 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable neural networks and connections to continuous dynamical systems
Oct 25, 2025The existence of instabilities, for example in the form of adversarial examples, has given rise to a highly active area of research concerning itself with understanding and enhancing the stability of neural networks. We focus on a popular branch within this area which draws on connections to continuous dynamical systems and optimal control, giving a bird's eye view of this area. We identify and describe the fundamental concepts that underlie much of the existing work in this area. Following this, we go into more detail on a specific approach to designing stable neural networks, developing the theoretical background and giving a description of how these networks can be implemented. We provide code that implements the approach that can be adapted and extended by the reader. The code further includes a notebook with a fleshed-out toy example on adversarial robustness of image classification that can be run without heavy requirements on the reader's computer. We finish by discussing this toy example so that the reader can interactively follow along on their computer. This work will be included as a chapter of a book on scientific machine learning, which is currently under revision and aimed at students.
Enhanced Denoising and Convergent Regularisation Using Tweedie Scaling
Mar 07, 2025The inherent ill-posed nature of image reconstruction problems, due to limitations in the physical acquisition process, is typically addressed by introducing a regularisation term that incorporates prior knowledge about the underlying image. The iterative framework of Plug-and-Play methods, specifically designed for tackling such inverse problems, achieves state-of-the-art performance by replacing the regularisation with a generic denoiser, which may be parametrised by a neural network architecture. However, these deep learning approaches suffer from a critical limitation: the absence of a control parameter to modulate the regularisation strength, which complicates the design of a convergent regularisation. To address this issue, this work introduces a novel scaling method that explicitly integrates and adjusts the strength of regularisation. The scaling parameter enhances interpretability by reflecting the quality of the denoiser's learning process, and also systematically improves its optimisation. Furthermore, the proposed approach ensures that the resulting family of regularisations is provably stable and convergent.
Symplectic Neural Flows for Modeling and Discovery
Dec 21, 2024Hamilton's equations are fundamental for modeling complex physical systems, where preserving key properties such as energy and momentum is crucial for reliable long-term simulations. Geometric integrators are widely used for this purpose, but neural network-based methods that incorporate these principles remain underexplored. This work introduces SympFlow, a time-dependent symplectic neural network designed using parameterized Hamiltonian flow maps. This design allows for backward error analysis and ensures the preservation of the symplectic structure. SympFlow allows for two key applications: (i) providing a time-continuous symplectic approximation of the exact flow of a Hamiltonian system--purely based on the differential equations it satisfies, and (ii) approximating the flow map of an unknown Hamiltonian system relying on trajectory data. We demonstrate the effectiveness of SympFlow on diverse problems, including chaotic and dissipative systems, showing improved energy conservation compared to general-purpose numerical methods and accurate
Benchmarking learned algorithms for computed tomography image reconstruction tasks
Dec 11, 2024



Computed tomography (CT) is a widely used non-invasive diagnostic method in various fields, and recent advances in deep learning have led to significant progress in CT image reconstruction. However, the lack of large-scale, open-access datasets has hindered the comparison of different types of learned methods. To address this gap, we use the 2DeteCT dataset, a real-world experimental computed tomography dataset, for benchmarking machine learning based CT image reconstruction algorithms. We categorize these methods into post-processing networks, learned/unrolled iterative methods, learned regularizer methods, and plug-and-play methods, and provide a pipeline for easy implementation and evaluation. Using key performance metrics, including SSIM and PSNR, our benchmarking results showcase the effectiveness of various algorithms on tasks such as full data reconstruction, limited-angle reconstruction, sparse-angle reconstruction, low-dose reconstruction, and beam-hardening corrected reconstruction. With this benchmarking study, we provide an evaluation of a range of algorithms representative for different categories of learned reconstruction methods on a recently published dataset of real-world experimental CT measurements. The reproducible setup of methods and CT image reconstruction tasks in an open-source toolbox enables straightforward addition and comparison of new methods later on. The toolbox also provides the option to load the 2DeteCT dataset differently for extensions to other problems and different CT reconstruction tasks.
Hamiltonian Matching for Symplectic Neural Integrators
Oct 23, 2024



Hamilton's equations of motion form a fundamental framework in various branches of physics, including astronomy, quantum mechanics, particle physics, and climate science. Classical numerical solvers are typically employed to compute the time evolution of these systems. However, when the system spans multiple spatial and temporal scales numerical errors can accumulate, leading to reduced accuracy. To address the challenges of evolving such systems over long timescales, we propose SympFlow, a novel neural network-based symplectic integrator, which is the composition of a sequence of exact flow maps of parametrised time-dependent Hamiltonian functions. This architecture allows for a backward error analysis: we can identify an underlying Hamiltonian function of the architecture and use it to define a Hamiltonian matching objective function, which we use for training. In numerical experiments, we show that SympFlow exhibits promising results, with qualitative energy conservation behaviour similar to that of time-stepping symplectic integrators.
Lie Algebra Canonicalization: Equivariant Neural Operators under arbitrary Lie Groups
Oct 03, 2024



The quest for robust and generalizable machine learning models has driven recent interest in exploiting symmetries through equivariant neural networks. In the context of PDE solvers, recent works have shown that Lie point symmetries can be a useful inductive bias for Physics-Informed Neural Networks (PINNs) through data and loss augmentation. Despite this, directly enforcing equivariance within the model architecture for these problems remains elusive. This is because many PDEs admit non-compact symmetry groups, oftentimes not studied beyond their infinitesimal generators, making them incompatible with most existing equivariant architectures. In this work, we propose Lie aLgebrA Canonicalization (LieLAC), a novel approach that exploits only the action of infinitesimal generators of the symmetry group, circumventing the need for knowledge of the full group structure. To achieve this, we address existing theoretical issues in the canonicalization literature, establishing connections with frame averaging in the case of continuous non-compact groups. Operating within the framework of canonicalization, LieLAC can easily be integrated with unconstrained pre-trained models, transforming inputs to a canonical form before feeding them into the existing model, effectively aligning the input for model inference according to allowed symmetries. LieLAC utilizes standard Lie group descent schemes, achieving equivariance in pre-trained models. Finally, we showcase LieLAC's efficacy on tasks of invariant image classification and Lie point symmetry equivariant neural PDE solvers using pre-trained models.
Contractive Systems Improve Graph Neural Networks Against Adversarial Attacks
Nov 12, 2023Graph Neural Networks (GNNs) have established themselves as a key component in addressing diverse graph-based tasks. Despite their notable successes, GNNs remain susceptible to input perturbations in the form of adversarial attacks. This paper introduces an innovative approach to fortify GNNs against adversarial perturbations through the lens of contractive dynamical systems. Our method introduces graph neural layers based on differential equations with contractive properties, which, as we show, improve the robustness of GNNs. A distinctive feature of the proposed approach is the simultaneous learned evolution of both the node features and the adjacency matrix, yielding an intrinsic enhancement of model robustness to perturbations in the input features and the connectivity of the graph. We mathematically derive the underpinnings of our novel architecture and provide theoretical insights to reason about its expected behavior. We demonstrate the efficacy of our method through numerous real-world benchmarks, reading on par or improved performance compared to existing methods.
Convergent regularization in inverse problems and linear plug-and-play denoisers
Jul 18, 2023Plug-and-play (PnP) denoising is a popular iterative framework for solving imaging inverse problems using off-the-shelf image denoisers. Their empirical success has motivated a line of research that seeks to understand the convergence of PnP iterates under various assumptions on the denoiser. While a significant amount of research has gone into establishing the convergence of the PnP iteration for different regularity conditions on the denoisers, not much is known about the asymptotic properties of the converged solution as the noise level in the measurement tends to zero, i.e., whether PnP methods are provably convergent regularization schemes under reasonable assumptions on the denoiser. This paper serves two purposes: first, we provide an overview of the classical regularization theory in inverse problems and survey a few notable recent data-driven methods that are provably convergent regularization schemes. We then continue to discuss PnP algorithms and their established convergence guarantees. Subsequently, we consider PnP algorithms with linear denoisers and propose a novel spectral filtering technique to control the strength of regularization arising from the denoiser. Further, by relating the implicit regularization of the denoiser to an explicit regularization functional, we rigorously show that PnP with linear denoisers leads to a convergent regularization scheme. More specifically, we prove that in the limit as the noise vanishes, the PnP reconstruction converges to the minimizer of a regularization potential subject to the solution satisfying the noiseless operator equation. The theoretical analysis is corroborated by numerical experiments for the classical inverse problem of tomographic image reconstruction.
Designing Stable Neural Networks using Convex Analysis and ODEs
Jun 29, 2023Motivated by classical work on the numerical integration of ordinary differential equations we present a ResNet-styled neural network architecture that encodes non-expansive (1-Lipschitz) operators, as long as the spectral norms of the weights are appropriately constrained. This is to be contrasted with the ordinary ResNet architecture which, even if the spectral norms of the weights are constrained, has a Lipschitz constant that, in the worst case, grows exponentially with the depth of the network. Further analysis of the proposed architecture shows that the spectral norms of the weights can be further constrained to ensure that the network is an averaged operator, making it a natural candidate for a learned denoiser in Plug-and-Play algorithms. Using a novel adaptive way of enforcing the spectral norm constraints, we show that, even with these constraints, it is possible to train performant networks. The proposed architecture is applied to the problem of adversarially robust image classification, to image denoising, and finally to the inverse problem of deblurring.
Dynamical systems' based neural networks
Oct 05, 2022
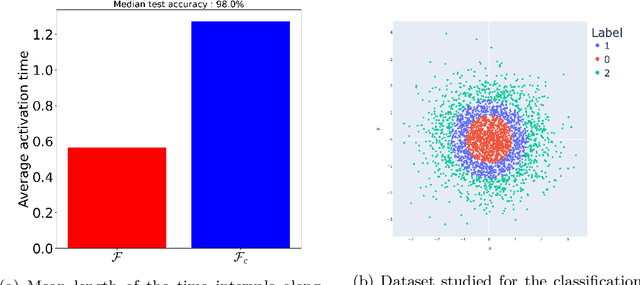
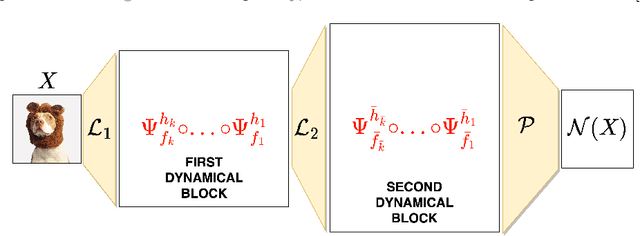
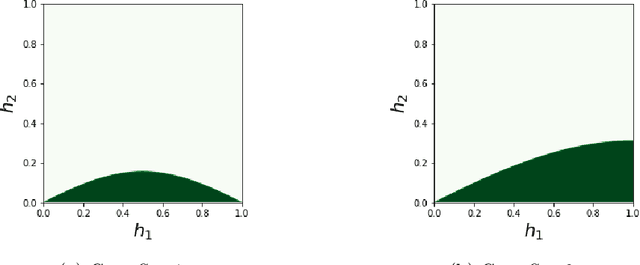
Neural networks have gained much interest because of their effectiveness in many applications. However, their mathematical properties are generally not well understood. If there is some underlying geometric structure inherent to the data or to the function to approximate, it is often desirable to take this into account in the design of the neural network. In this work, we start with a non-autonomous ODE and build neural networks using a suitable, structure-preserving, numerical time-discretisation. The structure of the neural network is then inferred from the properties of the ODE vector field. Besides injecting more structure into the network architectures, this modelling procedure allows a better theoretical understanding of their behaviour. We present two universal approximation results and demonstrate how to impose some particular properties on the neural networks. A particular focus is on 1-Lipschitz architectures including layers that are not 1-Lipschitz. These networks are expressive and robust against adversarial attacks, as shown for the CIFAR-10 dataset.