 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Large Language Models, a survey
Mar 29, 2025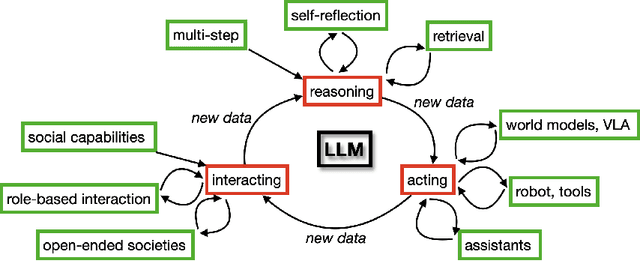

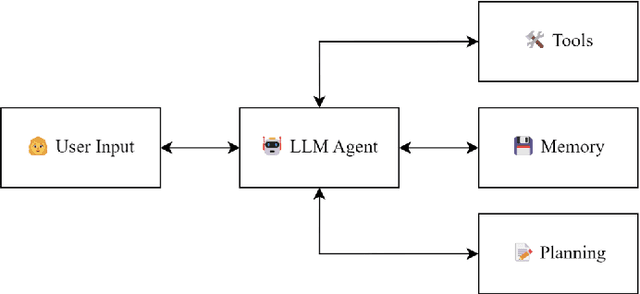
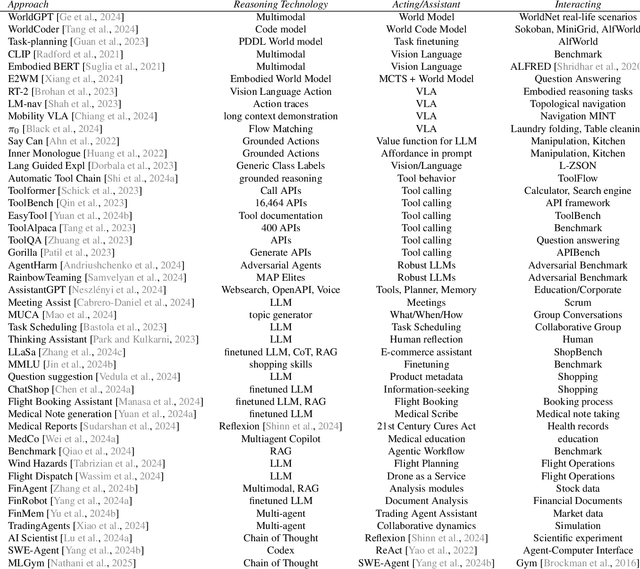
There is great interest in agentic LLMs, large language models that act as agents. We review the growing body of work in this area and provide a research agenda. Agentic LLMs are LLMs that (1) reason, (2) act, and (3) interact. We organize the literature according to these three categories. The research in the first category focuses on reasoning, reflection, and retrieval, aiming to improve decision making; the second category focuses on action models, robots, and tools, aiming for agents that act as useful assistants; the third category focuses on multi-agent systems, aiming for collaborative task solving and simulating interaction to study emergent social behavior. We find that works mutually benefit from results in other categories: retrieval enables tool use, reflection improves multi-agent collaboration, and reasoning benefits all categories. We discuss applications of agentic LLMs and provide an agenda for further research. Important applications are in medical diagnosis, logistics and financial market analysis. Meanwhile, self-reflective agents playing roles and interacting with one another augment the process of scientific research itself. Further, agentic LLMs may provide a solution for the problem of LLMs running out of training data: inference-time behavior generates new training states, such that LLMs can keep learning without needing ever larger datasets. We note that there is risk associated with LLM assistants taking action in the real world, while agentic LLMs are also likely to benefit society.
Single-shot Tomography of Discrete Dynamic Objects
Nov 09, 2023



This paper presents a novel method for the reconstruction of high-resolution temporal images in dynamic tomographic imaging, particularly for discrete objects with smooth boundaries that vary over time. Addressing the challenge of limited measurements per time point, we propose a technique that synergistically incorporates spatial and temporal information of the dynamic objects. This is achieved through the application of the level-set method for image segmentation and the representation of motion via a sinusoidal basis. The result is a computationally efficient and easily optimizable variational framework that enables the reconstruction of high-quality 2D or 3D image sequences with a single projection per frame. Compared to current methods, our proposed approach demonstrates superior performance on both synthetic and pseudo-dynamic real X-ray tomography datasets. The implications of this research extend to improved visualization and analysis of dynamic processes in tomographic imaging, finding potential applications in diverse scientific and industrial domains.
Detecting internal disorders in fruit by CT. Part 1: Joint 2D to 3D image registration workflow for comparing multiple slice photographs and CT scans of apple fruit
Oct 03, 2023A large percentage of apples are affected by internal disorders after long-term storage, which makes them unacceptable in the supply chain. CT imaging is a promising technique for in-line detection of these disorders. Therefore, it is crucial to understand how different disorders affect the image features that can be observed in CT scans. This paper presents a workflow for creating datasets of image pairs of photographs of apple slices and their corresponding CT slices. By having CT and photographic images of the same part of the apple, the complementary information in both images can be used to study the processes underlying internal disorders and how internal disorders can be measured in CT images. The workflow includes data acquisition, image segmentation, image registration, and validation methods. The image registration method aligns all available slices of an apple within a single optimization problem, assuming that the slices are parallel. This method outperformed optimizing the alignment separately for each slice. The workflow was applied to create a dataset of 1347 slice photographs and their corresponding CT slices. The dataset was acquired from 107 'Kanzi' apples that had been stored in controlled atmosphere (CA) storage for 8 months. In this dataset, the distance between annotations in the slice photograph and the matching CT slice was, on average, $1.47 \pm 0.40$ mm. Our workflow allows collecting large datasets of accurately aligned photo-CT image pairs, which can help distinguish internal disorders with a similar appearance on CT. With slight modifications, a similar workflow can be applied to other fruits or MRI instead of CT scans.
Real-Time Tilt Undersampling Optimization during Electron Tomography of Beam Sensitive Samples using Golden Ratio Scanning and RECAST3D
Apr 01, 2023



Electron tomography is a widely used technique for 3D structural analysis of nanomaterials, but it can cause damage to samples due to high electron doses and long exposure times. To minimize such damage, researchers often reduce beam exposure by acquiring fewer projections through tilt undersampling. However, this approach can also introduce reconstruction artifacts due to insufficient sampling. Therefore, it is important to determine the optimal number of projections that minimizes both beam exposure and undersampling artifacts for accurate reconstructions of beam-sensitive samples. Current methods for determining this optimal number of projections involve acquiring and post-processing multiple reconstructions with different numbers of projections, which can be time-consuming and requires multiple samples due to sample damage. To improve this process, we propose a protocol that combines golden ratio scanning and quasi-3D reconstruction to estimate the optimal number of projections in real-time during a single acquisition. This protocol was validated using simulated and realistic nanoparticles, and was successfully applied to reconstruct two beam-sensitive metal-organic framework complexes.
* accepted in Nanoscale journal. 17 pages, 9 figures, 9 supplementary figures
A tomographic workflow to enable deep learning for X-ray based foreign object detection
Jan 28, 2022

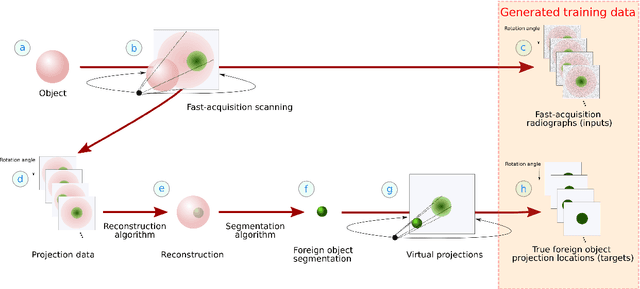

Detection of unwanted (`foreign') objects within products is a common procedure in many branches of industry for maintaining production quality. X-ray imaging is a fast, non-invasive and widely applicable method for foreign object detection. Deep learning has recently emerged as a powerful approach for recognizing patterns in radiographs (i.e., X-ray images), enabling automated X-ray based foreign object detection. However, these methods require a large number of training examples and manual annotation of these examples is a subjective and laborious task. In this work, we propose a Computed Tomography (CT) based method for producing training data for supervised learning of foreign object detection, with minimal labour requirements. In our approach, a few representative objects are CT scanned and reconstructed in 3D. The radiographs that have been acquired as part of the CT-scan data serve as input for the machine learning method. High-quality ground truth locations of the foreign objects are obtained through accurate 3D reconstructions and segmentations. Using these segmented volumes, corresponding 2D segmentations are obtained by creating virtual projections. We outline the benefits of objectively and reproducibly generating training data in this way compared to conventional radiograph annotation. In addition, we show how the accuracy depends on the number of objects used for the CT reconstructions. The results show that in this workflow generally only a relatively small number of representative objects (i.e., fewer than 10) are needed to achieve adequate detection performance in an industrial setting. Moreover, for real experimental data we show that the workflow leads to higher foreign object detection accuracies than with standard radiograph annotation.
ADJUST: A Dictionary-Based Joint Reconstruction and Unmixing Method for Spectral Tomography
Dec 21, 2021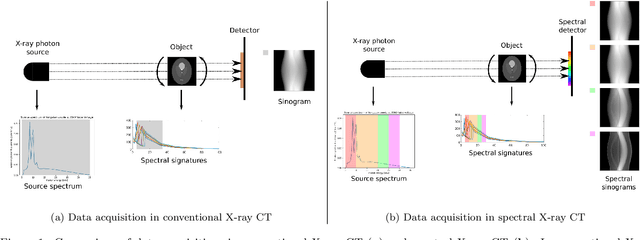
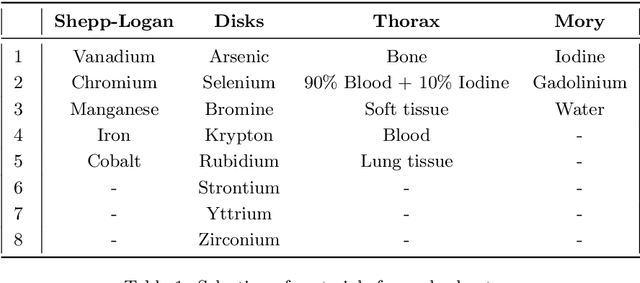
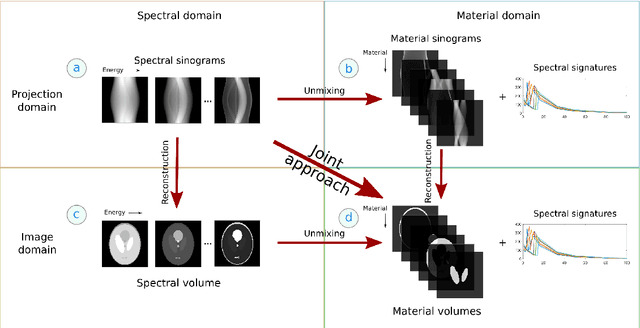
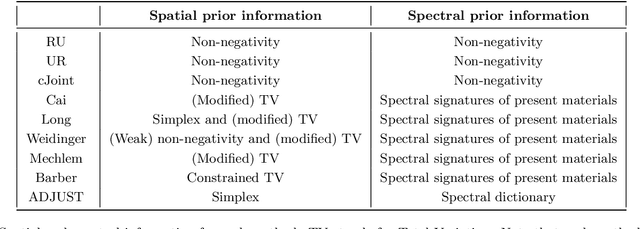
Advances in multi-spectral detectors are causing a paradigm shift in X-ray Computed Tomography (CT). Spectral information acquired from these detectors can be used to extract volumetric material composition maps of the object of interest. If the materials and their spectral responses are known a priori, the image reconstruction step is rather straightforward. If they are not known, however, the maps as well as the responses need to be estimated jointly. A conventional workflow in spectral CT involves performing volume reconstruction followed by material decomposition, or vice versa. However, these methods inherently suffer from the ill-posedness of the joint reconstruction problem. To resolve this issue, we propose `A Dictionary-based Joint reconstruction and Unmixing method for Spectral Tomography' (ADJUST). Our formulation relies on forming a dictionary of spectral signatures of materials common in CT and prior knowledge of the number of materials present in an object. In particular, we decompose the spectral volume linearly in terms of spatial material maps, a spectral dictionary, and the indicator of materials for the dictionary elements. We propose a memory-efficient accelerated alternating proximal gradient method to find an approximate solution to the resulting bi-convex problem. From numerical demonstrations on several synthetic phantoms, we observe that ADJUST performs exceedingly well when compared to other state-of-the-art methods. Additionally, we address the robustness of ADJUST against limited measurement patterns.
Unsupervised foreign object detection based on dual-energy absorptiometry in the food industry
Apr 12, 2021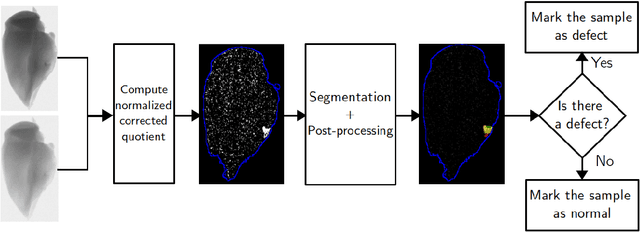
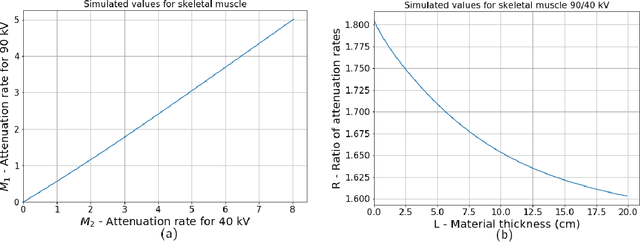
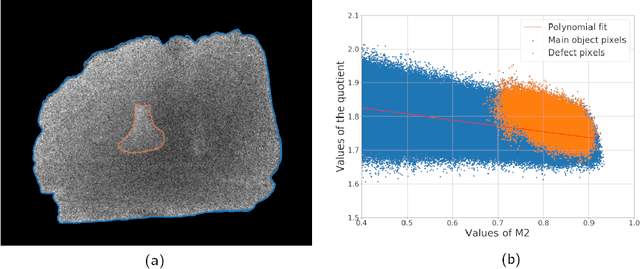
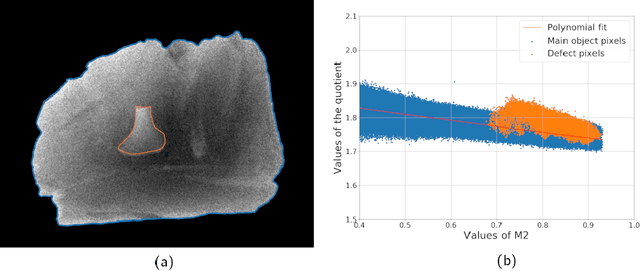
X-ray imaging is a widely used technique for non-destructive inspection of agricultural food products. One application of X-ray imaging is the autonomous, in-line detection of foreign objects in food samples. Examples of such inclusions are bone fragments in meat products, plastic and metal debris in fish, fruit infestations. This article presents a processing methodology for unsupervised foreign object detection based on dual-energy X-ray absorptiometry (DEXA). A foreign object is defined as a fragment of material with different X-ray attenuation properties than those belonging to the food product. A novel thickness correction model is introduced as a pre-processing technique for DEXA data. The aim of the model is to homogenize regions in the image that belong to the food product and enhance contrast where the foreign object is present. In this way, the segmentation of the foreign object is more robust to noise and lack of contrast. The proposed methodology was applied to a dataset of 488 samples of meat products. The samples were acquired from a conveyor belt in a food processing factory. Approximately 60\% of the samples contain foreign objects of different types and sizes, while the rest of the samples are void of foreign objects. The results show that samples without foreign objects are correctly identified in 97% of cases, the overall accuracy of foreign object detection reaches 95%.
Parallel-beam X-ray CT datasets of apples with internal defects and label balancing for machine learning
Dec 24, 2020

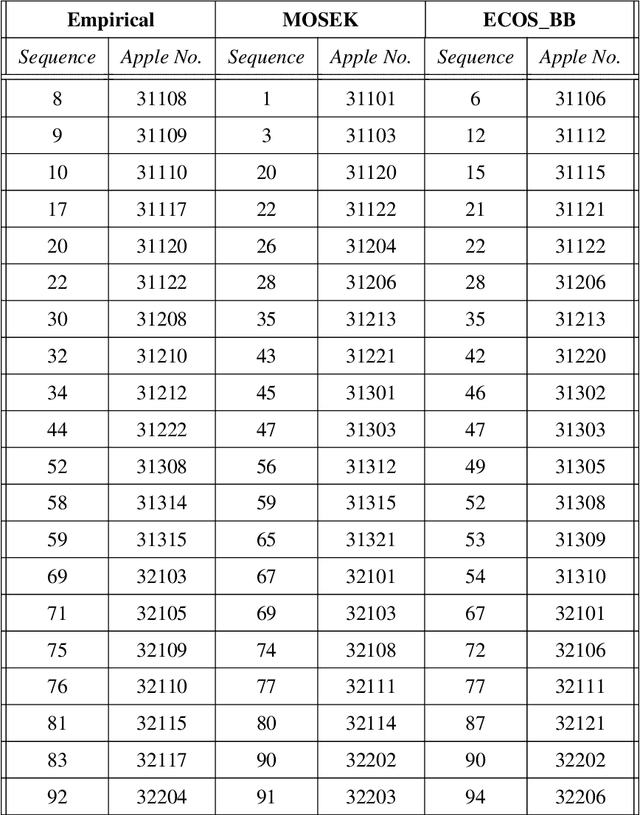

We present three parallel-beam tomographic datasets of 94 apples with internal defects along with defect label files. The datasets are prepared for development and testing of data-driven, learning-based image reconstruction, segmentation and post-processing methods. The three versions are a noiseless simulation; simulation with added Gaussian noise, and with scattering noise. The datasets are based on real 3D X-ray CT data and their subsequent volume reconstructions. The ground truth images, based on the volume reconstructions, are also available through this project. Apples contain various defects, which naturally introduce a label bias. We tackle this by formulating the bias as an optimization problem. In addition, we demonstrate solving this problem with two methods: a simple heuristic algorithm and through mixed integer quadratic programming. This ensures the datasets can be split into test, training or validation subsets with the label bias eliminated. Therefore the datasets can be used for image reconstruction, segmentation, automatic defect detection, and testing the effects of (as well as applying new methodologies for removing) label bias in machine learning.
Deep data compression for approximate ultrasonic image formation
Sep 04, 2020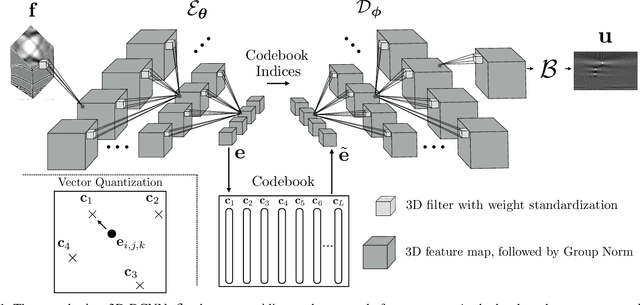
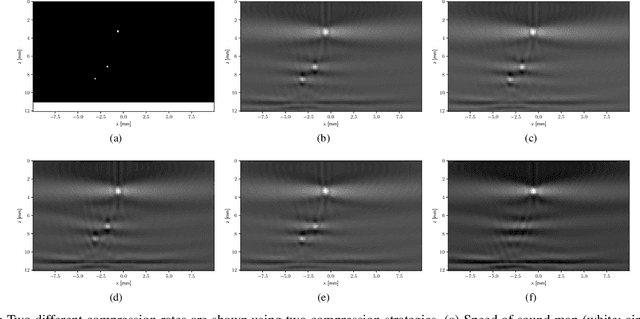
In many ultrasonic imaging systems, data acquisition and image formation are performed on separate computing devices. Data transmission is becoming a bottleneck, thus, efficient data compression is essential. Compression rates can be improved by considering the fact that many image formation methods rely on approximations of wave-matter interactions, and only use the corresponding part of the data. Tailored data compression could exploit this, but extracting the useful part of the data efficiently is not always trivial. In this work, we tackle this problem using deep neural networks, optimized to preserve the image quality of a particular image formation method. The Delay-And-Sum (DAS) algorithm is examined which is used in reflectivity-based ultrasonic imaging. We propose a novel encoder-decoder architecture with vector quantization and formulate image formation as a network layer for end-to-end training. Experiments demonstrate that our proposed data compression tailored for a specific image formation method obtains significantly better results as opposed to compression agnostic to subsequent imaging. We maintain high image quality at much higher compression rates than the theoretical lossless compression rate derived from the rank of the linear imaging operator. This demonstrates the great potential of deep ultrasonic data compression tailored for a specific image formation method.
Fast ultrasonic imaging using end-to-end deep learning
Sep 04, 2020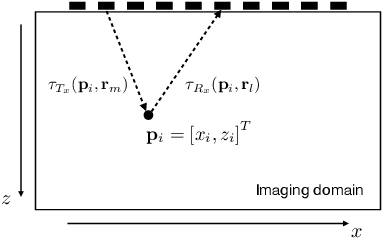
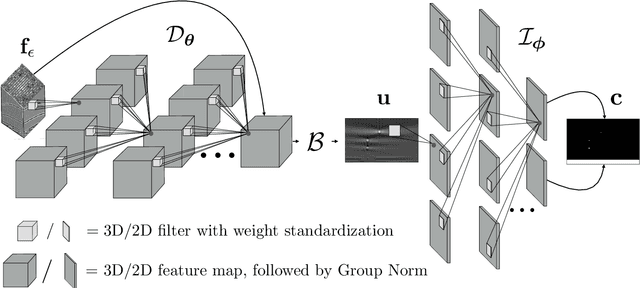
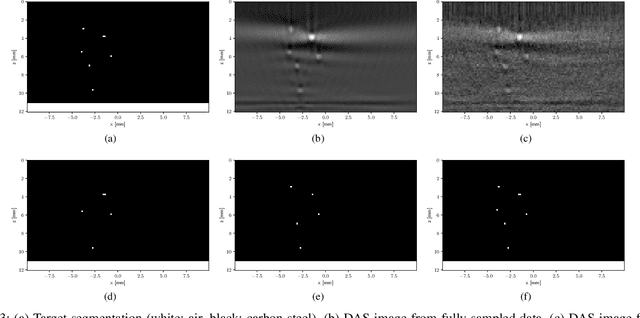
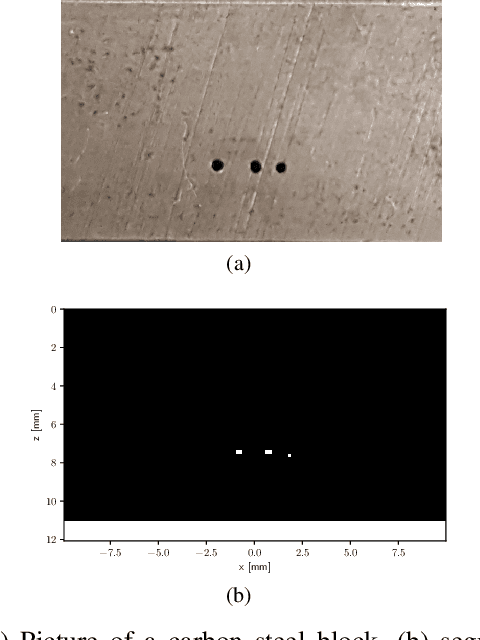
Ultrasonic imaging algorithms used in many clinical and industrial applications consist of three steps: A data pre-processing, an image formation and an image post-processing step. For efficiency, image formation often relies on an approximation of the underlying wave physics. A prominent example is the Delay-And-Sum (DAS) algorithm used in reflectivity-based ultrasonic imaging. Recently, deep neural networks (DNNs) are being used for the data pre-processing and the image post-processing steps separately. In this work, we propose a novel deep learning architecture that integrates all three steps to enable end-to-end training. We examine turning the DAS image formation method into a network layer that connects data pre-processing layers with image post-processing layers that perform segmentation. We demonstrate that this integrated approach clearly outperforms sequential approaches that are trained separately. While network training and evaluation is performed only on simulated data, we also showcase the potential of our approach on real data from a non-destructive testing scenario.