 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAP-Diff: Multi-Anchor Guided Diffusion for Progressive 3D Whole-Body Low-Dose PET Denoising
Mar 02, 2026Low-dose Positron Emission Tomography (PET) reduces radiation exposure but suffers from severe noise and quantitative degradation. Diffusion-based denoising models achieve strong final reconstructions, yet their reverse trajectories are typically unconstrained and not aligned with the progressive nature of PET dose formation. We propose MAP-Diff, a multi-anchor guided diffusion framework for progressive 3D whole-body PET denoising. MAP-Diff introduces clinically observed intermediate-dose scans as trajectory anchors and enforces timestep-dependent supervision to regularize the reverse process toward dose-aligned intermediate states. Anchor timesteps are calibrated via degradation matching between simulated diffusion corruption and real multi-dose PET pairs, and a timestep-weighted anchor loss stabilizes stage-wise learning. At inference, the model requires only ultra-low-dose input while enabling progressive, dose-consistent intermediate restoration. Experiments on internal (Siemens Biograph Vision Quadra) and cross-scanner (United Imaging uEXPLORER) datasets show consistent improvements over strong CNN-, Transformer-, GAN-, and diffusion-based baselines. On the internal dataset, MAP-Diff improves PSNR from 42.48 dB to 43.71 dB (+1.23 dB), increases SSIM to 0.986, and reduces NMAE from 0.115 to 0.103 (-0.012) compared to 3D DDPM. Performance gains generalize across scanners, achieving 34.42 dB PSNR and 0.141 NMAE on the external cohort, outperforming all competing methods.
3D Wavelet-Based Structural Priors for Controlled Diffusion in Whole-Body Low-Dose PET Denoising
Jan 11, 2026Low-dose Positron Emission Tomography (PET) imaging reduces patient radiation exposure but suffers from increased noise that degrades image quality and diagnostic reliability. Although diffusion models have demonstrated strong denoising capability, their stochastic nature makes it challenging to enforce anatomically consistent structures, particularly in low signal-to-noise regimes and volumetric whole-body imaging. We propose Wavelet-Conditioned ControlNet (WCC-Net), a fully 3D diffusion-based framework that introduces explicit frequency-domain structural priors via wavelet representations to guide volumetric PET denoising. By injecting wavelet-based structural guidance into a frozen pretrained diffusion backbone through a lightweight control branch, WCC-Net decouples anatomical structure from noise while preserving generative expressiveness and 3D structural continuity. Extensive experiments demonstrate that WCC-Net consistently outperforms CNN-, GAN-, and diffusion-based baselines. On the internal 1/20-dose test set, WCC-Net improves PSNR by +1.21 dB and SSIM by +0.008 over a strong diffusion baseline, while reducing structural distortion (GMSD) and intensity error (NMAE). Moreover, WCC-Net generalizes robustly to unseen dose levels (1/50 and 1/4), achieving superior quantitative performance and improved volumetric anatomical consistency.
Bridging Annotation Gaps: Transferring Labels to Align Object Detection Datasets
Jun 06, 2025Combining multiple object detection datasets offers a path to improved generalisation but is hindered by inconsistencies in class semantics and bounding box annotations. Some methods to address this assume shared label taxonomies and address only spatial inconsistencies; others require manual relabelling, or produce a unified label space, which may be unsuitable when a fixed target label space is required. We propose Label-Aligned Transfer (LAT), a label transfer framework that systematically projects annotations from diverse source datasets into the label space of a target dataset. LAT begins by training dataset-specific detectors to generate pseudo-labels, which are then combined with ground-truth annotations via a Privileged Proposal Generator (PPG) that replaces the region proposal network in two-stage detectors. To further refine region features, a Semantic Feature Fusion (SFF) module injects class-aware context and features from overlapping proposals using a confidence-weighted attention mechanism. This pipeline preserves dataset-specific annotation granularity while enabling many-to-one label space transfer across heterogeneous datasets, resulting in a semantically and spatially aligned representation suitable for training a downstream detector. LAT thus jointly addresses both class-level misalignments and bounding box inconsistencies without relying on shared label spaces or manual annotations. Across multiple benchmarks, LAT demonstrates consistent improvements in target-domain detection performance, achieving gains of up to +4.8AP over semi-supervised baselines.
Contrastive Learning with Dynamic Localized Repulsion for Brain Age Prediction on 3D Stiffness Maps
Aug 01, 2024In the field of neuroimaging, accurate brain age prediction is pivotal for uncovering the complexities of brain aging and pinpointing early indicators of neurodegenerative conditions. Recent advancements in self-supervised learning, particularly in contrastive learning, have demonstrated greater robustness when dealing with complex datasets. However, current approaches often fall short in generalizing across non-uniformly distributed data, prevalent in medical imaging scenarios. To bridge this gap, we introduce a novel contrastive loss that adapts dynamically during the training process, focusing on the localized neighborhoods of samples. Moreover, we expand beyond traditional structural features by incorporating brain stiffness, a mechanical property previously underexplored yet promising due to its sensitivity to age-related changes. This work presents the first application of self-supervised learning to brain mechanical properties, using compiled stiffness maps from various clinical studies to predict brain age. Our approach, featuring dynamic localized loss, consistently outperforms existing state-of-the-art methods, demonstrating superior performance and laying the way for new directions in brain aging research.
HAMLET: Graph Transformer Neural Operator for Partial Differential Equations
Feb 05, 2024We present a novel graph transformer framework, HAMLET, designed to address the challenges in solving partial differential equations (PDEs) using neural networks. The framework uses graph transformers with modular input encoders to directly incorporate differential equation information into the solution process. This modularity enhances parameter correspondence control, making HAMLET adaptable to PDEs of arbitrary geometries and varied input formats. Notably, HAMLET scales effectively with increasing data complexity and noise, showcasing its robustness. HAMLET is not just tailored to a single type of physical simulation, but can be applied across various domains. Moreover, it boosts model resilience and performance, especially in scenarios with limited data. We demonstrate, through extensive experiments, that our framework is capable of outperforming current techniques for PDEs.
TrafficMOT: A Challenging Dataset for Multi-Object Tracking in Complex Traffic Scenarios
Nov 30, 2023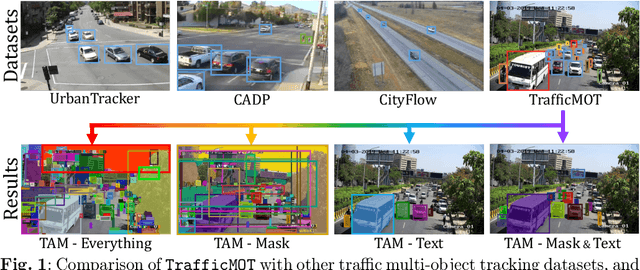
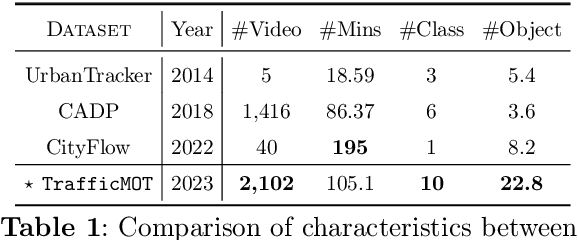

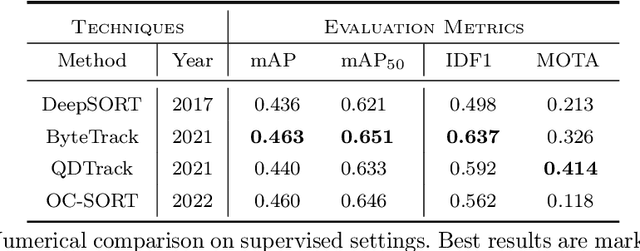
Multi-object tracking in traffic videos is a crucial research area, offering immense potential for enhancing traffic monitoring accuracy and promoting road safety measures through the utilisation of advanced machine learning algorithms. However, existing datasets for multi-object tracking in traffic videos often feature limited instances or focus on single classes, which cannot well simulate the challenges encountered in complex traffic scenarios. To address this gap, we introduce TrafficMOT, an extensive dataset designed to encompass diverse traffic situations with complex scenarios. To validate the complexity and challenges presented by TrafficMOT, we conducted comprehensive empirical studies using three different settings: fully-supervised, semi-supervised, and a recent powerful zero-shot foundation model Tracking Anything Model (TAM). The experimental results highlight the inherent complexity of this dataset, emphasising its value in driving advancements in the field of traffic monitoring and multi-object tracking.
CDiffMR: Can We Replace the Gaussian Noise with K-Space Undersampling for Fast MRI?
Jun 25, 2023Deep learning has shown the capability to substantially accelerate MRI reconstruction while acquiring fewer measurements. Recently, diffusion models have gained burgeoning interests as a novel group of deep learning-based generative methods. These methods seek to sample data points that belong to a target distribution from a Gaussian distribution, which has been successfully extended to MRI reconstruction. In this work, we proposed a Cold Diffusion-based MRI reconstruction method called CDiffMR. Different from conventional diffusion models, the degradation operation of our CDiffMR is based on \textit{k}-space undersampling instead of adding Gaussian noise, and the restoration network is trained to harness a de-aliaseing function. We also design starting point and data consistency conditioning strategies to guide and accelerate the reverse process. More intriguingly, the pre-trained CDiffMR model can be reused for reconstruction tasks with different undersampling rates. We demonstrated, through extensive numerical and visual experiments, that the proposed CDiffMR can achieve comparable or even superior reconstruction results than state-of-the-art models. Compared to the diffusion model-based counterpart, CDiffMR reaches readily competing results using only $1.6 \sim 3.4\%$ for inference time. The code is publicly available at https://github.com/ayanglab/CDiffMR.
TFPnP: Tuning-free Plug-and-Play Proximal Algorithm with Applications to Inverse Imaging Problems
Dec 11, 2020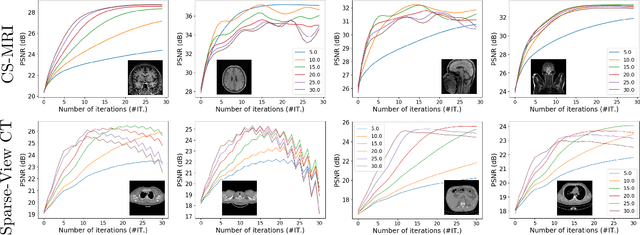
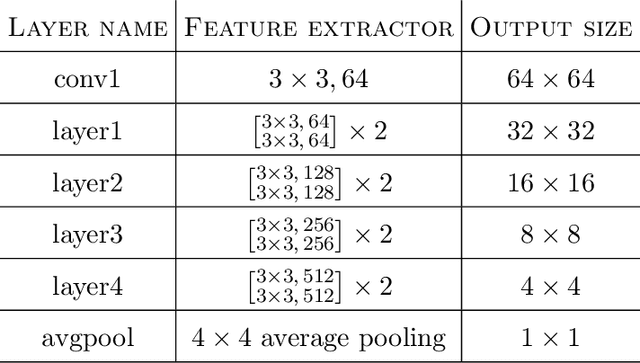
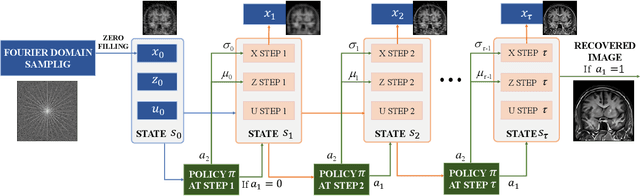
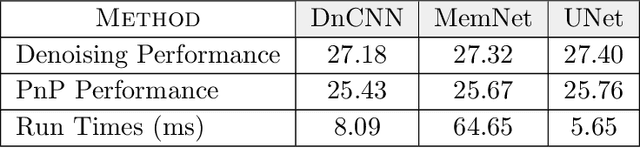
Plug-and-Play (PnP) is a non-convex framework that combines proximal algorithms, for example alternating direction method of multipliers (ADMM), with advanced denoiser priors. Over the past few years, great empirical success has been obtained by PnP algorithms, especially for the ones integrated with deep learning-based denoisers. However, a crucial issue of PnP approaches is the need of manual parameter tweaking. As it is essential to obtain high-quality results across the high discrepancy in terms of imaging conditions and varying scene content. In this work, we present a tuning-free PnP proximal algorithm, which can automatically determine the internal parameters including the penalty parameter, the denoising strength and the termination time. A core part of our approach is to develop a policy network for automatic search of parameters, which can be effectively learned via mixed model-free and model-based deep reinforcement learning. We demonstrate, through a set of numerical and visual experiments, that the learned policy can customize different parameters for different states, and often more efficient and effective than existing handcrafted criteria. Moreover, we discuss the practical considerations of the plugged denoisers, which together with our learned policy yield to state-of-the-art results. This is prevalent on both linear and nonlinear exemplary inverse imaging problems, and in particular, we show promising results on compressed sensing MRI, sparse-view CT and phase retrieval.
A Three-Stage Self-Training Framework for Semi-Supervised Semantic Segmentation
Dec 01, 2020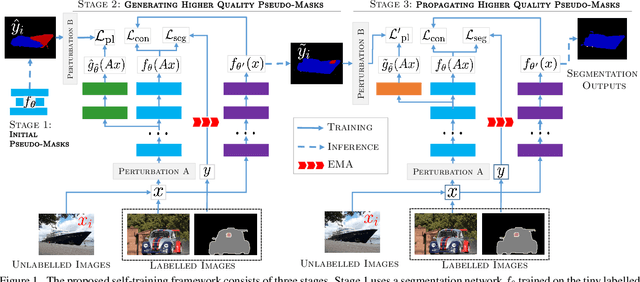
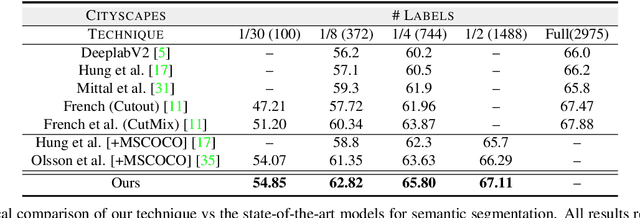
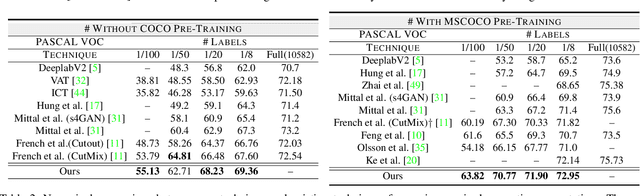

Semantic segmentation has been widely investigated in the community, in which the state of the art techniques are based on supervised models. Those models have reported unprecedented performance at the cost of requiring a large set of high quality segmentation masks. To obtain such annotations is highly expensive and time consuming, in particular, in semantic segmentation where pixel-level annotations are required. In this work, we address this problem by proposing a holistic solution framed as a three-stage self-training framework for semi-supervised semantic segmentation. The key idea of our technique is the extraction of the pseudo-masks statistical information to decrease uncertainty in the predicted probability whilst enforcing segmentation consistency in a multi-task fashion. We achieve this through a three-stage solution. Firstly, we train a segmentation network to produce rough pseudo-masks which predicted probability is highly uncertain. Secondly, we then decrease the uncertainty of the pseudo-masks using a multi-task model that enforces consistency whilst exploiting the rich statistical information of the data. We compare our approach with existing methods for semi-supervised semantic segmentation and demonstrate its state-of-the-art performance with extensive experiments.
Tuning-free Plug-and-Play Proximal Algorithm for Inverse Imaging Problems
Feb 22, 2020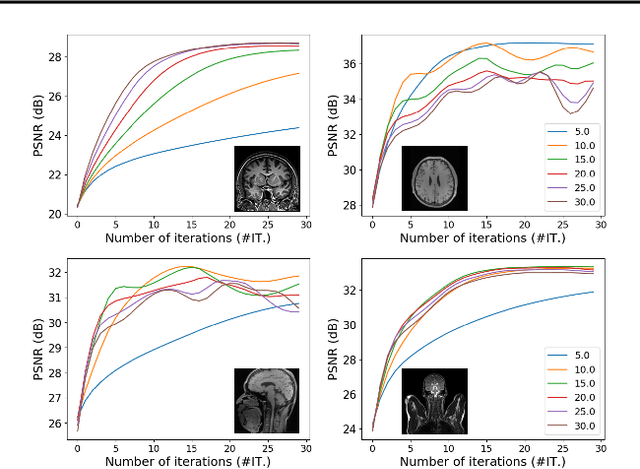
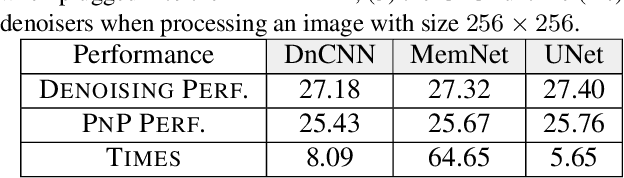
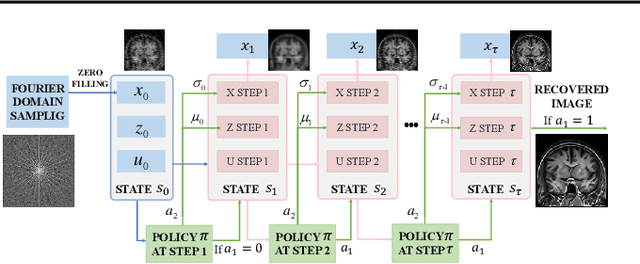
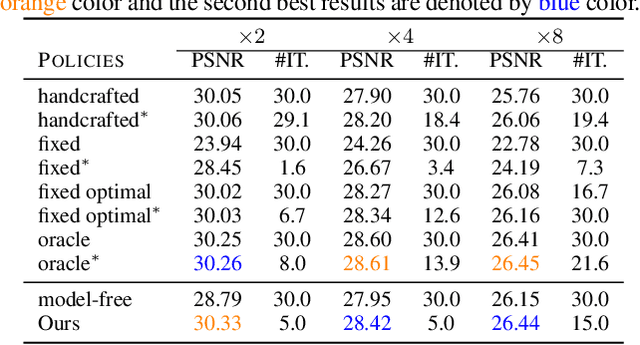
Plug-and-play (PnP) is a non-convex framework that combines ADMM or other proximal algorithms with advanced denoiser priors. Recently, PnP has achieved great empirical success, especially with the integration of deep learning-based denoisers. However, a key problem of PnP based approaches is that they require manual parameter tweaking. It is necessary to obtain high-quality results across the high discrepancy in terms of imaging conditions and varying scene content. In this work, we present a tuning-free PnP proximal algorithm, which can automatically determine the internal parameters including the penalty parameter, the denoising strength and the terminal time. A key part of our approach is to develop a policy network for automatic search of parameters, which can be effectively learned via mixed model-free and model-based deep reinforcement learning. We demonstrate, through numerical and visual experiments, that the learned policy can customize different parameters for different states, and often more efficient and effective than existing handcrafted criteria. Moreover, we discuss the practical considerations of the plugged denoisers, which together with our learned policy yield state-of-the-art results. This is prevalent on both linear and nonlinear exemplary inverse imaging problems, and in particular, we show promising results on Compressed Sensing MRI and phase retrieval.