 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNF-ULA: Langevin Monte Carlo with Normalizing Flow Prior for Imaging Inverse Problems
Apr 17, 2023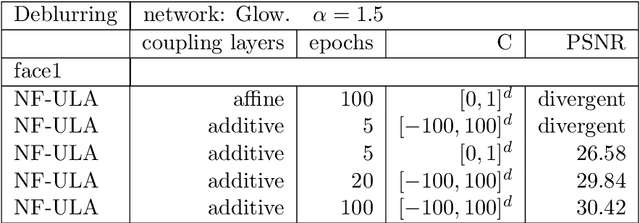

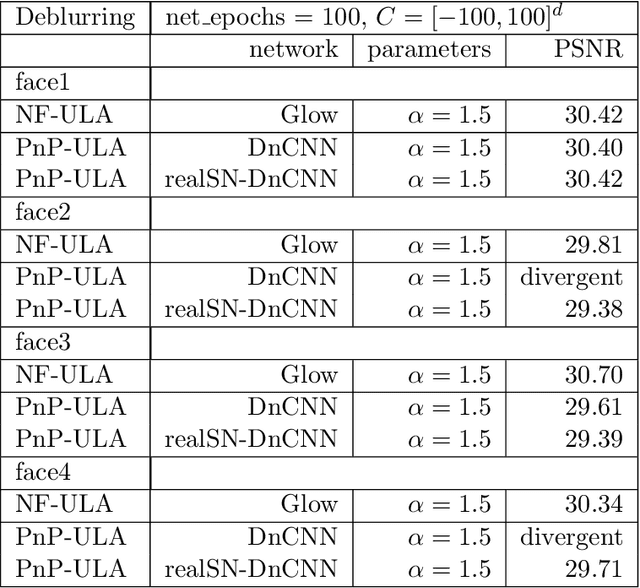
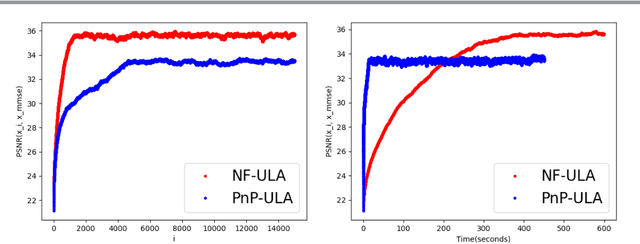
Bayesian methods for solving inverse problems are a powerful alternative to classical methods since the Bayesian approach gives a probabilistic description of the problems and offers the ability to quantify the uncertainty in the solution. Meanwhile, solving inverse problems by data-driven techniques also proves to be successful, due to the increasing representation ability of data-based models. In this work, we try to incorporate the data-based models into a class of Langevin-based sampling algorithms in Bayesian inference. Loosely speaking, we introduce NF-ULA (Unadjusted Langevin algorithms by Normalizing Flows), which involves learning a normalizing flow as the prior. In particular, our algorithm only requires a pre-trained normalizing flow, which is independent of the considered inverse problem and the forward operator. We perform theoretical analysis by investigating the well-posedness of the Bayesian solution and the non-asymptotic convergence of the NF-ULA algorithm. The efficacy of the proposed NF-ULA algorithm is demonstrated in various imaging problems, including image deblurring, image inpainting, and limited-angle X-ray computed tomography (CT) reconstruction.
CAFLOW: Conditional Autoregressive Flows
Jun 04, 2021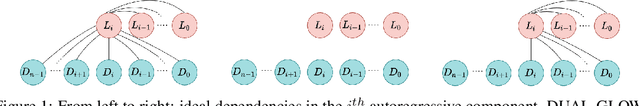
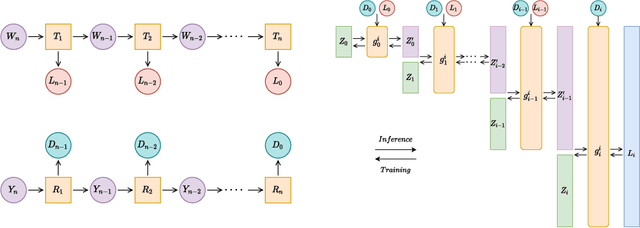


We introduce CAFLOW, a new diverse image-to-image translation model that simultaneously leverages the power of auto-regressive modeling and the modeling efficiency of conditional normalizing flows. We transform the conditioning image into a sequence of latent encodings using a multi-scale normalizing flow and repeat the process for the conditioned image. We model the conditional distribution of the latent encodings by modeling the auto-regressive distributions with an efficient multi-scale normalizing flow, where each conditioning factor affects image synthesis at its respective resolution scale. Our proposed framework performs well on a range of image-to-image translation tasks. It outperforms former designs of conditional flows because of its expressive auto-regressive structure.
Two Cycle Learning: Clustering Based Regularisation for Deep Semi-Supervised Classification
Jan 15, 2020



This works addresses the challenge of classification with minimal annotations. Obtaining annotated data is time consuming, expensive and can require expert knowledge. As a result, there is an acceleration towards semi-supervised learning (SSL) approaches which utilise large amounts of unlabelled data to improve classification performance. The vast majority of SSL approaches have focused on implementing the \textit{low-density separation assumption}, in which the idea is that decision boundaries should lie in low density regions. However, they have implemented this assumption by treating the dataset as a set of individual attributes rather than as a global structure, which limits the overall performance of the classifier. Therefore, in this work, we go beyond this implementation and propose a novel SSL framework called two-cycle learning. For the first cycle, we use clustering based regularisation that allows for improved decision boundaries as well as features that generalises well. The second cycle is set as a graph based SSL that take advantages of the richer discriminative features of the first cycle to significantly boost the accuracy of generated pseudo-labels. We evaluate our two-cycle learning method extensively across multiple datasets, outperforming current approaches.