 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilevel Learning via Inexact Stochastic Gradient Descent
Nov 10, 2025Bilevel optimization is a central tool in machine learning for high-dimensional hyperparameter tuning. Its applications are vast; for instance, in imaging it can be used for learning data-adaptive regularizers and optimizing forward operators in variational regularization. These problems are large in many ways: a lot of data is usually available to train a large number of parameters, calling for stochastic gradient-based algorithms. However, exact gradients with respect to parameters (so-called hypergradients) are not available, and their precision is usually linearly related to computational cost. Hence, algorithms must solve the problem efficiently without unnecessary precision. The design of such methods is still not fully understood, especially regarding how accuracy requirements and step size schedules affect theoretical guarantees and practical performance. Existing approaches introduce stochasticity at both the upper level (e.g., in sampling or mini-batch estimates) and the lower level (e.g., in solving the inner problem) to improve generalization, but they typically fix the number of lower-level iterations, which conflicts with asymptotic convergence assumptions. In this work, we advance the theory of inexact stochastic bilevel optimization. We prove convergence and establish rates under decaying accuracy and step size schedules, showing that with optimal configurations convergence occurs at an $\mathcal{O}(k^{-1/4})$ rate in expectation. Experiments on image denoising and inpainting with convex ridge regularizers and input-convex networks confirm our analysis: decreasing step sizes improve stability, accuracy scheduling is more critical than step size strategy, and adaptive preconditioning (e.g., Adam) further boosts performance. These results bridge theory and practice, providing convergence guarantees and practical guidance for large-scale imaging problems.
From Image Denoisers to Regularizing Imaging Inverse Problems: An Overview
Sep 03, 2025Inverse problems lie at the heart of modern imaging science, with broad applications in areas such as medical imaging, remote sensing, and microscopy. Recent years have witnessed a paradigm shift in solving imaging inverse problems, where data-driven regularizers are used increasingly, leading to remarkably high-fidelity reconstruction. A particularly notable approach for data-driven regularization is to use learned image denoisers as implicit priors in iterative image reconstruction algorithms. This survey presents a comprehensive overview of this powerful and emerging class of algorithms, commonly referred to as plug-and-play (PnP) methods. We begin by providing a brief background on image denoising and inverse problems, followed by a short review of traditional regularization strategies. We then explore how proximal splitting algorithms, such as the alternating direction method of multipliers (ADMM) and proximal gradient descent (PGD), can naturally accommodate learned denoisers in place of proximal operators, and under what conditions such replacements preserve convergence. The role of Tweedie's formula in connecting optimal Gaussian denoisers and score estimation is discussed, which lays the foundation for regularization-by-denoising (RED) and more recent diffusion-based posterior sampling methods. We discuss theoretical advances regarding the convergence of PnP algorithms, both within the RED and proximal settings, emphasizing the structural assumptions that the denoiser must satisfy for convergence, such as non-expansiveness, Lipschitz continuity, and local homogeneity. We also address practical considerations in algorithm design, including choices of denoiser architecture and acceleration strategies.
Bilevel Learning with Inexact Stochastic Gradients
Dec 16, 2024Bilevel learning has gained prominence in machine learning, inverse problems, and imaging applications, including hyperparameter optimization, learning data-adaptive regularizers, and optimizing forward operators. The large-scale nature of these problems has led to the development of inexact and computationally efficient methods. Existing adaptive methods predominantly rely on deterministic formulations, while stochastic approaches often adopt a doubly-stochastic framework with impractical variance assumptions, enforces a fixed number of lower-level iterations, and requires extensive tuning. In this work, we focus on bilevel learning with strongly convex lower-level problems and a nonconvex sum-of-functions in the upper-level. Stochasticity arises from data sampling in the upper-level which leads to inexact stochastic hypergradients. We establish their connection to state-of-the-art stochastic optimization theory for nonconvex objectives. Furthermore, we prove the convergence of inexact stochastic bilevel optimization under mild assumptions. Our empirical results highlight significant speed-ups and improved generalization in imaging tasks such as image denoising and deblurring in comparison with adaptive deterministic bilevel methods.
A Primal-dual algorithm for image reconstruction with ICNNs
Oct 16, 2024We address the optimization problem in a data-driven variational reconstruction framework, where the regularizer is parameterized by an input-convex neural network (ICNN). While gradient-based methods are commonly used to solve such problems, they struggle to effectively handle non-smoothness which often leads to slow convergence. Moreover, the nested structure of the neural network complicates the application of standard non-smooth optimization techniques, such as proximal algorithms. To overcome these challenges, we reformulate the problem and eliminate the network's nested structure. By relating this reformulation to epigraphical projections of the activation functions, we transform the problem into a convex optimization problem that can be efficiently solved using a primal-dual algorithm. We also prove that this reformulation is equivalent to the original variational problem. Through experiments on several imaging tasks, we demonstrate that the proposed approach outperforms subgradient methods in terms of both speed and stability.
Blessing of Dimensionality for Approximating Sobolev Classes on Manifolds
Aug 13, 2024The manifold hypothesis says that natural high-dimensional data is actually supported on or around a low-dimensional manifold. Recent success of statistical and learning-based methods empirically supports this hypothesis, due to outperforming classical statistical intuition in very high dimensions. A natural step for analysis is thus to assume the manifold hypothesis and derive bounds that are independent of any embedding space. Theoretical implications in this direction have recently been explored in terms of generalization of ReLU networks and convergence of Langevin methods. We complement existing results by providing theoretical statistical complexity results, which directly relates to generalization properties. In particular, we demonstrate that the statistical complexity required to approximate a class of bounded Sobolev functions on a compact manifold is bounded from below, and moreover that this bound is dependent only on the intrinsic properties of the manifold. These provide complementary bounds for existing approximation results for ReLU networks on manifolds, which give upper bounds on generalization capacity.
Unsupervised Training of Convex Regularizers using Maximum Likelihood Estimation
Apr 08, 2024



Unsupervised learning is a training approach in the situation where ground truth data is unavailable, such as inverse imaging problems. We present an unsupervised Bayesian training approach to learning convex neural network regularizers using a fixed noisy dataset, based on a dual Markov chain estimation method. Compared to classical supervised adversarial regularization methods, where there is access to both clean images as well as unlimited to noisy copies, we demonstrate close performance on natural image Gaussian deconvolution and Poisson denoising tasks.
Weakly Convex Regularisers for Inverse Problems: Convergence of Critical Points and Primal-Dual Optimisation
Feb 01, 2024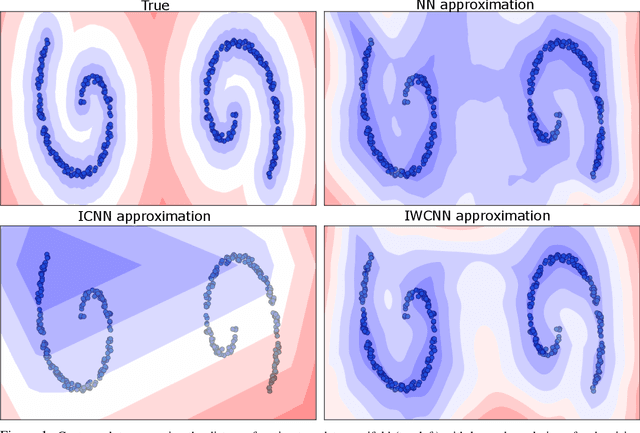
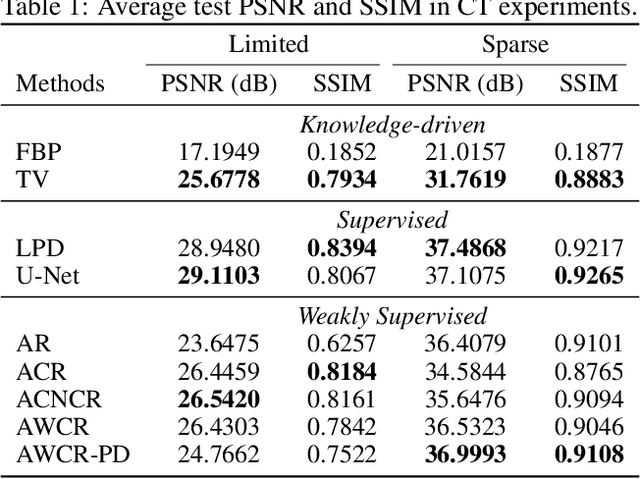
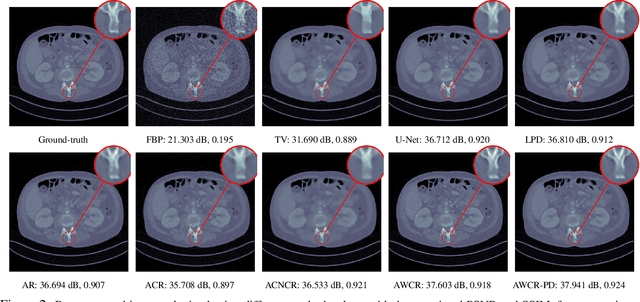
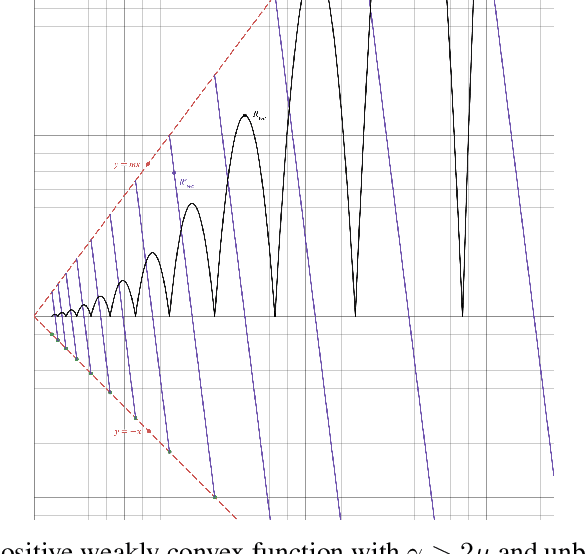
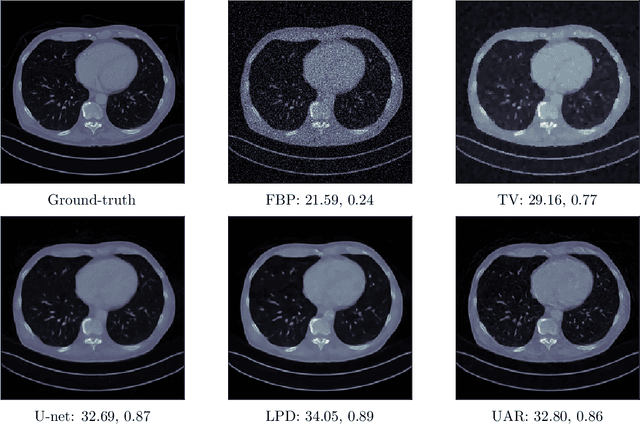
Variational regularisation is the primary method for solving inverse problems, and recently there has been considerable work leveraging deeply learned regularisation for enhanced performance. However, few results exist addressing the convergence of such regularisation, particularly within the context of critical points as opposed to global minima. In this paper, we present a generalised formulation of convergent regularisation in terms of critical points, and show that this is achieved by a class of weakly convex regularisers. We prove convergence of the primal-dual hybrid gradient method for the associated variational problem, and, given a Kurdyka-Lojasiewicz condition, an $\mathcal{O}(\log{k}/k)$ ergodic convergence rate. Finally, applying this theory to learned regularisation, we prove universal approximation for input weakly convex neural networks (IWCNN), and show empirically that IWCNNs can lead to improved performance of learned adversarial regularisers for computed tomography (CT) reconstruction.
Unsupervised approaches based on optimal transport and convex analysis for inverse problems in imaging
Nov 29, 2023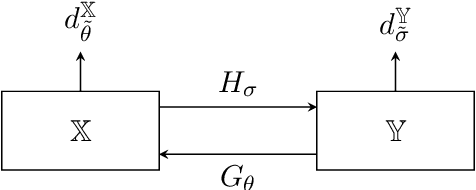
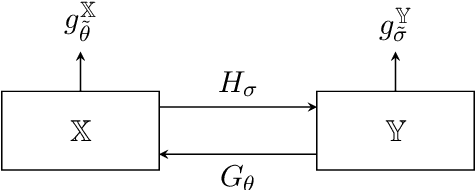
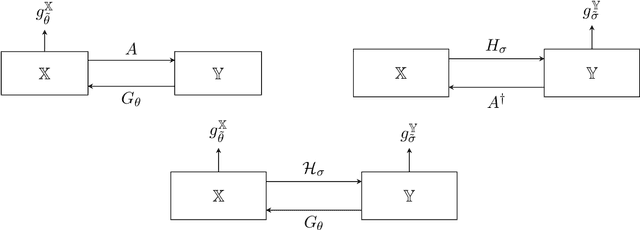
Unsupervised deep learning approaches have recently become one of the crucial research areas in imaging owing to their ability to learn expressive and powerful reconstruction operators even when paired high-quality training data is scarcely available. In this chapter, we review theoretically principled unsupervised learning schemes for solving imaging inverse problems, with a particular focus on methods rooted in optimal transport and convex analysis. We begin by reviewing the optimal transport-based unsupervised approaches such as the cycle-consistency-based models and learned adversarial regularization methods, which have clear probabilistic interpretations. Subsequently, we give an overview of a recent line of works on provably convergent learned optimization algorithms applied to accelerate the solution of imaging inverse problems, alongside their dedicated unsupervised training schemes. We also survey a number of provably convergent plug-and-play algorithms (based on gradient-step deep denoisers), which are among the most important and widely applied unsupervised approaches for imaging problems. At the end of this survey, we provide an overview of a few related unsupervised learning frameworks that complement our focused schemes. Together with a detailed survey, we provide an overview of the key mathematical results that underlie the methods reviewed in the chapter to keep our discussion self-contained.
Provably Convergent Data-Driven Convex-Nonconvex Regularization
Oct 09, 2023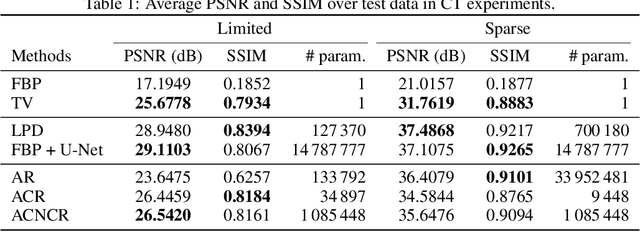
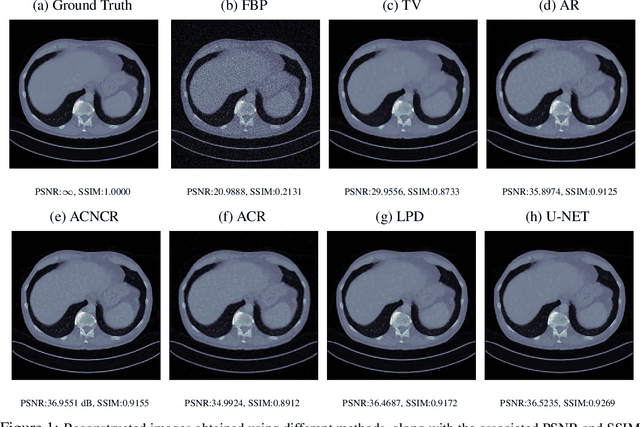
An emerging new paradigm for solving inverse problems is via the use of deep learning to learn a regularizer from data. This leads to high-quality results, but often at the cost of provable guarantees. In this work, we show how well-posedness and convergent regularization arises within the convex-nonconvex (CNC) framework for inverse problems. We introduce a novel input weakly convex neural network (IWCNN) construction to adapt the method of learned adversarial regularization to the CNC framework. Empirically we show that our method overcomes numerical issues of previous adversarial methods.
Dynamic Bilevel Learning with Inexact Line Search
Aug 19, 2023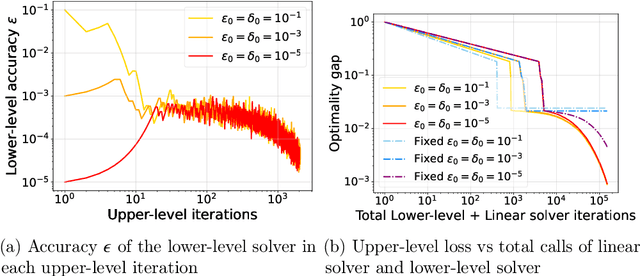
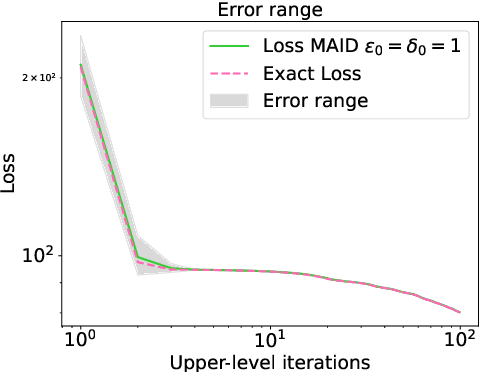
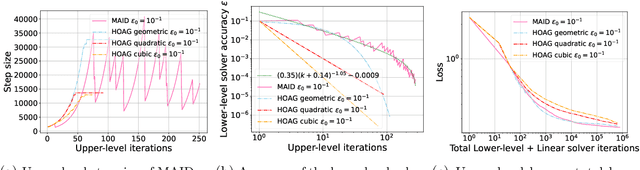
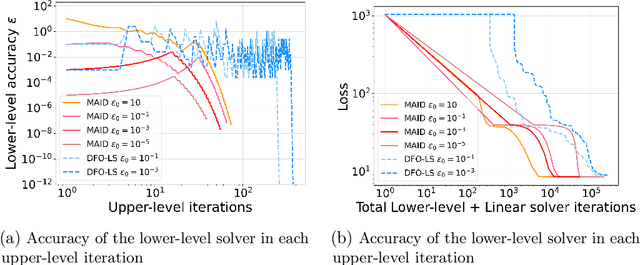
In various domains within imaging and data science, particularly when addressing tasks modeled utilizing the variational regularization approach, manually configuring regularization parameters presents a formidable challenge. The difficulty intensifies when employing regularizers involving a large number of hyperparameters. To overcome this challenge, bilevel learning is employed to learn suitable hyperparameters. However, due to the use of numerical solvers, the exact gradient with respect to the hyperparameters is unattainable, necessitating the use of methods relying on approximate gradients. State-of-the-art inexact methods a priori select a decreasing summable sequence of the required accuracy and only assure convergence given a sufficiently small fixed step size. Despite this, challenges persist in determining the Lipschitz constant of the hypergradient and identifying an appropriate fixed step size. Conversely, computing exact function values is not feasible, impeding the use of line search. In this work, we introduce a provably convergent inexact backtracking line search involving inexact function evaluations and hypergradients. We show convergence to a stationary point of the loss with respect to hyperparameters. Additionally, we propose an algorithm to determine the required accuracy dynamically. Our numerical experiments demonstrate the efficiency and feasibility of our approach for hyperparameter estimation in variational regularization problems, alongside its robustness in terms of the initial accuracy and step size choices.