 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Bluffing by DQN and CFR in Leduc Hold'em Poker
Sep 04, 2025
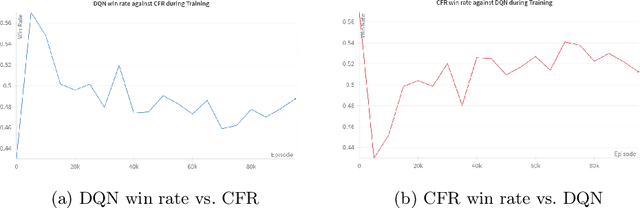
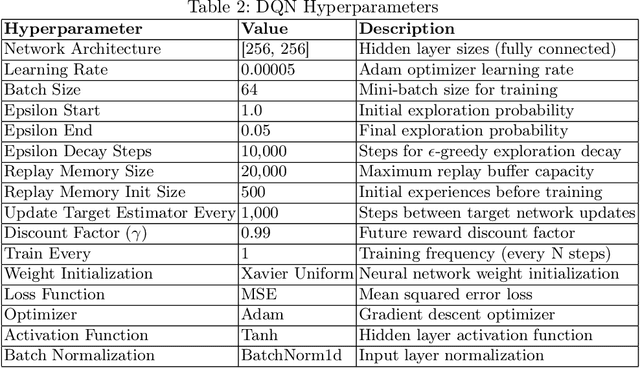
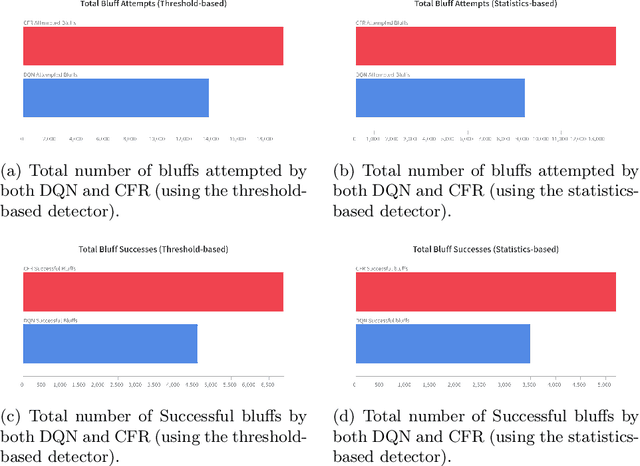
In the game of poker, being unpredictable, or bluffing, is an essential skill. When humans play poker, they bluff. However, most works on computer-poker focus on performance metrics such as win rates, while bluffing is overlooked. In this paper we study whether two popular algorithms, DQN (based on reinforcement learning) and CFR (based on game theory), exhibit bluffing behavior in Leduc Hold'em, a simplified version of poker. We designed an experiment where we let the DQN and CFR agent play against each other while we log their actions. We find that both DQN and CFR exhibit bluffing behavior, but they do so in different ways. Although both attempt to perform bluffs at different rates, the percentage of successful bluffs (where the opponent folds) is roughly the same. This suggests that bluffing is an essential aspect of the game, not of the algorithm. Future work should look at different bluffing styles and at the full game of poker. Code at https://github.com/TarikZ03/Bluffing-by-DQN-and-CFR-in-Leduc-Hold-em-Poker-Codebase.
Noise2Ghost: Self-supervised deep convolutional reconstruction for ghost imaging
Apr 14, 2025



We present a new self-supervised deep-learning-based Ghost Imaging (GI) reconstruction method, which provides unparalleled reconstruction performance for noisy acquisitions among unsupervised methods. We present the supporting mathematical framework and results from theoretical and real data use cases. Self-supervision removes the need for clean reference data while offering strong noise reduction. This provides the necessary tools for addressing signal-to-noise ratio concerns for GI acquisitions in emerging and cutting-edge low-light GI scenarios. Notable examples include micro- and nano-scale x-ray emission imaging, e.g., x-ray fluorescence imaging of dose-sensitive samples. Their applications include in-vivo and in-operando case studies for biological samples and batteries.
Benchmarking learned algorithms for computed tomography image reconstruction tasks
Dec 11, 2024



Computed tomography (CT) is a widely used non-invasive diagnostic method in various fields, and recent advances in deep learning have led to significant progress in CT image reconstruction. However, the lack of large-scale, open-access datasets has hindered the comparison of different types of learned methods. To address this gap, we use the 2DeteCT dataset, a real-world experimental computed tomography dataset, for benchmarking machine learning based CT image reconstruction algorithms. We categorize these methods into post-processing networks, learned/unrolled iterative methods, learned regularizer methods, and plug-and-play methods, and provide a pipeline for easy implementation and evaluation. Using key performance metrics, including SSIM and PSNR, our benchmarking results showcase the effectiveness of various algorithms on tasks such as full data reconstruction, limited-angle reconstruction, sparse-angle reconstruction, low-dose reconstruction, and beam-hardening corrected reconstruction. With this benchmarking study, we provide an evaluation of a range of algorithms representative for different categories of learned reconstruction methods on a recently published dataset of real-world experimental CT measurements. The reproducible setup of methods and CT image reconstruction tasks in an open-source toolbox enables straightforward addition and comparison of new methods later on. The toolbox also provides the option to load the 2DeteCT dataset differently for extensions to other problems and different CT reconstruction tasks.
Learned denoising with simulated and experimental low-dose CT data
Aug 15, 2024



Like in many other research fields, recent developments in computational imaging have focused on developing machine learning (ML) approaches to tackle its main challenges. To improve the performance of computational imaging algorithms, machine learning methods are used for image processing tasks such as noise reduction. Generally, these ML methods heavily rely on the availability of high-quality data on which they are trained. This work explores the application of ML methods, specifically convolutional neural networks (CNNs), in the context of noise reduction for computed tomography (CT) imaging. We utilize a large 2D computed tomography dataset for machine learning to carry out for the first time a comprehensive study on the differences between the observed performances of algorithms trained on simulated noisy data and on real-world experimental noisy data. The study compares the performance of two common CNN architectures, U-Net and MSD-Net, that are trained and evaluated on both simulated and experimental noisy data. The results show that while sinogram denoising performed better with simulated noisy data if evaluated in the sinogram domain, the performance did not carry over to the reconstruction domain where training on experimental noisy data shows a higher performance in denoising experimental noisy data. Training the algorithms in an end-to-end fashion from sinogram to reconstruction significantly improved model performance, emphasizing the importance of matching raw measurement data to high-quality CT reconstructions. The study furthermore suggests the need for more sophisticated noise simulation approaches to bridge the gap between simulated and real-world data in CT image denoising applications and gives insights into the challenges and opportunities in leveraging simulated data for machine learning in computational imaging.
Implicit Neural Representations for Robust Joint Sparse-View CT Reconstruction
May 03, 2024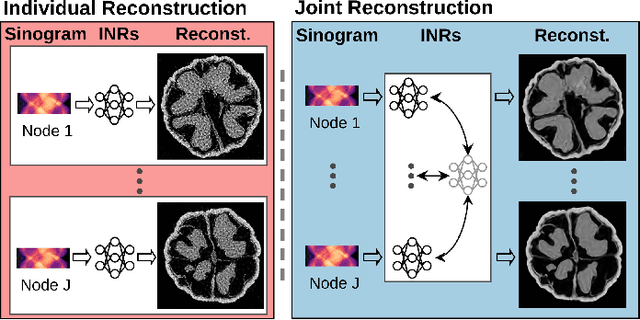
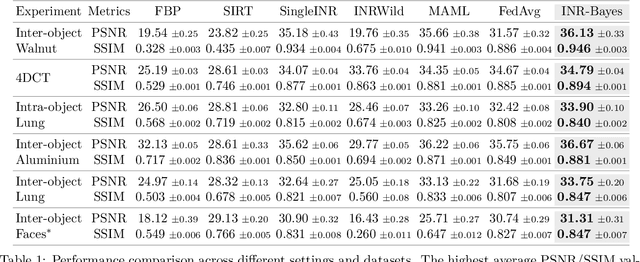
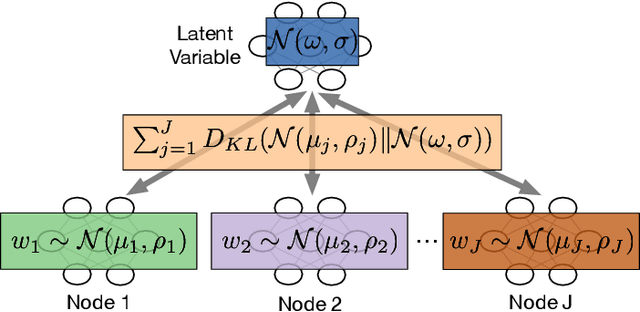
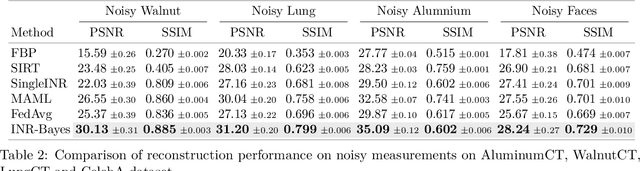
Computed Tomography (CT) is pivotal in industrial quality control and medical diagnostics. Sparse-view CT, offering reduced ionizing radiation, faces challenges due to its under-sampled nature, leading to ill-posed reconstruction problems. Recent advancements in Implicit Neural Representations (INRs) have shown promise in addressing sparse-view CT reconstruction. Recognizing that CT often involves scanning similar subjects, we propose a novel approach to improve reconstruction quality through joint reconstruction of multiple objects using INRs. This approach can potentially leverage both the strengths of INRs and the statistical regularities across multiple objects. While current INR joint reconstruction techniques primarily focus on accelerating convergence via meta-initialization, they are not specifically tailored to enhance reconstruction quality. To address this gap, we introduce a novel INR-based Bayesian framework integrating latent variables to capture the inter-object relationships. These variables serve as a dynamic reference throughout the optimization, thereby enhancing individual reconstruction fidelity. Our extensive experiments, which assess various key factors such as reconstruction quality, resistance to overfitting, and generalizability, demonstrate significant improvements over baselines in common numerical metrics. This underscores a notable advancement in CT reconstruction methods.
SR4ZCT: Self-supervised Through-plane Resolution Enhancement for CT Images with Arbitrary Resolution and Overlap
May 03, 2024Computed tomography (CT) is a widely used non-invasive medical imaging technique for disease diagnosis. The diagnostic accuracy is often affected by image resolution, which can be insufficient in practice. For medical CT images, the through-plane resolution is often worse than the in-plane resolution and there can be overlap between slices, causing difficulties in diagnoses. Self-supervised methods for through-plane resolution enhancement, which train on in-plane images and infer on through-plane images, have shown promise for both CT and MRI imaging. However, existing self-supervised methods either neglect overlap or can only handle specific cases with fixed combinations of resolution and overlap. To address these limitations, we propose a self-supervised method called SR4ZCT. It employs the same off-axis training approach while being capable of handling arbitrary combinations of resolution and overlap. Our method explicitly models the relationship between resolutions and voxel spacings of different planes to accurately simulate training images that match the original through-plane images. We highlight the significance of accurate modeling in self-supervised off-axis training and demonstrate the effectiveness of SR4ZCT using a real-world dataset.
X-ray Image Generation as a Method of Performance Prediction for Real-Time Inspection: a Case Study
Jan 30, 2024X-ray imaging can be efficiently used for high-throughput in-line inspection of industrial products. However, designing a system that satisfies industrial requirements and achieves high accuracy is a challenging problem. The effect of many system settings is application-specific and difficult to predict in advance. Consequently, the system is often configured using empirical rules and visual observations. The performance of the resulting system is characterized by extensive experimental testing. We propose to use computational methods to substitute real measurements with generated images corresponding to the same experimental settings. With this approach, it is possible to observe the influence of experimental settings on a large amount of data and to make a prediction of the system performance faster than with conventional methods. We argue that a high accuracy of the image generator may be unnecessary for an accurate performance prediction. We propose a quantitative methodology to characterize the quality of the generation model using POD curves. The proposed approach can be adapted to various applications and we demonstrate it on the poultry inspection problem. We show how a calibrated image generation model can be used to quantitatively evaluate the effect of the X-ray exposure time on the performance of the inspection system.
Multi-stage Deep Learning Artifact Reduction for Computed Tomography
Sep 01, 2023In Computed Tomography (CT), an image of the interior structure of an object is computed from a set of acquired projection images. The quality of these reconstructed images is essential for accurate analysis, but this quality can be degraded by a variety of imaging artifacts. To improve reconstruction quality, the acquired projection images are often processed by a pipeline consisting of multiple artifact-removal steps applied in various image domains (e.g., outlier removal on projection images and denoising of reconstruction images). These artifact-removal methods exploit the fact that certain artifacts are easier to remove in a certain domain compared with other domains. Recently, deep learning methods have shown promising results for artifact removal for CT images. However, most existing deep learning methods for CT are applied as a post-processing method after reconstruction. Therefore, artifacts that are relatively difficult to remove in the reconstruction domain may not be effectively removed by these methods. As an alternative, we propose a multi-stage deep learning method for artifact removal, in which neural networks are applied to several domains, similar to a classical CT processing pipeline. We show that the neural networks can be effectively trained in succession, resulting in easy-to-use and computationally efficient training. Experiments on both simulated and real-world experimental datasets show that our method is effective in reducing artifacts and superior to deep learning-based post-processing.
2DeteCT -- A large 2D expandable, trainable, experimental Computed Tomography dataset for machine learning
Jun 09, 2023Recent research in computational imaging largely focuses on developing machine learning (ML) techniques for image reconstruction, which requires large-scale training datasets consisting of measurement data and ground-truth images. However, suitable experimental datasets for X-ray Computed Tomography (CT) are scarce, and methods are often developed and evaluated only on simulated data. We fill this gap by providing the community with a versatile, open 2D fan-beam CT dataset suitable for developing ML techniques for a range of image reconstruction tasks. To acquire it, we designed a sophisticated, semi-automatic scan procedure that utilizes a highly-flexible laboratory X-ray CT setup. A diverse mix of samples with high natural variability in shape and density was scanned slice-by-slice (5000 slices in total) with high angular and spatial resolution and three different beam characteristics: A high-fidelity, a low-dose and a beam-hardening-inflicted mode. In addition, 750 out-of-distribution slices were scanned with sample and beam variations to accommodate robustness and segmentation tasks. We provide raw projection data, reference reconstructions and segmentations based on an open-source data processing pipeline.
Quantifying the effect of X-ray scattering for data generation in real-time defect detection
May 22, 2023X-ray imaging is widely used for non-destructive detection of defects in industrial products on a conveyor belt. Real-time detection requires highly accurate, robust, and fast algorithms to analyze X-ray images. Deep convolutional neural networks (DCNNs) satisfy these requirements if a large amount of labeled data is available. To overcome the challenge of collecting these data, different methods of X-ray image generation can be considered. Depending on the desired level of similarity to real data, various physical effects either should be simulated or can be ignored. X-ray scattering is known to be computationally expensive to simulate, and this effect can heavily influence the accuracy of a generated X-ray image. We propose a methodology for quantitative evaluation of the effect of scattering on defect detection. This methodology compares the accuracy of DCNNs trained on different versions of the same data that include and exclude the scattering signal. We use the Probability of Detection (POD) curves to find the size of the smallest defect that can be detected with a DCNN and evaluate how this size is affected by the choice of training data. We apply the proposed methodology to a model problem of defect detection in cylinders. Our results show that the exclusion of the scattering signal from the training data has the largest effect on the smallest detectable defects. Furthermore, we demonstrate that accurate inspection is more reliant on high-quality training data for images with a high quantity of scattering. We discuss how the presented methodology can be used for other tasks and objects.