 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMBU: A Massive Multi-modal Biomedical Understanding Benchmark to Probe the Perception Capabilities of Vision-Language Models
Jun 04, 2026Vision and language models (VLMs) hold immense promise to transform biomedical imaging workflows, from detecting lesions in chest X-rays to profiling cellular features in microscopy. Realizing this potential, however, requires robust and fine-grained visual perception. Models need to correctly interpret subtle features in images, and they must do so across diverse biomedical modalities, scales, and contexts. Nevertheless, current benchmarks remain limited. To address these gaps, we introduce the Massive Multimodal Biomedical Understanding (MMBU) benchmark. It is the largest biomedical vision and language benchmark to date, covering 35 submodalities with rich structured metadata. It includes both open and closed versions of ungrounded classification, grounded classification, and object detection, enabling systematic evaluation of model performance across biological scales, clinical settings, and imaging modalities. Evaluating 15 open-weight and 2 frontier VLMs, we find that while medical adaptation provides measurable gains for some models, the high accuracy often reported on established benchmarks can mask deficiencies in visual perception and domain generalization.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
MedQ-Bench: Evaluating and Exploring Medical Image Quality Assessment Abilities in MLLMs
Oct 02, 2025
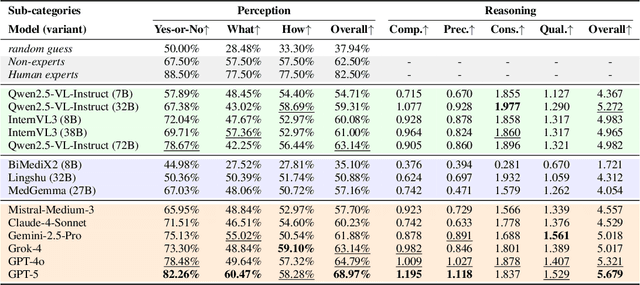
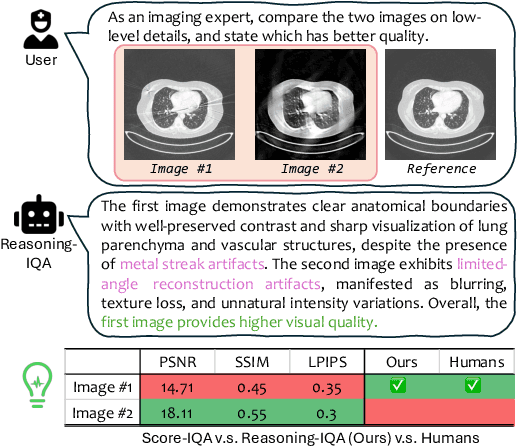

Medical Image Quality Assessment (IQA) serves as the first-mile safety gate for clinical AI, yet existing approaches remain constrained by scalar, score-based metrics and fail to reflect the descriptive, human-like reasoning process central to expert evaluation. To address this gap, we introduce MedQ-Bench, a comprehensive benchmark that establishes a perception-reasoning paradigm for language-based evaluation of medical image quality with Multi-modal Large Language Models (MLLMs). MedQ-Bench defines two complementary tasks: (1) MedQ-Perception, which probes low-level perceptual capability via human-curated questions on fundamental visual attributes; and (2) MedQ-Reasoning, encompassing both no-reference and comparison reasoning tasks, aligning model evaluation with human-like reasoning on image quality. The benchmark spans five imaging modalities and over forty quality attributes, totaling 2,600 perceptual queries and 708 reasoning assessments, covering diverse image sources including authentic clinical acquisitions, images with simulated degradations via physics-based reconstructions, and AI-generated images. To evaluate reasoning ability, we propose a multi-dimensional judging protocol that assesses model outputs along four complementary axes. We further conduct rigorous human-AI alignment validation by comparing LLM-based judgement with radiologists. Our evaluation of 14 state-of-the-art MLLMs demonstrates that models exhibit preliminary but unstable perceptual and reasoning skills, with insufficient accuracy for reliable clinical use. These findings highlight the need for targeted optimization of MLLMs in medical IQA. We hope that MedQ-Bench will catalyze further exploration and unlock the untapped potential of MLLMs for medical image quality evaluation.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Conservation-preserved Fourier Neural Operator through Adaptive Correction
May 30, 2025



Fourier Neural Operators (FNOs) have recently emerged as a promising and efficient approach for learning the numerical solutions to partial differential equations (PDEs) from data. However, standard FNO often fails to preserve key conservation laws, such as mass conservation, momentum conservation, norm conservation, etc., which are crucial for accurately modeling physical systems. Existing methods for incorporating these conservation laws into Fourier neural operators are achieved by designing related loss function or incorporating post-processing method at the training time. None of them can both exactly and adaptively correct the outputs to satisfy conservation laws, and our experiments show that these methods can lead to inferior performance while preserving conservation laws. In this work, we propose a novel adaptive correction approach to ensure the conservation of fundamental quantities. Our method introduces a learnable matrix to adaptively adjust the solution to satisfy the conservation law during training. It ensures that the outputs exactly satisfy the goal conservation law and allow for more flexibility and adaptivity for the model to correct the outputs. We theoretically show that applying our adaptive correction to an unconstrained FNO yields a solution with data loss no worse than that of the best conservation-satisfying FNO. We compare our approach with existing methods on a range of representative PDEs. Experiment results show that our method consistently outperform other methods.
Brain Foundation Models with Hypergraph Dynamic Adapter for Brain Disease Analysis
May 01, 2025Brain diseases, such as Alzheimer's disease and brain tumors, present profound challenges due to their complexity and societal impact. Recent advancements in brain foundation models have shown significant promise in addressing a range of brain-related tasks. However, current brain foundation models are limited by task and data homogeneity, restricted generalization beyond segmentation or classification, and inefficient adaptation to diverse clinical tasks. In this work, we propose SAM-Brain3D, a brain-specific foundation model trained on over 66,000 brain image-label pairs across 14 MRI sub-modalities, and Hypergraph Dynamic Adapter (HyDA), a lightweight adapter for efficient and effective downstream adaptation. SAM-Brain3D captures detailed brain-specific anatomical and modality priors for segmenting diverse brain targets and broader downstream tasks. HyDA leverages hypergraphs to fuse complementary multi-modal data and dynamically generate patient-specific convolutional kernels for multi-scale feature fusion and personalized patient-wise adaptation. Together, our framework excels across a broad spectrum of brain disease segmentation and classification tasks. Extensive experiments demonstrate that our method consistently outperforms existing state-of-the-art approaches, offering a new paradigm for brain disease analysis through multi-modal, multi-scale, and dynamic foundation modeling.
D2SA: Dual-Stage Distribution and Slice Adaptation for Efficient Test-Time Adaptation in MRI Reconstruction
Mar 25, 2025Variations in Magnetic resonance imaging (MRI) scanners and acquisition protocols cause distribution shifts that degrade reconstruction performance on unseen data. Test-time adaptation (TTA) offers a promising solution to address this discrepancies. However, previous single-shot TTA approaches are inefficient due to repeated training and suboptimal distributional models. Self-supervised learning methods are also limited by scarce date scenarios. To address these challenges, we propose a novel Dual-Stage Distribution and Slice Adaptation (D2SA) via MRI implicit neural representation (MR-INR) to improve MRI reconstruction performance and efficiency, which features two stages. In the first stage, an MR-INR branch performs patient-wise distribution adaptation by learning shared representations across slices and modelling patient-specific shifts with mean and variance adjustments. In the second stage, single-slice adaptation refines the output from frozen convolutional layers with a learnable anisotropic diffusion module, preventing over-smoothing and reducing computation. Experiments across four MRI distribution shifts demonstrate that our method can integrate well with various self-supervised learning (SSL) framework, improving performance and accelerating convergence under diverse conditions.
GMAI-VL & GMAI-VL-5.5M: A Large Vision-Language Model and A Comprehensive Multimodal Dataset Towards General Medical AI
Nov 21, 2024Despite significant advancements in general artificial intelligence, such as GPT-4, their effectiveness in the medical domain (general medical AI, GMAI) remains constrained due to the absence of specialized medical knowledge. To address this challenge, we present GMAI-VL-5.5M, a comprehensive multimodal medical dataset created by converting hundreds of specialized medical datasets into meticulously constructed image-text pairs. This dataset features comprehensive task coverage, diverse modalities, and high-quality image-text data. Building upon this multimodal dataset, we propose GMAI-VL, a general medical vision-language model with a progressively three-stage training strategy. This approach significantly enhances the model's ability by integrating visual and textual information, thereby improving its ability to process multimodal data and support accurate diagnosis and clinical decision-making. Experimental evaluations demonstrate that GMAI-VL achieves state-of-the-art results across a wide range of multimodal medical tasks, such as visual question answering and medical image diagnosis. Our contributions include the development of the GMAI-VL-5.5M dataset, the introduction of the GMAI-VL model, and the establishment of new benchmarks in multiple medical domains. Code and dataset will be released at https://github.com/uni-medical/GMAI-VL.
SegBook: A Simple Baseline and Cookbook for Volumetric Medical Image Segmentation
Nov 21, 2024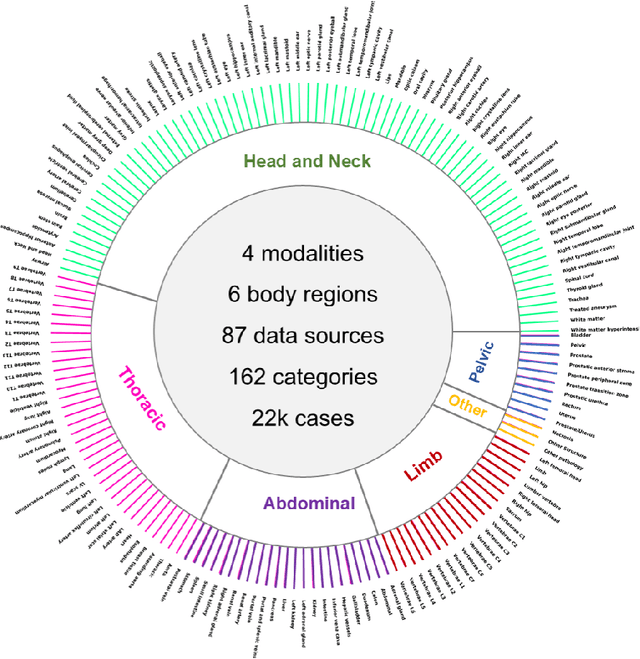

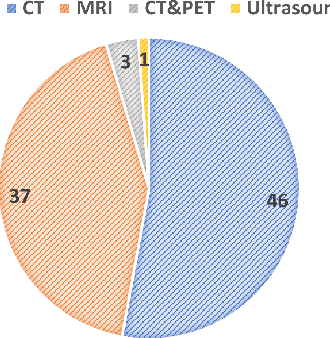
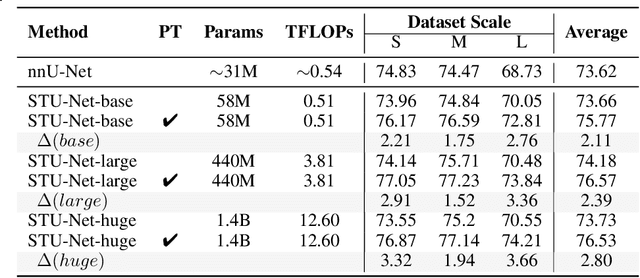
Computed Tomography (CT) is one of the most popular modalities for medical imaging. By far, CT images have contributed to the largest publicly available datasets for volumetric medical segmentation tasks, covering full-body anatomical structures. Large amounts of full-body CT images provide the opportunity to pre-train powerful models, e.g., STU-Net pre-trained in a supervised fashion, to segment numerous anatomical structures. However, it remains unclear in which conditions these pre-trained models can be transferred to various downstream medical segmentation tasks, particularly segmenting the other modalities and diverse targets. To address this problem, a large-scale benchmark for comprehensive evaluation is crucial for finding these conditions. Thus, we collected 87 public datasets varying in modality, target, and sample size to evaluate the transfer ability of full-body CT pre-trained models. We then employed a representative model, STU-Net with multiple model scales, to conduct transfer learning across modalities and targets. Our experimental results show that (1) there may be a bottleneck effect concerning the dataset size in fine-tuning, with more improvement on both small- and large-scale datasets than medium-size ones. (2) Models pre-trained on full-body CT demonstrate effective modality transfer, adapting well to other modalities such as MRI. (3) Pre-training on the full-body CT not only supports strong performance in structure detection but also shows efficacy in lesion detection, showcasing adaptability across target tasks. We hope that this large-scale open evaluation of transfer learning can direct future research in volumetric medical image segmentation.
Where Do We Stand with Implicit Neural Representations? A Technical and Performance Survey
Nov 06, 2024



Implicit Neural Representations (INRs) have emerged as a paradigm in knowledge representation, offering exceptional flexibility and performance across a diverse range of applications. INRs leverage multilayer perceptrons (MLPs) to model data as continuous implicit functions, providing critical advantages such as resolution independence, memory efficiency, and generalisation beyond discretised data structures. Their ability to solve complex inverse problems makes them particularly effective for tasks including audio reconstruction, image representation, 3D object reconstruction, and high-dimensional data synthesis. This survey provides a comprehensive review of state-of-the-art INR methods, introducing a clear taxonomy that categorises them into four key areas: activation functions, position encoding, combined strategies, and network structure optimisation. We rigorously analyse their critical properties, such as full differentiability, smoothness, compactness, and adaptability to varying resolutions while also examining their strengths and limitations in addressing locality biases and capturing fine details. Our experimental comparison offers new insights into the trade-offs between different approaches, showcasing the capabilities and challenges of the latest INR techniques across various tasks. In addition to identifying areas where current methods excel, we highlight key limitations and potential avenues for improvement, such as developing more expressive activation functions, enhancing positional encoding mechanisms, and improving scalability for complex, high-dimensional data. This survey serves as a roadmap for researchers, offering practical guidance for future exploration in the field of INRs. We aim to foster new methodologies by outlining promising research directions for INRs and applications.