 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonotone Optimisation with Learned Projections
Jan 28, 2026Monotone optimisation problems admit specialised global solvers such as the Polyblock Outer Approximation (POA) algorithm, but these methods typically require explicit objective and constraint functions. In many applications, these functions are only available through data, making POA difficult to apply directly. We introduce an algorithm-aware learning approach that integrates learned models into POA by directly predicting its projection primitive via the radial inverse, avoiding the costly bisection procedure used in standard POA. We propose Homogeneous-Monotone Radial Inverse (HM-RI) networks, structured neural architectures that enforce key monotonicity and homogeneity properties, enabling fast projection estimation. We provide a theoretical characterisation of radial inverse functions and show that, under mild structural conditions, a HM-RI predictor corresponds to the radial inverse of a valid set of monotone constraints. To reduce training overhead, we further develop relaxed monotonicity conditions that remain compatible with POA. Across multiple monotone optimisation benchmarks (indefinite quadratic programming, multiplicative programming, and transmit power optimisation), our approach yields substantial speed-ups in comparison to direct function estimation while maintaining strong solution quality, outperforming baselines that do not exploit monotonic structure.
Factored Value Functions for Graph-Based Multi-Agent Reinforcement Learning
Jan 16, 2026Credit assignment is a core challenge in multi-agent reinforcement learning (MARL), especially in large-scale systems with structured, local interactions. Graph-based Markov decision processes (GMDPs) capture such settings via an influence graph, but standard critics are poorly aligned with this structure: global value functions provide weak per-agent learning signals, while existing local constructions can be difficult to estimate and ill-behaved in infinite-horizon settings. We introduce the Diffusion Value Function (DVF), a factored value function for GMDPs that assigns to each agent a value component by diffusing rewards over the influence graph with temporal discounting and spatial attenuation. We show that DVF is well-defined, admits a Bellman fixed point, and decomposes the global discounted value via an averaging property. DVF can be used as a drop-in critic in standard RL algorithms and estimated scalably with graph neural networks. Building on DVF, we propose Diffusion A2C (DA2C) and a sparse message-passing actor, Learned DropEdge GNN (LD-GNN), for learning decentralised algorithms under communication costs. Across the firefighting benchmark and three distributed computation tasks (vector graph colouring and two transmit power optimisation problems), DA2C consistently outperforms local and global critic baselines, improving average reward by up to 11%.
Conservation-preserved Fourier Neural Operator through Adaptive Correction
May 30, 2025



Fourier Neural Operators (FNOs) have recently emerged as a promising and efficient approach for learning the numerical solutions to partial differential equations (PDEs) from data. However, standard FNO often fails to preserve key conservation laws, such as mass conservation, momentum conservation, norm conservation, etc., which are crucial for accurately modeling physical systems. Existing methods for incorporating these conservation laws into Fourier neural operators are achieved by designing related loss function or incorporating post-processing method at the training time. None of them can both exactly and adaptively correct the outputs to satisfy conservation laws, and our experiments show that these methods can lead to inferior performance while preserving conservation laws. In this work, we propose a novel adaptive correction approach to ensure the conservation of fundamental quantities. Our method introduces a learnable matrix to adaptively adjust the solution to satisfy the conservation law during training. It ensures that the outputs exactly satisfy the goal conservation law and allow for more flexibility and adaptivity for the model to correct the outputs. We theoretically show that applying our adaptive correction to an unconstrained FNO yields a solution with data loss no worse than that of the best conservation-satisfying FNO. We compare our approach with existing methods on a range of representative PDEs. Experiment results show that our method consistently outperform other methods.
Inverse Evolution Data Augmentation for Neural PDE Solvers
Jan 24, 2025Neural networks have emerged as promising tools for solving partial differential equations (PDEs), particularly through the application of neural operators. Training neural operators typically requires a large amount of training data to ensure accuracy and generalization. In this paper, we propose a novel data augmentation method specifically designed for training neural operators on evolution equations. Our approach utilizes insights from inverse processes of these equations to efficiently generate data from random initialization that are combined with original data. To further enhance the accuracy of the augmented data, we introduce high-order inverse evolution schemes. These schemes consist of only a few explicit computation steps, yet the resulting data pairs can be proven to satisfy the corresponding implicit numerical schemes. In contrast to traditional PDE solvers that require small time steps or implicit schemes to guarantee accuracy, our data augmentation method employs explicit schemes with relatively large time steps, thereby significantly reducing computational costs. Accuracy and efficacy experiments confirm the effectiveness of our approach. Additionally, we validate our approach through experiments with the Fourier Neural Operator and UNet on three common evolution equations that are Burgers' equation, the Allen-Cahn equation and the Navier-Stokes equation. The results demonstrate a significant improvement in the performance and robustness of the Fourier Neural Operator when coupled with our inverse evolution data augmentation method.
G-Adaptive mesh refinement -- leveraging graph neural networks and differentiable finite element solvers
Jul 05, 2024We present a novel, and effective, approach to the long-standing problem of mesh adaptivity in finite element methods (FEM). FE solvers are powerful tools for solving partial differential equations (PDEs), but their cost and accuracy are critically dependent on the choice of mesh points. To keep computational costs low, mesh relocation (r-adaptivity) seeks to optimise the position of a fixed number of mesh points to obtain the best FE solution accuracy. Classical approaches to this problem require the solution of a separate nonlinear "meshing" PDE to find the mesh point locations. This incurs significant cost at remeshing and relies on certain a-priori assumptions and guiding heuristics for optimal mesh point location. Recent machine learning approaches to r-adaptivity have mainly focused on the construction of fast surrogates for such classical methods. Our new approach combines a graph neural network (GNN) powered architecture, with training based on direct minimisation of the FE solution error with respect to the mesh point locations. The GNN employs graph neural diffusion (GRAND), closely aligning the mesh solution space to that of classical meshing methodologies, thus replacing heuristics with a learnable strategy, and providing a strong inductive bias. This allows for rapid and robust training and results in an extremely efficient and effective GNN approach to online r-adaptivity. This method outperforms classical and prior ML approaches to r-adaptive meshing on the test problems we consider, in particular achieving lower FE solution error, whilst retaining the significant speed-up over classical methods observed in prior ML work.
Equidistribution-based training of Free Knot Splines and ReLU Neural Networks
Jul 02, 2024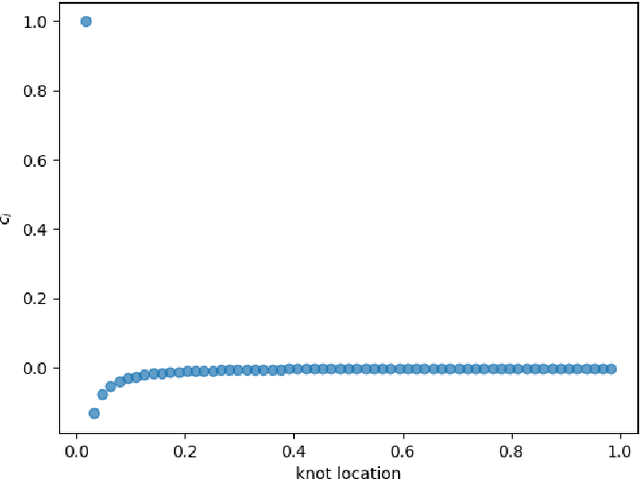

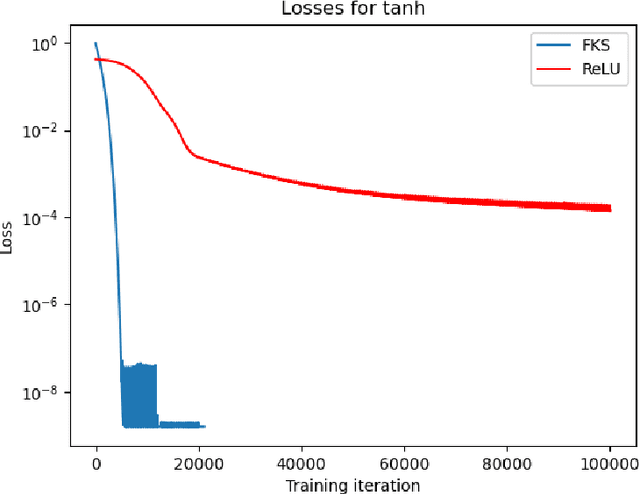
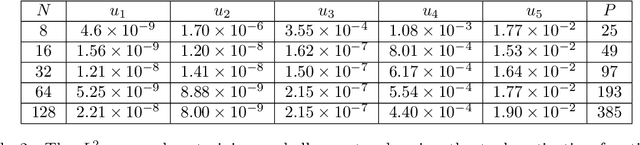
We consider the problem of one-dimensional function approximation using shallow neural networks (NN) with a rectified linear unit (ReLU) activation function and compare their training with traditional methods such as univariate Free Knot Splines (FKS). ReLU NNs and FKS span the same function space, and thus have the same theoretical expressivity. In the case of ReLU NNs, we show that their ill-conditioning degrades rapidly as the width of the network increases. This often leads to significantly poorer approximation in contrast to the FKS representation, which remains well-conditioned as the number of knots increases. We leverage the theory of optimal piecewise linear interpolants to improve the training procedure for a ReLU NN. Using the equidistribution principle, we propose a two-level procedure for training the FKS by first solving the nonlinear problem of finding the optimal knot locations of the interpolating FKS. Determining the optimal knots then acts as a good starting point for training the weights of the FKS. The training of the FKS gives insights into how we can train a ReLU NN effectively to give an equally accurate approximation. More precisely, we combine the training of the ReLU NN with an equidistribution based loss to find the breakpoints of the ReLU functions, combined with preconditioning the ReLU NN approximation (to take an FKS form) to find the scalings of the ReLU functions, leads to a well-conditioned and reliable method of finding an accurate ReLU NN approximation to a target function. We test this method on a series or regular, singular, and rapidly varying target functions and obtain good results realising the expressivity of the network in this case.
Closing the ODE-SDE gap in score-based diffusion models through the Fokker-Planck equation
Nov 27, 2023
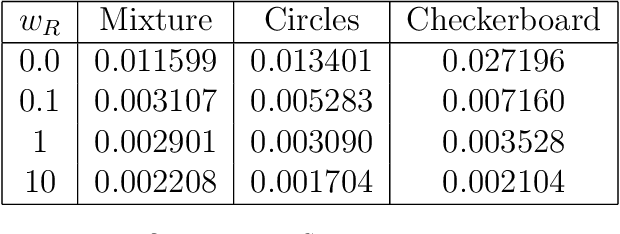

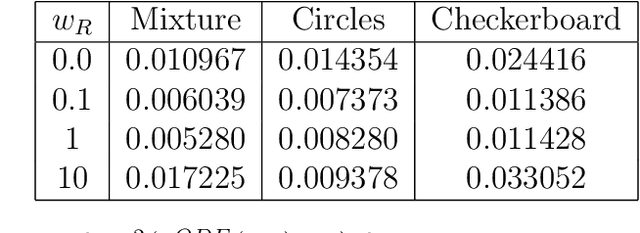
Score-based diffusion models have emerged as one of the most promising frameworks for deep generative modelling, due to their state-of-the art performance in many generation tasks while relying on mathematical foundations such as stochastic differential equations (SDEs) and ordinary differential equations (ODEs). Empirically, it has been reported that ODE based samples are inferior to SDE based samples. In this paper we rigorously describe the range of dynamics and approximations that arise when training score-based diffusion models, including the true SDE dynamics, the neural approximations, the various approximate particle dynamics that result, as well as their associated Fokker--Planck equations and the neural network approximations of these Fokker--Planck equations. We systematically analyse the difference between the ODE and SDE dynamics of score-based diffusion models, and link it to an associated Fokker--Planck equation. We derive a theoretical upper bound on the Wasserstein 2-distance between the ODE- and SDE-induced distributions in terms of a Fokker--Planck residual. We also show numerically that conventional score-based diffusion models can exhibit significant differences between ODE- and SDE-induced distributions which we demonstrate using explicit comparisons. Moreover, we show numerically that reducing the Fokker--Planck residual by adding it as an additional regularisation term leads to closing the gap between ODE- and SDE-induced distributions. Our experiments suggest that this regularisation can improve the distribution generated by the ODE, however that this can come at the cost of degraded SDE sample quality.