of the watermark. We introduce a generic efficient paraphrasing attack, the Self-Information Rewrite Attack (SIRA), which leverages the vulnerability by calculating the self-information of each token to identify potential pattern tokens and perform targeted attack. Our work exposes a widely prevalent vulnerability in current watermarking algorithms. The experimental results show SIRA achieves nearly 100% attack success rates on seven recent watermarking methods with only 0.88 USD per million tokens cost. Our approach does not require any access to the watermark algorithms or the watermarked LLM and can seamlessly transfer to any LLM as the attack model, even mobile-level models. Our findings highlight the urgent need for more robust watermarking.
Generative Unordered Flow for Set-Structured Data Generation
Jan 29, 2025Flow-based generative models have demonstrated promising performance across a broad spectrum of data modalities (e.g., image and text). However, there are few works exploring their extension to unordered data (e.g., spatial point set), which is not trivial because previous models are mostly designed for vector data that are naturally ordered. In this paper, we present unordered flow, a type of flow-based generative model for set-structured data generation. Specifically, we convert unordered data into an appropriate function representation, and learn the probability measure of such representations through function-valued flow matching. For the inverse map from a function representation to unordered data, we propose a method similar to particle filtering, with Langevin dynamics to first warm-up the initial particles and gradient-based search to update them until convergence. We have conducted extensive experiments on multiple real-world datasets, showing that our unordered flow model is very effective in generating set-structured data and significantly outperforms previous baselines.
Bellman Diffusion: Generative Modeling as Learning a Linear Operator in the Distribution Space
Oct 02, 2024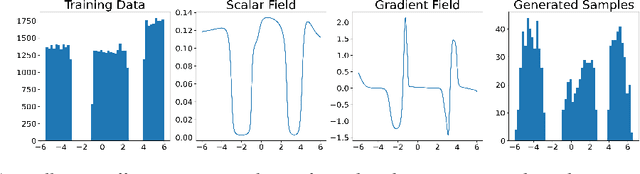
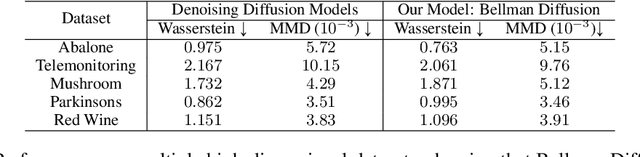
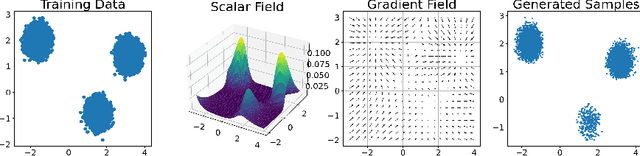
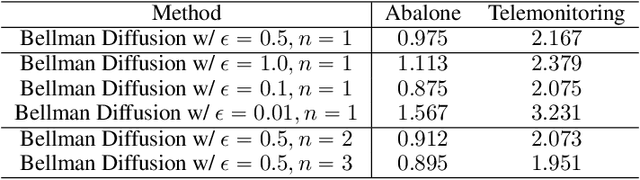
Deep Generative Models (DGMs), including Energy-Based Models (EBMs) and Score-based Generative Models (SGMs), have advanced high-fidelity data generation and complex continuous distribution approximation. However, their application in Markov Decision Processes (MDPs), particularly in distributional Reinforcement Learning (RL), remains underexplored, with conventional histogram-based methods dominating the field. This paper rigorously highlights that this application gap is caused by the nonlinearity of modern DGMs, which conflicts with the linearity required by the Bellman equation in MDPs. For instance, EBMs involve nonlinear operations such as exponentiating energy functions and normalizing constants. To address this, we introduce Bellman Diffusion, a novel DGM framework that maintains linearity in MDPs through gradient and scalar field modeling. With divergence-based training techniques to optimize neural network proxies and a new type of stochastic differential equation (SDE) for sampling, Bellman Diffusion is guaranteed to converge to the target distribution. Our empirical results show that Bellman Diffusion achieves accurate field estimations and is a capable image generator, converging 1.5x faster than the traditional histogram-based baseline in distributional RL tasks. This work enables the effective integration of DGMs into MDP applications, unlocking new avenues for advanced decision-making frameworks.
A Study of Posterior Stability for Time-Series Latent Diffusion
May 22, 2024Latent diffusion has shown promising results in image generation and permits efficient sampling. However, this framework might suffer from the problem of posterior collapse when applied to time series. In this paper, we conduct an impact analysis of this problem. With a theoretical insight, we first explain that posterior collapse reduces latent diffusion to a VAE, making it less expressive. Then, we introduce the notion of dependency measures, showing that the latent variable sampled from the diffusion model loses control of the generation process in this situation and that latent diffusion exhibits dependency illusion in the case of shuffled time series. We also analyze the causes of posterior collapse and introduce a new framework based on this analysis, which addresses the problem and supports a more expressive prior distribution. Our experiments on various real-world time-series datasets demonstrate that our new model maintains a stable posterior and outperforms the baselines in time series generation.
Risk-Sensitive Diffusion: Learning the Underlying Distribution from Noisy Samples
Feb 03, 2024While achieving remarkable performances, we show that diffusion models are fragile to the presence of noisy samples, limiting their potential in the vast amount of settings where, unlike image synthesis, we are not blessed with clean data. Motivated by our finding that such fragility originates from the distribution gaps between noisy and clean samples along the diffusion process, we introduce risk-sensitive SDE, a stochastic differential equation that is parameterized by the risk (i.e., data "dirtiness") to adjust the distributions of noisy samples, reducing misguidance while benefiting from their contained information. The optimal expression for risk-sensitive SDE depends on the specific noise distribution, and we derive its parameterizations that minimize the misguidance of noisy samples for both Gaussian and general non-Gaussian perturbations. We conduct extensive experiments on both synthetic and real-world datasets (e.g., medical time series), showing that our model effectively recovers the clean data distribution from noisy samples, significantly outperforming conditional generation baselines.
TS-Diffusion: Generating Highly Complex Time Series with Diffusion Models
Nov 06, 2023While current generative models have achieved promising performances in time-series synthesis, they either make strong assumptions on the data format (e.g., regularities) or rely on pre-processing approaches (e.g., interpolations) to simplify the raw data. In this work, we consider a class of time series with three common bad properties, including sampling irregularities, missingness, and large feature-temporal dimensions, and introduce a general model, TS-Diffusion, to process such complex time series. Our model consists of three parts under the framework of point process. The first part is an encoder of the neural ordinary differential equation (ODE) that converts time series into dense representations, with the jump technique to capture sampling irregularities and self-attention mechanism to handle missing values; The second component of TS-Diffusion is a diffusion model that learns from the representation of time series. These time-series representations can have a complex distribution because of their high dimensions; The third part is a decoder of another ODE that generates time series with irregularities and missing values given their representations. We have conducted extensive experiments on multiple time-series datasets, demonstrating that TS-Diffusion achieves excellent results on both conventional and complex time series and significantly outperforms previous baselines.
Soft Mixture Denoising: Beyond the Expressive Bottleneck of Diffusion Models
Sep 28, 2023

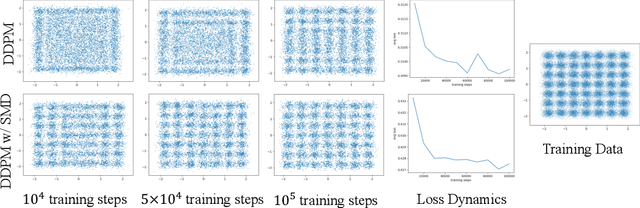
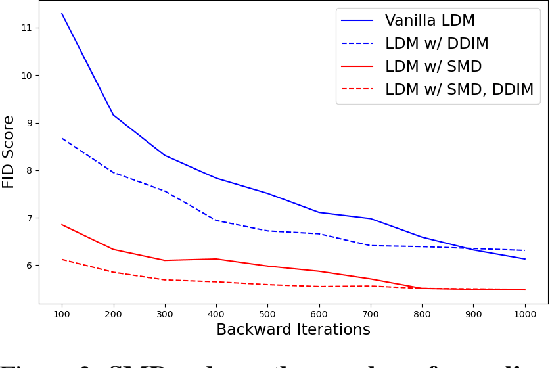
Because diffusion models have shown impressive performances in a number of tasks, such as image synthesis, there is a trend in recent works to prove (with certain assumptions) that these models have strong approximation capabilities. In this paper, we show that current diffusion models actually have an expressive bottleneck in backward denoising and some assumption made by existing theoretical guarantees is too strong. Based on this finding, we prove that diffusion models have unbounded errors in both local and global denoising. In light of our theoretical studies, we introduce soft mixture denoising (SMD), an expressive and efficient model for backward denoising. SMD not only permits diffusion models to well approximate any Gaussian mixture distributions in theory, but also is simple and efficient for implementation. Our experiments on multiple image datasets show that SMD significantly improves different types of diffusion models (e.g., DDPM), espeically in the situation of few backward iterations.
Do Diffusion Models Suffer Error Propagation? Theoretical Analysis and Consistency Regularization
Aug 09, 2023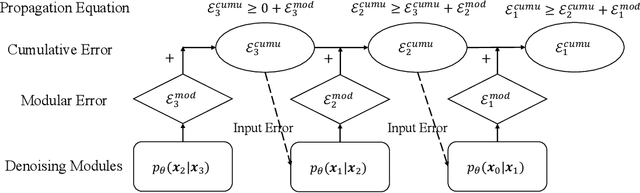

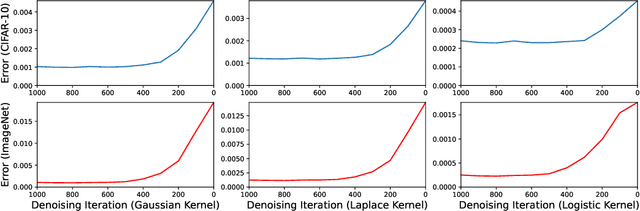

While diffusion models have achieved promising performances in data synthesis, they might suffer error propagation because of their cascade structure, where the distributional mismatch spreads and magnifies through the chain of denoising modules. However, a strict analysis is expected since many sequential models such as Conditional Random Field (CRF) are free from error propagation. In this paper, we empirically and theoretically verify that diffusion models are indeed affected by error propagation and we then propose a regularization to address this problem. Our theoretical analysis reveals that the question can be reduced to whether every denoising module of the diffusion model is fault-tolerant. We derive insightful transition equations, indicating that the module can't recover from input errors and even propagates additional errors to the next module. Our analysis directly leads to a consistency regularization scheme for diffusion models, which explicitly reduces the distribution gap between forward and backward processes. We further introduce a bootstrapping algorithm to reduce the computation cost of the regularizer. Our experimental results on multiple image datasets show that our regularization effectively handles error propagation and significantly improves the performance of vanilla diffusion models.