 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn invertible generative model for forward and inverse problems
Sep 04, 2025We formulate the inverse problem in a Bayesian framework and aim to train a generative model that allows us to simulate (i.e., sample from the likelihood) and do inference (i.e., sample from the posterior). We review the use of triangular normalizing flows for conditional sampling in this context and show how to combine two such triangular maps (an upper and a lower one) in to one invertible mapping that can be used for simulation and inference. We work out several useful properties of this invertible generative model and propose a possible training loss for training the map directly. We illustrate the workings of this new approach to conditional generative modeling numerically on a few stylized examples.
PtyGenography: using generative models for regularization of the phase retrieval problem
Feb 03, 2025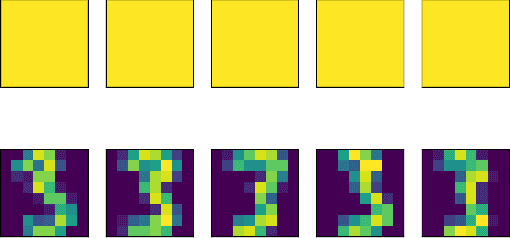
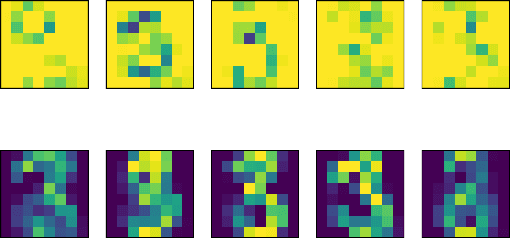
In phase retrieval and similar inverse problems, the stability of solutions across different noise levels is crucial for applications. One approach to promote it is using signal priors in a form of a generative model as a regularization, at the expense of introducing a bias in the reconstruction. In this paper, we explore and compare the reconstruction properties of classical and generative inverse problem formulations. We propose a new unified reconstruction approach that mitigates overfitting to the generative model for varying noise levels.
Exploring Out-of-distribution Detection for Sparse-view Computed Tomography with Diffusion Models
Nov 09, 2024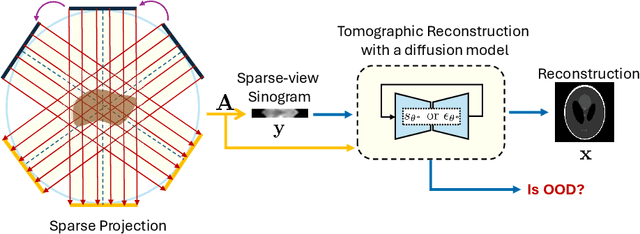
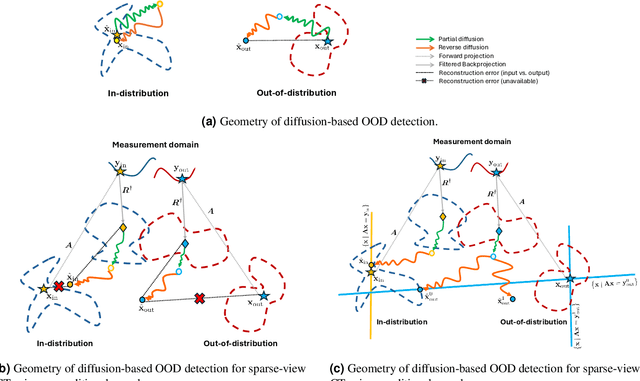
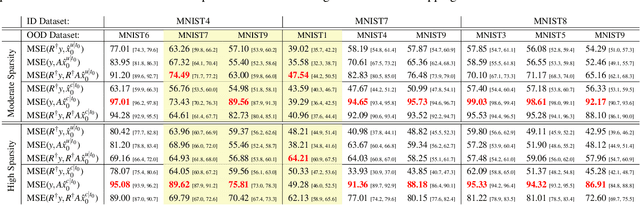

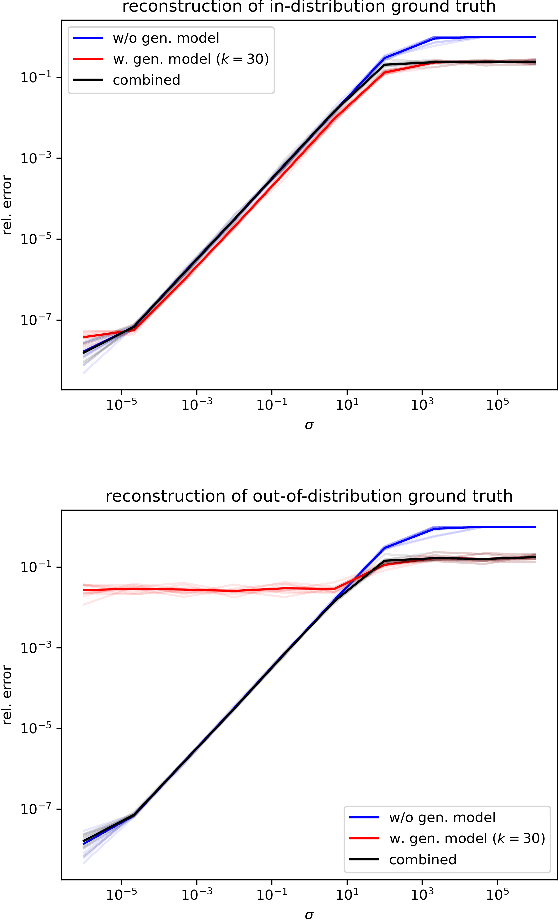
Recent works demonstrate the effectiveness of diffusion models as unsupervised solvers for inverse imaging problems. Sparse-view computed tomography (CT) has greatly benefited from these advancements, achieving improved generalization without reliance on measurement parameters. However, this comes at the cost of potential hallucinations, especially when handling out-of-distribution (OOD) data. To ensure reliability, it is essential to study OOD detection for CT reconstruction across both clinical and industrial applications. This need further extends to enabling the OOD detector to function effectively as an anomaly inspection tool. In this paper, we explore the use of a diffusion model, trained to capture the target distribution for CT reconstruction, as an in-distribution prior. Building on recent research, we employ the model to reconstruct partially diffused input images and assess OOD-ness through multiple reconstruction errors. Adapting this approach for sparse-view CT requires redefining the notions of "input" and "reconstruction error". Here, we use filtered backprojection (FBP) reconstructions as input and investigate various definitions of reconstruction error. Our proof-of-concept experiments on the MNIST dataset highlight both successes and failures, demonstrating the potential and limitations of integrating such an OOD detector into a CT reconstruction system. Our findings suggest that effective OOD detection can be achieved by comparing measurements with forward-projected reconstructions, provided that reconstructions from noisy FBP inputs are conditioned on the measurements. However, conditioning can sometimes lead the OOD detector to inadvertently reconstruct OOD images well. To counter this, we introduce a weighting approach that improves robustness against highly informative OOD measurements, albeit with a trade-off in performance in certain cases.
AC-IND: Sparse CT reconstruction based on attenuation coefficient estimation and implicit neural distribution
Sep 11, 2024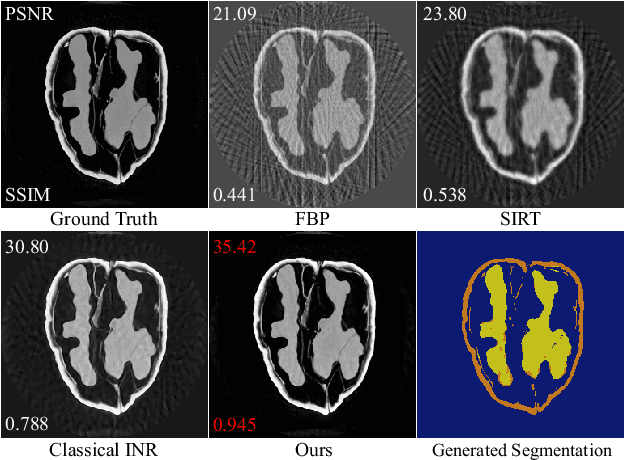
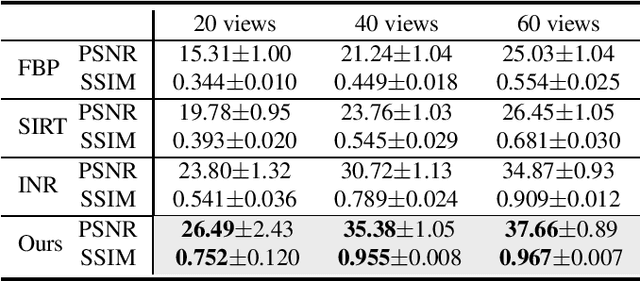
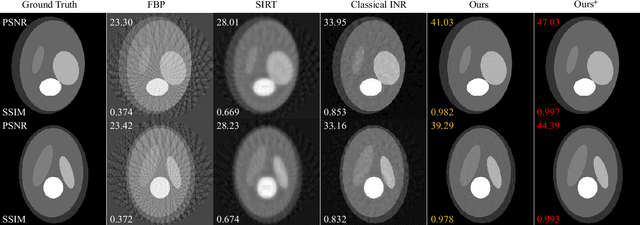
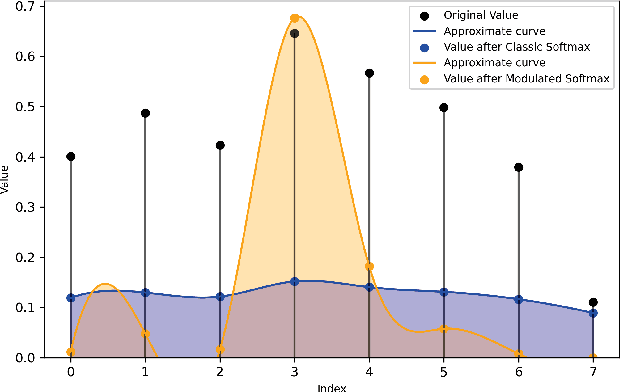
Computed tomography (CT) reconstruction plays a crucial role in industrial nondestructive testing and medical diagnosis. Sparse view CT reconstruction aims to reconstruct high-quality CT images while only using a small number of projections, which helps to improve the detection speed of industrial assembly lines and is also meaningful for reducing radiation in medical scenarios. Sparse CT reconstruction methods based on implicit neural representations (INRs) have recently shown promising performance, but still produce artifacts because of the difficulty of obtaining useful prior information. In this work, we incorporate a powerful prior: the total number of material categories of objects. To utilize the prior, we design AC-IND, a self-supervised method based on Attenuation Coefficient Estimation and Implicit Neural Distribution. Specifically, our method first transforms the traditional INR from scalar mapping to probability distribution mapping. Then we design a compact attenuation coefficient estimator initialized with values from a rough reconstruction and fast segmentation. Finally, our algorithm finishes the CT reconstruction by jointly optimizing the estimator and the generated distribution. Through experiments, we find that our method not only outperforms the comparative methods in sparse CT reconstruction but also can automatically generate semantic segmentation maps.
Experimental Validation of Ultrasound Beamforming with End-to-End Deep Learning for Single Plane Wave Imaging
Apr 22, 2024



Ultrafast ultrasound imaging insonifies a medium with one or a combination of a few plane waves at different beam-steered angles instead of many focused waves. It can achieve much higher frame rates, but often at the cost of reduced image quality. Deep learning approaches have been proposed to mitigate this disadvantage, in particular for single plane wave imaging. Predominantly, image-to-image post-processing networks or fully learned data-to-image neural networks are used. Both construct their mapping purely data-driven and require expressive networks and large amounts of training data to perform well. In contrast, we consider data-to-image networks which incorporate a conventional image formation techniques as differentiable layers in the network architecture. This allows for end-to-end training with small amounts of training data. In this work, using f-k migration as an image formation layer is evaluated in-depth with experimental data. We acquired a data collection designed for benchmarking data-driven plane wave imaging approaches using a realistic breast mimicking phantom and an ultrasound calibration phantom. The evaluation considers global and local image similarity measures and contrast, resolution and lesion detectability analysis. The results show that the proposed network architecture is capable of improving the image quality of single plane wave images on all evaluation metrics. Furthermore, these image quality improvements can be achieved with surprisingly little amounts of training data.
X-ray Image Generation as a Method of Performance Prediction for Real-Time Inspection: a Case Study
Jan 30, 2024X-ray imaging can be efficiently used for high-throughput in-line inspection of industrial products. However, designing a system that satisfies industrial requirements and achieves high accuracy is a challenging problem. The effect of many system settings is application-specific and difficult to predict in advance. Consequently, the system is often configured using empirical rules and visual observations. The performance of the resulting system is characterized by extensive experimental testing. We propose to use computational methods to substitute real measurements with generated images corresponding to the same experimental settings. With this approach, it is possible to observe the influence of experimental settings on a large amount of data and to make a prediction of the system performance faster than with conventional methods. We argue that a high accuracy of the image generator may be unnecessary for an accurate performance prediction. We propose a quantitative methodology to characterize the quality of the generation model using POD curves. The proposed approach can be adapted to various applications and we demonstrate it on the poultry inspection problem. We show how a calibrated image generation model can be used to quantitatively evaluate the effect of the X-ray exposure time on the performance of the inspection system.
Time-Resolved Reconstruction of Motion, Force, and Stiffness using Spectro-Dynamic MRI
Oct 11, 2023
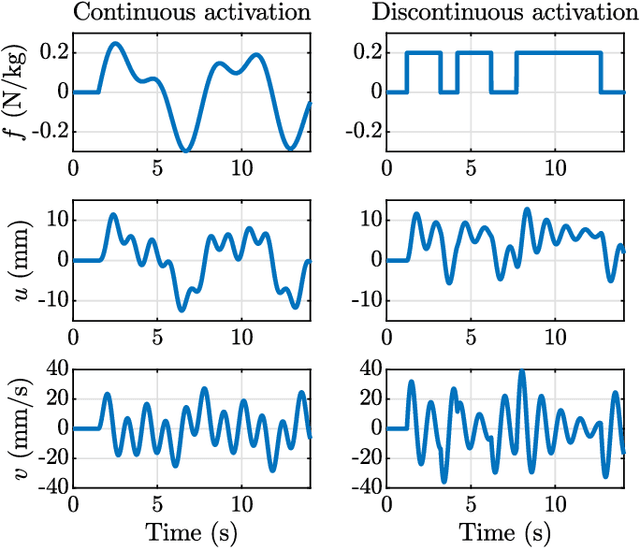
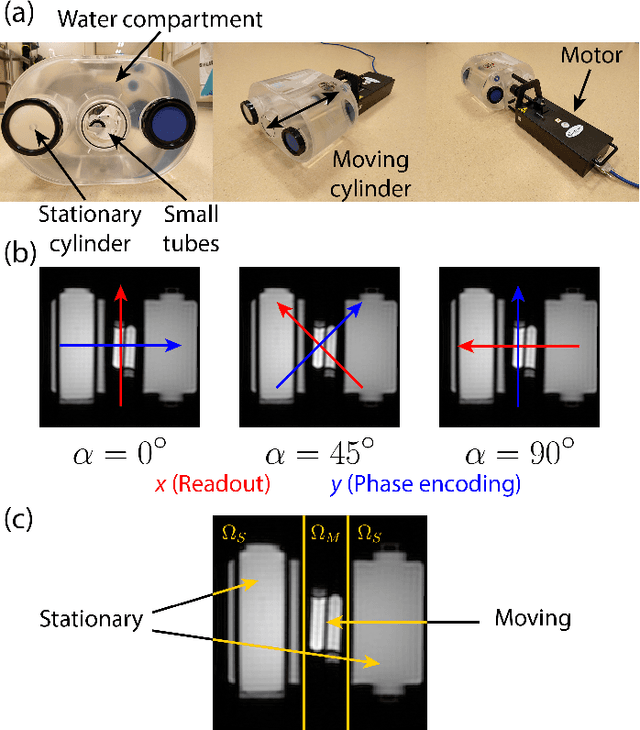

Measuring the dynamics and mechanical properties of muscles and joints is important to understand the (patho)physiology of muscles. However, acquiring dynamic time-resolved MRI data is challenging. We have previously developed Spectro-Dynamic MRI which allows the characterization of dynamical systems at a high spatial and temporal resolution directly from k-space data. This work presents an extended Spectro-Dynamic MRI framework that reconstructs 1) time-resolved MR images, 2) time-resolved motion fields, 3) dynamical parameters, and 4) an activation force, at a temporal resolution of 11 ms. An iterative algorithm solves a minimization problem containing four terms: a motion model relating the motion to the fully-sampled k-space data, a dynamical model describing the expected type of dynamics, a data consistency term describing the undersampling pattern, and finally a regularization term for the activation force. We acquired MRI data using a dynamic motion phantom programmed to move like an actively driven linear elastic system, from which all dynamic variables could be accurately reconstructed, regardless of the sampling pattern. The proposed method performed better than a two-step approach, where time-resolved images were first reconstructed from the undersampled data without any information about the motion, followed by a motion estimation step.
Detecting internal disorders in fruit by CT. Part 1: Joint 2D to 3D image registration workflow for comparing multiple slice photographs and CT scans of apple fruit
Oct 03, 2023A large percentage of apples are affected by internal disorders after long-term storage, which makes them unacceptable in the supply chain. CT imaging is a promising technique for in-line detection of these disorders. Therefore, it is crucial to understand how different disorders affect the image features that can be observed in CT scans. This paper presents a workflow for creating datasets of image pairs of photographs of apple slices and their corresponding CT slices. By having CT and photographic images of the same part of the apple, the complementary information in both images can be used to study the processes underlying internal disorders and how internal disorders can be measured in CT images. The workflow includes data acquisition, image segmentation, image registration, and validation methods. The image registration method aligns all available slices of an apple within a single optimization problem, assuming that the slices are parallel. This method outperformed optimizing the alignment separately for each slice. The workflow was applied to create a dataset of 1347 slice photographs and their corresponding CT slices. The dataset was acquired from 107 'Kanzi' apples that had been stored in controlled atmosphere (CA) storage for 8 months. In this dataset, the distance between annotations in the slice photograph and the matching CT slice was, on average, $1.47 \pm 0.40$ mm. Our workflow allows collecting large datasets of accurately aligned photo-CT image pairs, which can help distinguish internal disorders with a similar appearance on CT. With slight modifications, a similar workflow can be applied to other fruits or MRI instead of CT scans.
Maximum-likelihood estimation in ptychography in the presence of Poisson-Gaussian noise statistics
Aug 03, 2023Optical measurements often exhibit mixed Poisson-Gaussian noise statistics, which hampers image quality, particularly under low signal-to-noise ratio (SNR) conditions. Computational imaging falls short in such situations when solely Poissonian noise statistics are assumed. In response to this challenge, we define a loss function that explicitly incorporates this mixed noise nature. By using maximum-likelihood estimation, we devise a practical method to account for camera readout noise in gradient-based ptychography optimization. Our results, based on both experimental and numerical data, demonstrate that this approach outperforms the conventional one, enabling enhanced image reconstruction quality under challenging noise conditions through a straightforward methodological adjustment.
Sequential Experimental Design for X-Ray CT Using Deep Reinforcement Learning
Jul 12, 2023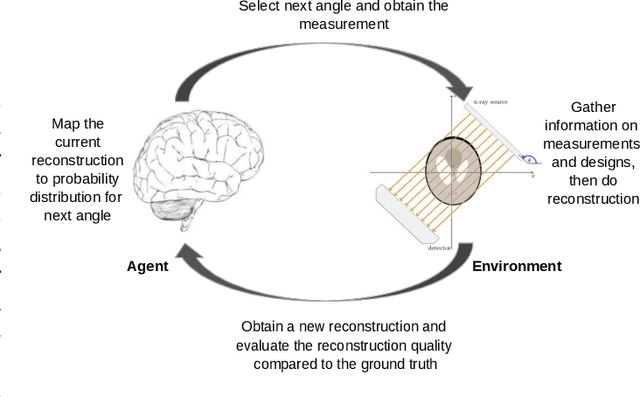
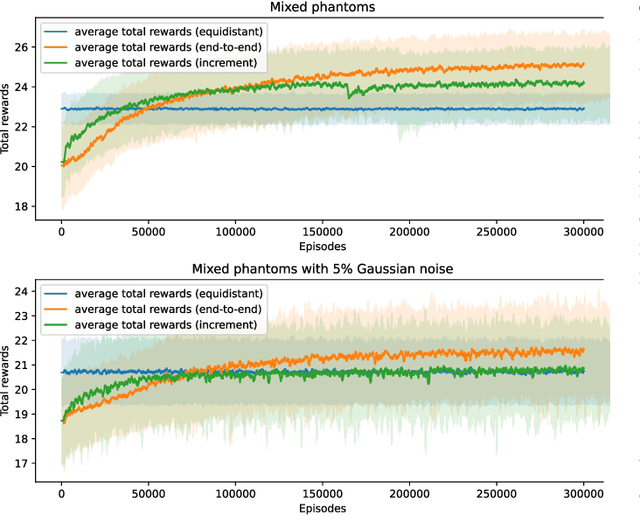
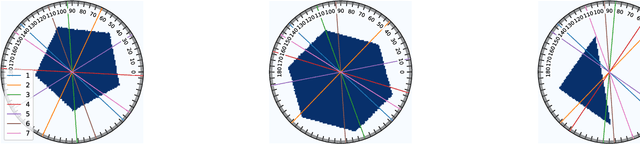
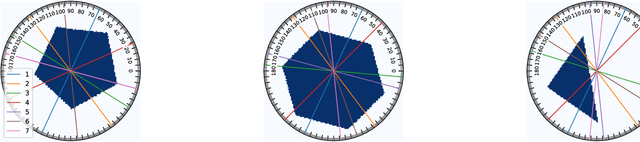
In X-ray Computed Tomography (CT), projections from many angles are acquired and used for 3D reconstruction. To make CT suitable for in-line quality control, reducing the number of angles while maintaining reconstruction quality is necessary. Sparse-angle tomography is a popular approach for obtaining 3D reconstructions from limited data. To optimize its performance, one can adapt scan angles sequentially to select the most informative angles for each scanned object. Mathematically, this corresponds to solving and optimal experimental design (OED) problem. OED problems are high-dimensional, non-convex, bi-level optimization problems that cannot be solved online, i.e., during the scan. To address these challenges, we pose the OED problem as a partially observable Markov decision process in a Bayesian framework, and solve it through deep reinforcement learning. The approach learns efficient non-greedy policies to solve a given class of OED problems through extensive offline training rather than solving a given OED problem directly via numerical optimization. As such, the trained policy can successfully find the most informative scan angles online. We use a policy training method based on the Actor-Critic approach and evaluate its performance on 2D tomography with synthetic data.